
Background
Entity disambiguation or resolving misspelled/ambiguous tokens has always been an interesting subject with its own challenges. With the rise of digital assistant devices such as Microsoft Cortana, Google Home, Amazon Alexa etc., the overall accuracy of the device has become important. The communication quality with a device contains the capability to understand human’s intent, distinguishing correct entities with their correct spelling form and finally fulfilling the human’s request with an appropriate response. Similarly, with the challenges in optical character recognition (OCR) results the best recognition results can only be achieved if the source image is of decent quality.
Challenges and Objectives
A common challenge when mapping an entity name from a document (electronic or scanned), a written or a transcribed spoken sentence to its canonical form in a system of record, is in handling variations in spelling, spelling mistakes, errors due to OCR transcription of a poor-quality scan, or differences in entity form between a transcription of speech to the canonical form. These variations require sub-token matching, word breaking or collation of sib-tokens to increase the likelihood of matching when searching for the most relevant canonical form of the entity.
Having misspelled entities means we may not be able to fulfill the initial speech request. Therefore, either we should resolve the misspelled entities to their correct form, before attempting to query a data source or we should prepare the target data source to fulfill the queries with misspelled entities with a higher accuracy rate.
Solution
This document proposes a methodology to disambiguate misspelled entities by comparing the search retrieval performance with different custom search analyzers in a search engine. Hence, even if the query provided contains some misspelled entities, the search engine can respond to the request with higher precision and recall than the default settings. This method can be applied to any search engine service capable of adding custom search analyzers.
In this document we experiment with a speech-to-text scenario. Similar approaches can be applied to OCR and any machine entity extraction system. The implemented solution can be found in EntityDisambiguation repository.
Architecture deep-dive
In this section, we will discuss the motivation behind the proposed solution. Consider a speech-to-text scenario where a user is interacting with a device and asking to make a phone call. The figure below indicates the overall architecture from the user speech, to searching the data source and responding to the user’s request.
User: Hey device, call “Jean Heng”
Device: Sorry I cannot find “John Hang”
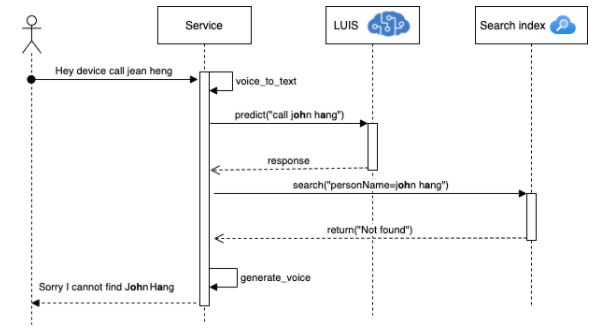
The speech is converted to text and then it will be sent to a natural language understanding service such as LUIS. We assume that our LUIS (Language Understanding Intelligent Service) model is trained well, and we will expect that it can identify the intent and extract the entities. It can identify that “call Jean Heng” is a “call” intent with an accuracy score of 0.88. It also can identify that “Jean Heng” part of this query is a “personName”. However, when we query the search engine for “Jean Heng”, it’s possible to miss to retrieve this record from the data source since what exists in the search index is “John Hang” and not “Jean Heng”.
{
"query": "call jean hang",
"topScoringIntent": {
"intent": "Call",
"score": 0.8851808
},
"intents": [
{
"intent": "Call",
"score": 0.8851808
},
{
"intent": "None",
"score": 0.07000262
}
],
"entities": [
{
"entity": "jean heng",
"type": "builtin.personName",
"startIndex": 5,
"endIndex": 13
}
]
}
Sample response from LUIS. Intent can be identified with high confidence (0.88) and the entity is a personName. However, as the name is misspelled, when we query our DataSource (search engine) the name cannot be found.
Methodology
This section presents an overview of the proposed methodology to improve the research retrieval for misspelled entities namely personName. Different search analyzers benefit from different tokenizers and token filters. A tokenizer divides the continuous text into a sequence of tokens, such as breaking a sentence into words and a token filter is used to filter out or modify the tokens generated by a tokenizer. Hence, different search analyzers may behave differently, and their performance may vary to misspelled person’s names. Our approach is to measure the performance of the search engine in the retrieval of the misspelled person’s name when the search engine uses specific or multi-search analyzers. We begin by creating a search index using different search analyzers. Then we will ingest the person’s name into the created search index.
Analysis of the Search Index Schema
In this section we will be creating a search schema for our search index. We first started by identifying several search analyzers. Then we will identify the fields of the search index needed in this experiment.
Analyzers
An analyzer is a component of the full- text search engine responsible for processing text in query strings and indexed documents. Different analyzers manipulate text in diverse ways depending on the scenario. By default, Azure search uses Standard Lucene for both parsing the records/documents as well as parsing a query. We will be creating several custom search analyzers that we think may be the best candidates for the experiment.
In the next section, we will run our experiments by sending a query to the search index for all the combinations of the created search analyzers to verify which analyzer can improve the name retrieval. Most of the custom analyzers benefit from case-folding to resolve similar terms that have different case folding. Additionally, they use ASCI folding to convert numeric, alphabetic and symbolic Unicode characters to ASCII representation of that token. Analyze REST API can be used to verify how each analyzer analyzes text. In this document, we chose `Person Name` as our experimented entity and we are creating Search Analyzers in the subsequent section.
In our experiment we used the following search analyzers: Phonetic, Edge-N-Gram, Microsoft, Letter, CamelCase, URL-Email and default Analyzer (Standard Lucene).
Search Index Fields
Now that we have created our search analyzers, we will create our search index. We will be adding several fields, each of them corresponding to a search analyzer. The following table represents the fields added to the search index.
| Field | Analyzer |
| phonetic | phonetic-analyzer |
| edge_n_gram | edge-n-gram-analyzer |
| microsoft | En.microsoft |
| letter | letter-analyzer |
| ngram | ngram-analyzer |
| camelcase | camel-case-pattern-analyzer |
| stemming | stemming-analyzer |
| url_email | url-email-analyzer |
| standard_lucene | standard.lucene |
Data Ingestion
We used the midterm election candidates search results dataset and ingested 400 names into the search index. For every record, a name was added to every field. However, for every field we specified a different analyzer. The JSON (Java Script Object Notation) shown below is result of a search to the search index with the query: “Jean Heng”. The data ingested into the search index will be used in the next section to verify the search retrieval precision and recall for different analyzers.
{
"@search.score": 4.589165,
"stndard_lucene": "Jean Heng",
"phonetic": "Jean Heng",
"edge_n_gram": "Jean Heng",
"letter": "Jean Heng",
"ngram": "Jean Heng",
"camelcase": "Jean Heng",
"steming": "Jean Heng",
"url_email": "Jean Heng",
"text_microsoft": "Jean Heng"
}
Experiment
In the previous section, we created a search index with 400 names in the index. In this section, we will run some experiments to measure the highest performing analyzer(s) for the name field. We can hopefully improve the search retrieval, even for misspelled names such as “John Hang” we should be able to retrieve “Jean Heng” from the search engine.
Measuring the retrieval performance
To measure the search accuracy, we need to know how the search engine can retrieve a search result if a misspelled name is passed as a query; it is important for us that the retrieved result is accurate. The following table contains the confusion matrix measures we will need to calculate the search performance.
| TP | True Positive | Given a misspelled name is searched,
a name is found and it matches the expected name. |
| FP | False Positive | Given a misspelled name is searched,
a name is found but it does not match the expected name. |
| TN | True Negative | Given a non-existent name is searched, no name is found. |
| FN | False Negative | Given a misspelled name is searched, no name is found. |
With TP, FP, TN and FN defined, we can calculate both recall and precision using the following formulas:

Since both precision and recall are crucial factors of the search retrieval, we will be using the F1 score which takes both precision and recall measures into account. The F1 score is the harmonic meaning of the precision and recall, where an F1 score reaches its best value at 1 (perfect precision and recall) and worst at 0. The following formula is how we calculate the F1 score.

Misspelled Names and Expected Names
In the previous section, we ingested 400 names into our search engine. In this section, we will create a dataset having 450 {misspelled, expected} tuples. The first 400 tuples corresponded to those existing in our search index. The last 50 tuples do not exist in our search index and will be used to have impact on TN (true negative) measures of the experiment.
Generate Misspelled Names
The most accurate method to generate misspelled names is to use telemetry data19 from the system you are working with. For instance, find what was not correctly spelled in the logs and capturing them to be used for the experiment. If you do not have access to telemetry data to create misspelled names, you can use the Azure speech-to-text API. The following algorithm illustrates a flowchart on how to generate a dataset of misspelled and expected names from a corpus of the names using speech to text API.
Begin
misspelled_nams empty list
expected_names empty list
names names_corpus
While more data is needed for the experiment, do
Call speech API providing a name from names
If the response from API is equal to the correct name
Continue
Else
Insert misspelled name into misspelled_nams
Insert correct name into expected_names
End
Finally, we will make a dataset of names, like in the table below, where the first 400 records in the expected name column are ingested into Azure Search (as discussed in the previous section).
| # | Expected name | Misspelled name |
| 1 | Tobye Schimpke | tobe shimpok |
| 2 | Sidney McElree | Sidney Mc. Elree |
| … | ||
| 400 | Kimmie Fridlington | Kim Fridlington |
| 401 | NOT_FOUND | Netta Niezen |
| … | ||
| 450 | NOT_FOUND | Aluin Donnett |
Feature Selection
Having 9 different fields, each of them using different analyzers without considering the empty set, we will have 511 combinations of the fields to query against in our experiment. We also have 400 documents in our search engine. To cover all possible scenarios, we should make 400 × 511 = 204,400 calls to the Azure Search. We can also use one of the feature elimination techniques [5] to speed up experiment execution time. For instance, we can run our experiment in several phases. In each phase, we will remove fields where their F1 score is significantly lower than in other fields. As we run our experiment, we will remove more subsets of the fields set. Using a superset of all the fields with 511 subsets, or any feature elimination technique, we will have a list of features with each element containing field(s) (e.g., features = [“ngram”, “phonetic, ngram”, ….”phonetic, ngram, stemming” … ]
F1 Scores Calculation
Having a dataset of `missplled_names`, `expected_names` (created in section 4.2.1) and a list of features (created in previous section), now we can calculate the F1 Score for each of those features. For every feature in the list of features and for every `misspelled_name` in our dataset, we will do the following steps:
- Send a query to our search index with the following payload:
{ "queryType": "full", "search": "MISSPELLED NAME", "searchFields": "FEATURE/S" } - Take the response having the most ranking and compare it against the corresponding `expected_name`
- Mark the result based on the following:
- TP: Some names were found, and it matches the expected name.
- FP: Some names were found but it does not match the expected name.
- TN: No names found and no expected name
- FN: No names were found but we were expected to find some names.
- Using the formula discussed in the previous section, calculate the precision, recall, and F1 for each feature.
Finally, for each feature, we will have a result like what is illustrated in the following schema consisting of different measures for the combination of different search analyzers.
{
"fn": 26,
"tp": 365,
"tn": 18,
"fp": 11,
"fields": "camelcase-url_email-text_microsoft",
"precision": 0.6206896551724138,
"recall": 0.9335038363171355,
"f1": 0.7456165238608637
}
Select the Best Analyzers
After running the experiments mentioned in the previous section, we selected feature(s) with the highest F1 score. If several features exist with a similar score, we can increase the number of test data for misspelled names and expected names. Then we can add those extra records into our Azure Search and run the experiment again. We can also decrease our features using a feature elimination method.
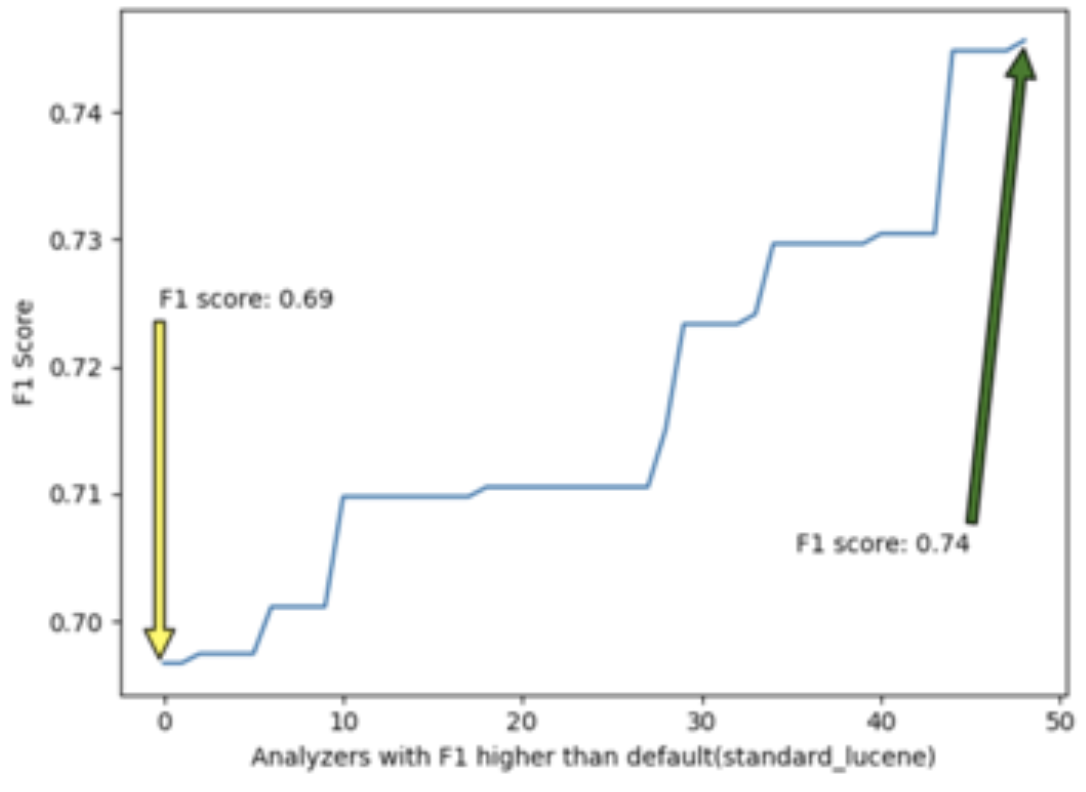
Comparing different F1 score results, we noticed that the F1 score for the combination of {”camelCase”, “url_email”, “microsoft”} has the highest number equal to 0.74, whereas if we rely on the default analyzer (stanadard_lucene), the F1 Score is equal to 0.69. Therefore, if we specify the search analyzers in the search query, we will approximately have a 5% improvement in the name retrieval from the search engine. Figure 17 illustrates the F1 score for 50 features of those 511 experimented, with the F1 score higher than the default analyzer in ascending order.
Summary
In this document we discussed how we can disambiguate misspelled entities using Azure Search. We discussed how we can use Microsoft LUIS to disambiguate entities from the intents, and how we can improve entity retrieval by experimenting with different search analyzers. Then we created a search index using nine search analyzers and ingested a dataset of people names into that index. We further executed the experiment by sending misspelled people names to the search index and based on the retrieval performance we have selected the highest performing search analyzers. Experimenting with different search analyzers we could specify the search analyzers with the best precision and recall.
Hence, we could improve the F1 score of the search retrieval by 5%.
This experiment was executed for person names. For any different field (e.g., address, city, country, etc.) a similar experiment should be executed to make sure analyzers with the highest performance are selected and will be used. Additionally, we can execute this experiment in conjunction with a spell check service such as Bing spell check to attempt to resolve misspelled entities even before calling the search service.
The Team
I would like to express my special thanks of gratitude to the amazing team who helped me through experiments, implementations of this method.
- Maysam Mokarian , mamokari@microsoft.com
- Mona Soliman Habib , Mona.Habib@microsoft.com
- Jit Ghosh , pghosh@microsoft.com
- Margaryta Ostapchuk , mostap@microsoft.com
- Eric Rozell
Resources:
[1] https://docs.microsoft.com/en-us/azure/search/index-add-custom-analyzers