

This blog post was co-authored by Claus Matzinger, Stephanie Visser and Martin Tirion.
Introduction
In this blog post, we want to share a Microsoft manufacturing customer’s journey that started off by setting up with them the core piece for their software development: a monolithic repository — or monorepo for short.
Stay in control
Many industrial processes aim to avoid losing control of what goes where, when, and by whom. Not only will that reduce risk (liability, injuries, …) but processes also keep everything manageable despite evolving workforce, requirements, laws, etc. They want to stay in control. Software processes want to provide the same qualities:
- Requirements definition
- Requirements validation
- Requirements tracing from definition to test
- Requirement verification (aka tests)
- Maintainability
- Current status
To help all people involved in these kinds of project to work together an easy way to perform tasks in such an environment is important. A monorepo is a way to make this happen.
Monorepo or Multirepo?
While repositories are used by a lot of software engineers, many like the clean one-repo-per-project approach. Those projects typically focus on a single application, spreading any related material (e.g. documentation) across several other repositories or services within the same organization. This is called a multiple repository (multirepo for short) approach. A monorepo approach stores everything related to a project in a single repository.
Large undertakings can follow a multirepo approach but will soon realize just how much upkeep is required with policies and knowledge sharing. Also, writing code is somewhat opinionated about things like operating system, editor, and how much whitespace is the standard. Keeping a reasonably uniform standard across 100 repositories is a challenge!
|
Multi repositories |
|
| Pro | Con |
| One repo per module | One view of the complete system is hard to get |
| Security per repo | Tedious stakeholder management |
| Pipeline per repo – makes it fast | Changes might require updates in multiple repos |
The monorepo excels in forcing everybody to collaborate on the same terms. It allows participants to see the big picture, find documentation, or participate in discussions outside of their teams. Also, it’s much easier to enforce the same standards for each project — be it pipelines, editor configs, or whitespace; all of which lead to increased familiarity and a shared sense of responsibility.
Obviously, this approach is not without downsides.
| Mono repository | |
| Pro | Con |
| Complete view of the entire system | Grows very large (in size and complexity) |
| Easy to watch and manage | Discipline and processes are required |
| Uniform standards across projects | Tedious access management |
| Easy dependency management | |
However, these can be tackled with everybody’s favorite things: processes. In a monorepo, it’s not a single team determining how code is written, documented, or stored — it’s all teams agreeing on a common standard. This standard (e.g. which libraries to use) is then enforced and controlled by two large measures: automation and peer reviews.
Automation provides a consistent, predictable ruleset that is applied wherever necessary to approve code contributions, build deployable packages, and run tests. On a repository service such as Azure DevOps or Github, that means creating pipelines or actions and bots to consistently produce high quality contributions. Wherever doable, automate processes so developers can focus on solving business problems without worrying about doing it wrong.
Azure DevOps and Github provide ways to prohibit unapproved code from merging, so making pipeline runs mandatory is essential to keep the quality high. Branching policies protect mainline branches from direct edits.
Peer reviews are not only an integral part of the fork-merge workflow, but also provide opportunity to learn and improve for all participants. Most current git platforms provide a “merge/pull request” interface that allows looking at and commenting on the included changes. However, this requires discipline and time, so managers have to allow for each team member to participate.
As a developer, pull/merge requests are a great way to make sure you didn’t miss anything and to learn about alternative solutions to yours. Embrace the feedback!
In general, a monorepo is a place for large-scale collaboration, which means that it’s important to be disciplined and uphold processes (and adjust them) so others can do the same. Governance of these processes has to be delegated largely to the developers since they should want to follow and enforce them, since it’s the place the come to work to every day — and would you enjoy coming to a messy workplace each day?
The monorepo in practice
A few months ago, we started implementing a monorepo strategy at a large customer engagement with a project team of around 100 people. Skills were various when the project started – some where very experience with the processes, programming language and used technologies, where others needed lots of onboarding to some or all of these components. The core work was done by a team of around 8-10 software engineers.
The transition from more than 10 individual repositories to a single one took several weeks to fully complete since everyone was now responsible for upholding the processes. For this to succeed each participant had to be clear on the goal, the procedures, and how to change them.
In order to prevent a chaotic monorepo, the team produced guidelines, documentation, and a few demos on what goes where — but most importantly the design tried to make it really obvious by keeping the top-level directories simple:
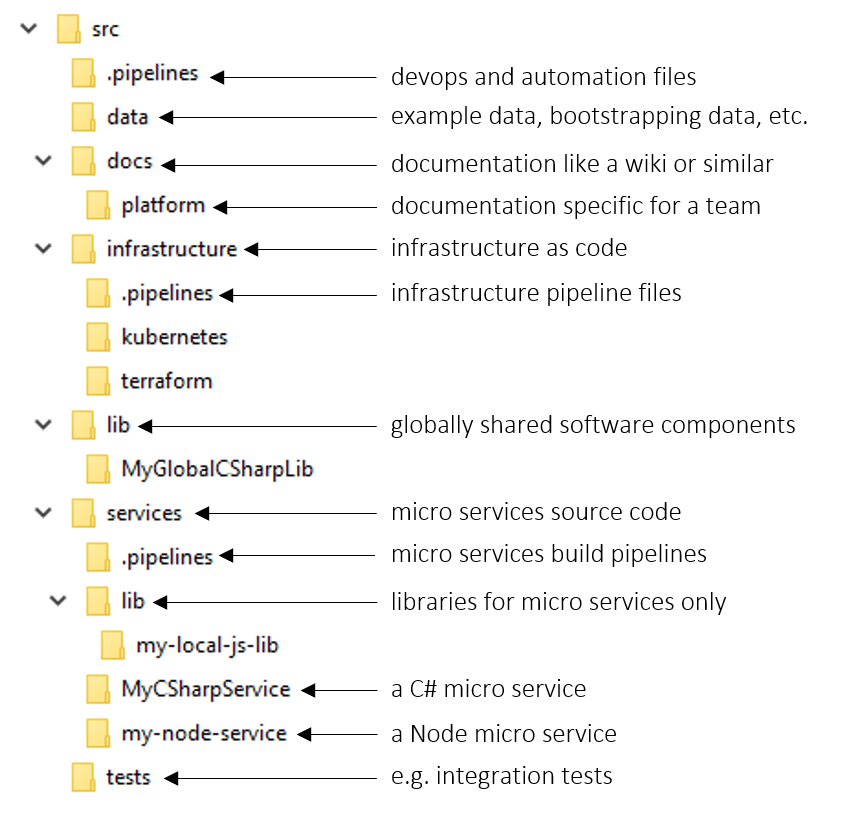
By keeping the topmost folders clearly named and simple, without any special naming the folders should remain meaningful even if the project matured over years and thousands of developer hours. At the same time any developer is empowered to pick the right place for their code. To make sure to get the most of a monorepo, follow these four principles:
- Scopes: The folders act as scopes to make sure code artifacts are only visible when they should be. This allows to extract common tasks (e.g. building a C# solution) quickly and maintainers can easier reason about where the error lies.
- One ancestor: Version control (especially Git) builds a hierarchical representation of the code and its changes. Therefore, specialized versions (e.g. a custom fix for a unique problem) can be maintained much easier as change sets are compatible.
- Big pictures: With everything in one place there is no need to copy code between repositories or to look for infrastructure as code files and documentation.
- Good practice: A monorepo requires teams to work with each other. By merging code only with a pull request (PRs), teams review each other’s code which breaks silos and improves code quality.
With a basic folder structure available, let’s go over how to work with it.
The process
In terms of meetings, most are familiar with Scrum‘s ritualistic ways: standups, reviews, planning, retrospectives, etc. If done well, each sprint should yield a deployable service. So how can a monorepo support that? As a basic setup, the choice for this project was made to have two main branches, following the GitFlow approach:
- main: This branch shows what currently is running in production
- develop: The latest and greatest features currently deployed in a testing environment
None of these two branches can be modified directly, but they can only be updated via pull requests. A quick overview can be found in the following image:
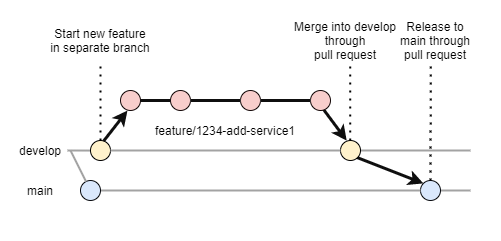
Releasing a new version then becomes a matter of merging dev with main, with automation doing the roll-out. Consequently, the production environment can be sealed off so nothing unexpected can be deployed there.
In Azure DevOps, use branching policy to prohibit direct access to these branches. Set up DevOps pipelines to create immutable, repeatable, and tested deployments and identify them by the latest commit hash or (Git) tag.
Clearly, computers are much better at following check lists and running through tasks, which is why a monorepo needs automation.
Automation
Automating tasks is a core requirement for monorepos. Everybody makes mistakes and those mistakes are costly to clean up, so minimizing the chances for errors prevents lots of time (hours, days or sometimes even weeks) lost in solving dependency problems or bugs causing a complete system to stop working.
Many repositories services allow using pipelines (or something similar) to automate steps like build, test, checking for style or best practices, and anything that can be done with an API. This has two major upsides:
- The process can be tested and verified
- No interaction required
Monorepos have to use these pipelines to do the following:
- Run build and test (CI) before enabling a merge into the dev/main branches
- One-click deployments of the entire system from scratch
Additionally, many things can be automated — but it’s important to be able to trust the oucome as a developer. The trade-off is that sophisticated pipelines make “quick and dirty” local builds much more difficult. Consequently the teams have to be able to change the processes as needed.
Automated interdependencies make it almost impossible to quickly fix a problem or try out something within the codebase.
File and repository sizes
Since the repository will grow very large, a full clone takes a long time, which is inefficient if you only need a small part. Similarly, Git is not very good with binary files (images, PowerBI reports, …) and those will significantly grow the repository. In order to prevent bloating the monorepo, there are two solutions that most repository services support:
- Git’s large file system (LFS) which diverts files by extension to a blob store, replacing it by a reference in the repo
- Git’s virtual file system (VFS) provides a per-folder clone
We chose to use Git LFS, which is doing the job in most cases. A discussion on that topic is for another post.
Conclusion
Software development is very opinionated on almost all matters, but especially how to work. A monorepo therefore poses a challenge to convince engineers to trust that other engineers are doing the right thing too and for that it needs proper governance. Once established however, these processes improve software quality and maintainability when required.
When does it pay off to convince everybody to adapt to new processes? We have found the following cases to improve significantly with a monorepo:
- The software consists of many linked but independent components
- Teams have end-to-end ownership of one or more such components
- The system is always deployed together
Since a monorepo requires more tools and processes to work well in the long run, bigger teams are better suited to implement and maintain them. Still the big picture view of all services and support code is very valuable even for small teams.
Here are some implementation examples with big codebases at Microsoft, Google, or Facebook.