

Miroculus is a startup developing a simple, quick and affordable blood test to diagnose cancer and other diseases at an early stage. Their test device can detect the existence of micro-RNAs (miRNAs) in the patient’s blood, which may correlate with a particular disease.
Miroculus developed the loom.bio tool that builds a visual graph according to the relations between Genes, miRNAs and Conditions, extracted from uncurated public articles (ie. Pubmed, PMC, etc.)
Microsoft and Miroculus collaborated to build a pipeline to process a corpus of medical documents. The pipeline is a generalized solution that extracts entities from the documents, finds whether a relation exists between them, then stores the derived relations in a database representing a graph.
The Problem
We wanted to build a corpus-to-graph pipeline that is:
- Reusable across different corpora and domains
- Scalable across different pipeline tasks
- Easily integrated with GitHub for continuous deployment
- Easily manageable
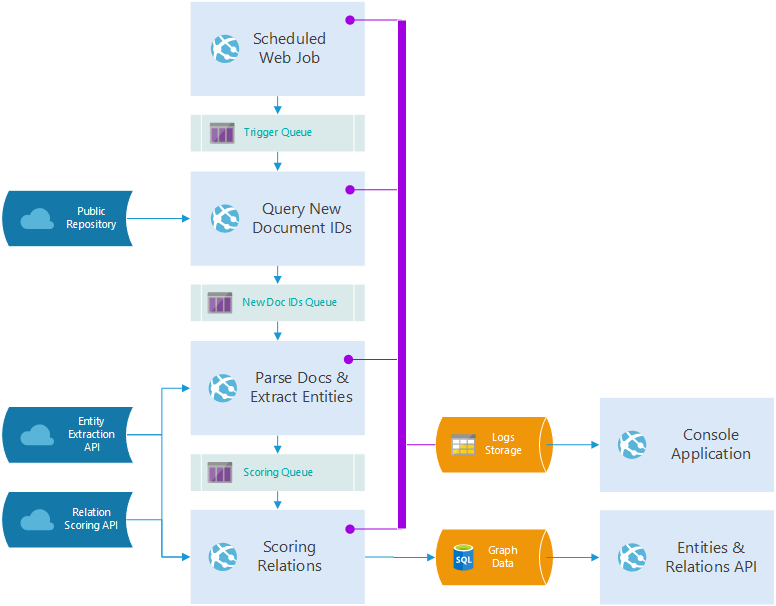
Design Architecture
Design Choices
For this project, we extract relationships between miRNAs and genes, based on the connections that we find in medical research documents available on PubMed and PMC.
To extract entity relations from a single document, we perform the following sequence:
- Split a document retrieved from the corpus into sentences
- Extract miRNA and gene entities from each sentence
- Use a binary classifier to discover relations between each pair of sentences and entities
- Create an entry in the Graph DB for each related entity pair. The entry includes entities, classification, score, and reference sentence.
We’ve developed a pipeline that uses a scheduled WebJob to periodically query for new documents in the corpus. This sequence is repeated for each document in the corpus.
Each job is implemented as an Azure App Service feature called WebJobs. Each WebJob listens to a queue, which represents the queue of job messages.
Azure Web Apps are easily integrated to GitHub, and using queues is a good practice for supporting scalability. Additionally, each WebJob, as part of Azure App Service, is scalable separately.
Domain-specific tasks were abstracted and represented as API calls, to keep the pipeline generic and reusable across different domains and corpora.
Next, we encountered two challenges:
- How would we associate each Web App with the right job, given that we don’t want to create separate repositories for each pipeline task?
- How do we manage and monitor the pipeline?
We used Pipeline Management to tackle the first challenge and Pipeline Deployment to answer the second one. The following sections detail how we addressed these challenges and integrated everything together into a holistic solution.
Pipeline Management
The web-cli is a great tool for controlling and monitoring your backend services and applications. In addition to the built-in plugins for common tasks, the web-cli is easily extendable with plugins. One particularly useful plugin is for logging that enables you to query logs captured by a WebJob.
In our pipeline implementation, we extended the web-cli to support administration actions like rescore or update model.
This approach can be used to provide the user with a one-stop tool for managing the pipeline.
Domain Abstraction
The pipeline supports two APIs that can be implemented according to a specific domain:
- Entity extraction API: splits documents into sentences and extracts relevant entities.
- Scoring API: detects relations between extracted entities.
We decided to separate these APIs from our pipeline for the following reasons:
- Both APIs implement domain-specific logic.
- Entity extraction and Scoring services use different technologies than those used in the pipeline.
- Defining an API for these services enables our solution to be configurable.
- Entity extraction and Scoring are processes that run on Linux, and we wanted to enable deployment of the pipeline to Azure App Services.
Pipeline Deployment
The pipeline includes 4 Node.js WebJobs, with common dependencies and logic as well as two websites for web-cli and Graph API.
We wanted to leverage the Continuous Deployment feature using WebJobs but didn’t want a separate repository for each pipeline role. Therefore, we figured out a way to deploy a single repository, with the implementation of all the pipeline’s roles having each WebJob determine its role in the pipeline.
Here is an example of how web job runners are created according to a received parameter: corpus-to-graph-pipeline/lib/runners/continuous.js
var roles = require('../roles');
/*...*/
function Runner(serviceName, config, options) {
// Initializing the relevant role accorindg to serviceName
var svc = new roles[serviceName](config, options);
// This method is called periodically to check for messages in the queue
function checkInputQueue() {
// Request a single message from the queue
queueIn.getSingleMessage(function (err, message) {
// Send message to be processed by the service
return svc.processMessage(msgObject, function (err) {
/*...*/
});
});
}
}
This is an example of how to start the runner with the relevant web job loaded from environment variables: corpus-to-graph-genomics/webjob/continuous/app.js
var continuousRunner = require('corpus-to-graph-pipeline').runners.continuous;
var webJobName = process.env.PIPELINE_ROLE;
/*...*/
function startContinuousRunner() {
var runnerInstance = new continuousRunner(webJobName, /*...*/);
return runnerInstance.start(function (err) {
/*...*/
});
}
Our solution uses a generic node module and a sample solution that leverages it.
- corpus-to-graph-pipeline – A node module that provides a common implementation of a pipeline.
- corpus-to-graph-genomics – A sample project that leverages the pipeline module. It can be used as is, or as a reference for how to build a solution for a different problem space.
Additionally, the solution comes with two ARM templates that bundle all the deployment dependencies together like SQL Server, Azure Storage, etc.
The scalable ARM template is designed to enable scalability in production. The all-in-one ARM template is designed for development and testing and is less taxing on resources.
Opportunities for Reuse
This solution can be reused in projects that require “corpus to graph” pipelines.
Developers can leverage this repository in fields such as medicine, knowledge management and genomics (similar to this project) or any other project requiring processing of a large-scale document repository into a graph.