

Why emotion detection?
Emotion Detection and Recognition from text is a recent field of research that is closely related to Sentiment Analysis. Sentiment Analysis aims to detect positive, neutral, or negative feelings from text, whereas Emotion Analysis aims to detect and recognize types of feelings through the expression of texts, such as anger, disgust, fear, happiness, sadness, and surprise. Emotion detection may have useful applications, such as:
- Gauging how happy our citizens are. Different indexes have different definitions; most evolve around economic, environmental, health, and social factors. Since the mid-2000s, Government and organizations around the world are paying increasing attention to the happiness index.
- The Happy Planet Index (HPI) (news, TED talk). This metric is defined as the overall index scores that rank countries based on their efficiency, as well as how many long and happy lives each country produces per unit of environmental output. This is unusual because the majority of indexes are based upon economic measures.
- Societal Wellbeing metrics. The UK government measures people’s wellbeing; their statistics can be found here. Other countries and cities such as Seattle, Dubai, and South Korea, have similar measures.
- Pervasive computing, to serve the individual better. This may include suggesting help when anxiety is detected through speech, or to check the tone of an email before sending it out.
- Understanding the consumer. Improving perception of a customer with the ultimate goal to increase brand reputation and sales.
How?
There are 6 emotion categories that are widely used to describe humans’ basic emotions, based on facial expression [1]: anger, disgust, fear, happiness, sadness and surprise. These are mainly associated with negative sentiment, with “Surprise” being the most ambiguous, as it can be associated with either positive or negative feelings. Interestingly, the number of basic human emotions has been recently “reduced”, or rather re-categorized, to just 4; happiness, sadness, fear/surprise, and anger/disgust [2]. It is surprising to many that we only have 4 basic emotions. For the sake of simplicity for this code story, we will use the more widely-used 6 emotions. (Other classifications of emotions can be found here.) The question remains, however, how much of an emotion we can convey via text? This is especially interesting since facial expression and voice intonation convey over 70% of the intended feelings in spoken language.
In any recognition task, the 3 most common approaches are rule-based, statistic-based and hybrid, and their use depends on factors such as availability of data, domain expertise, and domain specificity. In the case of sentiment analysis, this task can be tackled using lexicon-based methods, machine learning, or a concept-level approach [3]. Here, we are exploring how we can achieve this task via a machine learning approach, specifically using the deep learning technique.
Is It Possible?
One of the biggest challenges in determining emotion is the context-dependence of emotions within text. A phrase can have element of anger without using the word “anger” or any of its synonyms. For example, the phrase “Shut up!”. Another challenge is the difficulty that other components of NLP are facing, such as word-sense disambiguation and co-reference resolution. It is difficult to anticipate the success rate of machine learning approach without first trying.
Data:
Another challenge in emotion detection is the lack of a labelled emotion database to enable active innovation. Currently, few publicly accessible databases are available. The 2 most commonly used databases are ISEAR, which contains 2500 sentences, with 5 categories of emotions (it lacks “Surprise”). The SemEval 2007 [4] Affective Text database consists of 250 sentences annotated with 6 categories of emotions, with another 1000 sentences as test data. This database is primarily designed for exploration of the connection between lexical semantics and emotions. If we were to encourage progress in this area, a more comprehensive database with more observations may be required, especially if we are to tackle this task via a machine learning approach.
Text is extracted from a variety of sources as described below, and people can be crowd sourced to perform labelling using Mechanical Turk. A process, inspired by a DARPA [5,6] translation project, which is also crowd-sourced, is put in place to validate the accuracy of labelling.
Sources of text
Emotionally rich texts can be found on product reviews, personal blogs/journals, social network websites, forums, fiction excerpts, analysis, critiques, and more. Although many databases focus on reviews of a product or a type of service, sources of text may come from news articles, stock market analyses, or political debates; anywhere that people discuss and share their opinion freely could be a source.
Initially, texts from a variety of articles in this wide range of sources will be extracted. However, there is no guarantee that the text will provide a balanced mix of sentences with all the necessary categories of emotions. In other words, since not all sentences will contain emotional cues that we are interested in, it is highly possible the proportion of “neutral” sentences outweigh those with emotional elements. To understand the impact of this, sentences are passed into a sentiment analyzer to provide basic labels of “positive”, “neutral” or “negative”. This allows us to filter the set if necessary, and gives us a rough idea of the mix of sentences that we will be putting through to the Mechanical Turk for hand-labelling those sentences that convey emotions that we are looking for.
Mechanical Turk
The sentences (and/or phrases) obtained from the process described above need to be labelled with one of the emotions before they are deemed valid data. Hand-labelling is considered to be an expensive task, especially when human experts are involved.
Mechanical Turk (MT) is a relatively low-cost, highly-scalable method for performing tasks that require human intelligence, such as image labelling or creating language annotations. Recently, many have turned to Mechanical Turk to collect labels for numerous NLP tasks: word sense disambiguation, textual entailment, temporal ordering of events, question-and-answer, machine translation, topic modelling and more.
The benefits of the Mechanical Turk are:
- Low cost
- Fast
- Scalable
- Comparable quality to experts
So, looks like it is all red and rosy! Or is it? There must be more than meets the eye. Indeed, there is…
Quality Assurance
Quality assurance remains one of the most challenging issues. How is the quality compared to the experts? While ensuring the quality of data labelling using Mechanical Turk could be thought of as equal parts science and art, Callison-Burch [5,6] suggests some more concrete mechanisms to improve quality:
- Option to reject by the Requester.
- Redundancy. Allow each Human Intelligence Task (HIT) to be completed by several different Turkers, and only select higher quality ones.
- Ensure a minimum standard by putting in place a small test, before allowing actual labelling.
Designing HIT for quality control
A datum should consist of either a phrase or sentence, as well as a label of emotion. It’s possible to expand this to concepts spanning multiple sentences, but that is beyond the scope of this project.
There may be 2 ways to label the data:
Design 1: Turker can choose one of the following as the label for the phrase below.
“Stop it!”

Design 2: Turker may move the sliders of one or more emotions.
“Stop it!”

No doubt that Design 2 offers more information, however it comes with complication. Labels produced by Design 2 can be turned into distinct labels of single emotion, just like those produced by Design 1, but not vice versa. There is more incentive to go for Design 2. This will also open up a larger variety of approaches, even within the machine learning approach. Design 2 is likely to be the design, in order to offer more to what is already available.
Below are examples highlighting some complications in this task.
Example 1:
“Stop it! It’s tickly!”
Example 2:
“Stop it! It’s disgusting!”

Deep Learning Experiment
A multi-layered neural network with 3 hidden layers of 125, 25 and 5 neurons respectively, is used to tackle the task of learning to identify emotions from text using a bi-gram as the text feature representation. The settings for this experiment can be found in The Details section.
The performance metrics used here are the rates of recall, precision, accuracy (weighted and unweighted) and a confusion matrix. Recall is the ratio of correctly predicted instances of that class to the total number of instances that belong to that class. Precision is the ratio of correctly predicted instances of that class to the total number of instances predicted as that class. Weighted accuracy is computed by taking the average, over all the classes, of the fraction of correct predictions in this class (i.e. the number of correctly predicted instances in that class, divided by the total number of instances in that class). Unweighted accuracy is the fraction of instances predicted correctly (i.e. total correct predictions, divided by total instances). The distinction between these two measures is useful especially if there exist classes that are under-represented by the samples. Unweighted accuracy gives the same weight to each class, regardless of how many samples of that class the dataset contains. Weighted accuracy weights each class according to the number of samples that belong to that class in the dataset.
Data
The dataset used in this experiment consists of 784,349 samples of informal short English messages (i.e. a collection of English tweets), with 5 emotion classes: anger, sadness, fear, happiness, excitement where 60% is used for training, 20% for validation and 20% for testing. See here for more details about this dataset. The training and validation datasets are used for training the classifier and optimizing its parameters, while the test dataset (unseen to the model) is reserved for testing the model, to provide an indication of how good the trained model is. This is currently a private dataset.
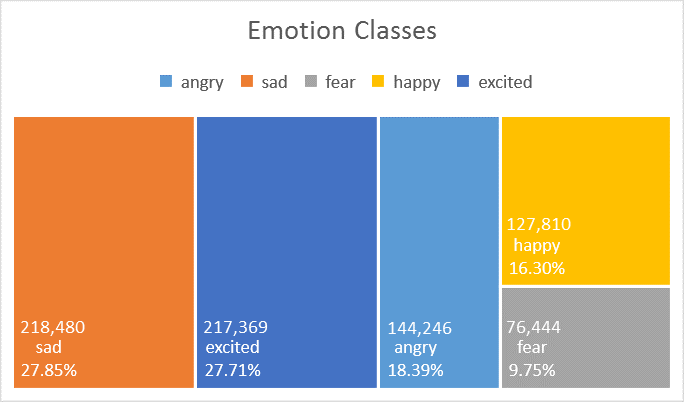
Results

The unweighted accuracy is 64.47% while the weighted accuracy is 60.60%. The confusion matrix above shows that this model can classify anger, sadness, and excitement well, but suffers when it comes to fear.
This is by no means the state-of-the-art solution to the problem. There are many ways one can improve the system. One important aspect to explore is the dataset itself. How would balancing the distribution of samples for each class (giving each class a similar number of samples) affect the overall performance? Does the specificity of the definition of an emotion class affect it? We could have two closely related emotion classes, say, ecstatic and excited as two separate classes, or afraid and scared as two separate classes, instead of one class with label excited and afraid, respectively. See here for related experiment.
Feature representation is the next stage in the process, and often plays a very important role in improving the accuracy of a classifier. Example representations include the use of skip-gram and n-gram, characters instead of words in a sentence, inclusion of a part-of-speech tag, or phrase structure tree. This experiment highlights comparisons of different n-grams in the case of emotion recognition from text.
Another interesting aspect is choosing a learner. Should one opt for a humble algorithm or an exotic one? It is almost counter-intuitive to think that a more sophisticated algorithm does not always outperform a relatively simple algorithm. This case study highlights an example of such a case, and this experiment illustrates the effect that the number of neurons and layers in a neural network has on an emotion classification task.
Discussions:
As the cost of database creation is reduced dramatically, what new tasks are made possible for us to solve next?
With the cost per label reduced, does that mean that MT is threatening the development of an unsupervised method? This is highly debatable. How about active learning? Does MT provide an inexpensive way to allow innovation in algorithm designs, experiment designs or even human computer interaction / human factors alike? Supervised machine learning is a data-driven research; how will this data annotation method transform these areas of study?
This has also unintentionally created a new type of meta data; profiles of Turkers. Will this new source of information drive culturally-specific research and innovative applications? Since it is cheap to create a database, that would also mean that multiple languages can be studied simultaneously. That itself would accelerate the advancement of NLP at a speed that has not yet been possible.
Quality assurance will probably be one of the most challenging issues. One interesting question exists; when the noise in the data increases with the size of the data, how can we use this fact to draw out insights from our algorithms? Will that help to push for robustness? How about attracting enough Turkers to complete our desired amount of HITs? How do we incent them? How do we calculate the optimum price that is attractive? How do we then hinder cheating behavior? How do we design a neat and clear HIT?

The Details:
Toolkit:
Microsoft internal machine learning toolkit.
Experiments settings:
| Learner type | Neural Network | |
| Number of output nodes | 5 | |
| Loss function | Cross entropy | |
| Hidden layer | 3 | |
| Number of nodes for each hidden layer | 5, 25, 125 | |
| Maximum number of training iterations | 100 | |
| Optimization Algorithm | Stochastic gradient descent | |
| Learning rate | 0.001 | |
| Early stopping rule | Loss in generality (stops when the score degrades 5 times in a row) | |
| Pre-training | True for 2 or more hidden layers | |
| Pre-trainer type | Greedy | |
| Pre-training epoch | 25 |
Full results:
Full results can be found at https://github.com/ryubidragonfire/Emotion
References:
- Paul Ekman. 1993. Facial expression and emotion. American Psychologist, 48(4), 384–392.
- Rachael E. Jack, Oliver G.B. Garrod, Philippe G. Schyns , “Dynamic Facial Expressions of Emotion Transmit an Evolving Hierarchy of Signals over Time.” Current Biology, Volume 24, Issue 2, p187–192, 20 January 2014.
- Walaa Medhat, Ahmed Hassan, and Hoda Korashy. “Sentiment Analysis Algorithms and Applications: A Survey.” Ain Shams Engineering Journal, issue 5, p1093-1113, 2014
- http://nlp.cs.swarthmore.edu/semeval/tasks/task14/description.shtml (referred on 15 Aug 2015)
- Callison-Burch, Chris. “Fast, cheap, and creative: evaluating translation quality using Amazon’s Mechanical Turk.” Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing: Volume 1-Volume 1. Association for Computational Linguistics, 2009.
- Callison-Burch, Chris, and Mark Dredze. “Creating speech and language data with Amazon’s Mechanical Turk.” Proceedings of the NAACL HLT 2010 Workshop on Creating Speech and Language Data with Amazon’s Mechanical Turk. Association for Computational Linguistics, 2010.