

Build agents you can trust across any framework with open evals and a control standard
We are four years into the generative AI era, and agents are everywhere. Enterprises are deploying them at scale, but trust has not kept pace. The gap is concrete: written policies do not translate into working runtime controls, evaluating agent safety across changing contexts is hard, and controls scattered across prompts, code, gateways, and frameworks make it risky to move from demo to production.
At Microsoft Build 2026, we are closing that gap. By the end of this post, you will be able to evaluate an agent against your own policies, place runtime controls at the exact checkpoints where it can fail, and monitor its behavior in production. You can start today, on any framework, with open source.
What’s new
Today we are announcing a new trust framework and a set of capabilities for developers building AI agents on any framework. It starts with two open-source projects that any developer can use regardless of their stack:
- ASSERT (Adaptive Spec-driven Scoring for Evaluation and Regression Testing), a policy-driven evaluation framework built on Microsoft Research.
- Agent Control Specification (ACS), a portable runtime control standard and part of the Agent Governance Toolkit, built for broad ecosystem adoption.
ASSERT: Open-source agent evaluation
Agents fail in ways that are hard to see. They drift from policy, produce unsafe outputs in edge cases, and behave differently in production than they did in testing. Generic benchmarks do not catch these failures because they are not built around your policies, your agent, or your use case.
ASSERT is Microsoft’s open-source framework for policy-driven agent evaluation, built on a proven Microsoft Research approach. ASSERT takes your organizational policies and requirements as input, systematically generates targeted evaluation scenarios, and surfaces safety and quality defects before they reach production.
ASSERT is:
- Requirements driven. ASSERT converts your policies into concrete, measurable evaluations, so rather than generic benchmarks you get context-specific test cases tailored to your agent’s intended behavior.
- Safety focused. ASSERT uses a systematization approach specifically validated for safety evaluation rather than quality alone, which distinguishes it from other evaluation tools that focus on quality metrics only.
- Open source, any framework. ASSERT works across LangChain, CrewAI, LiteLLM, OpenAI, and more. Because it is not tied to Microsoft Foundry, it is built for the 6 to 13 million generative AI developers building today.
- An integrated workflow. Run ASSERT to identify defects, apply controls, then re-run ASSERT to validate improvement, with before-and-after metrics telling a clear story. ASSERT is the developer’s starting point, giving you a way to understand what your agent is doing wrong before you try to fix it.
We are grateful to be launching ASSERT with support from partners who are already building with and validating this framework, including CrewAI, Arize AI, LiteLLM, Pipecat, and Pydantic. Their participation reflects a shared belief that agent evaluation needs to be open, policy-driven, and portable across the ecosystem.

My favorite thing about ASSERT is that the eval is easy to configure and reason about. I describe the behavior I care about in YAML, point it at a real agent, and get artifacts back. Not just pass/fail. They show why the judge made each call. That openness matters. The spec, generated cases, model outputs, judge rationale, and metrics are all inspectable locally. The eval feels auditable, not like a black box.
— Lorenze Jay Hernandez, Open Source Lead, CrewAI
Agent Control Specification: An open standard for agent safety controls
Knowing where your agent is failing is only half the problem. The other half is having a consistent, portable way to fix it, one that works across frameworks, travels with the agent, and does not lock you into any single vendor or infrastructure.
ACS is an open industry specification for placing deterministic safety and security controls at checkpoints throughout agentic workflows, and it is part of the Agent Governance Toolkit. Think of ACS as the MCP or A2A of agent safety. Just as Model Context Protocol (MCP) standardized how agents connect to tools and Agent2Agent (A2A) standardized how agents communicate with each other, ACS provides one open standard for safety controls that any framework can adopt, with Microsoft providing reference implementations for major platforms.
What ACS does
ACS:
- Defines five key validation checkpoints in an agent’s lifecycle, covering input, large language model (LLM), state, tool execution, and output.
- Enables deterministic control logic, including classifier endpoints, LLM judges, and custom content filters, placed exactly where you need them.
- Is expressed as standard policy YAML, making controls portable, versionable, and auditable.
- Works with any agent framework and is intentionally designed for industry-wide adoption.
ACS launches with a broad ecosystem of customers and partners spanning governance, security, observability, and framework categories. These partners have endorsed the specification and are building integrations and reference implementations.

- Customers: KPMG, Zscaler
- Partners: Arize AI, Aviatrix, BigSpin, CrewAI, Geordie, HoneyHive, IBM, Monte Carlo, Obsidian
Securing AI agents has been stuck between advisory system prompts and brittle per-framework code, and neither scales to the enterprise. Agent Control Specification (ACS) treats agent guardrails the way OpenInference treats traces: a portable, declarative contract enforced outside the model, reviewed once by security and applied everywhere. Every block, every human approval, and every state transition Agent Control Specification emits lands in Arize alongside the OpenInference trace that produced it, so policy and observability finally travel together.
— Aparna Dhinakaran, Co-founder & Chief Product Officer, Arize AI
Through our experience with Agent Control Specification, IBM has built AI agents for our clients that are not only innovative, but also secure, governed, and transparently compliant. Centralized agent controls give us the ability to consistently apply policies, monitor behavior, and ensure accountability across complex environments, so our clients can deploy agentic AI with confidence.
— Miha Kralj, Global CTO, IBM Consulting, Microsoft Practice
From policy to production confidence
ASSERT and ACS are designed to work together:
- Run ASSERT to identify where your agent is failing policy requirements.
- Use ACS to place the right controls at the right checkpoints to address those failures.
- Re-run ASSERT to confirm improvement.
It is a closed loop from evaluation to enforcement, and ACS gives developers a portable control layer that travels with the agent, not locked to any infrastructure or dependent on any single vendor.
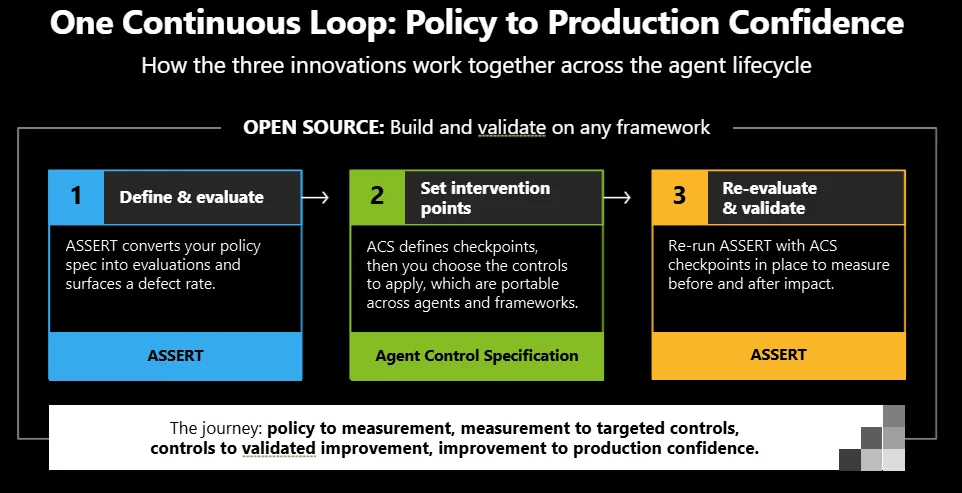
Together, these capabilities help developers move through a continuous trust lifecycle: identify risk, evaluate the agent, apply controls, observe behavior, and improve over time.
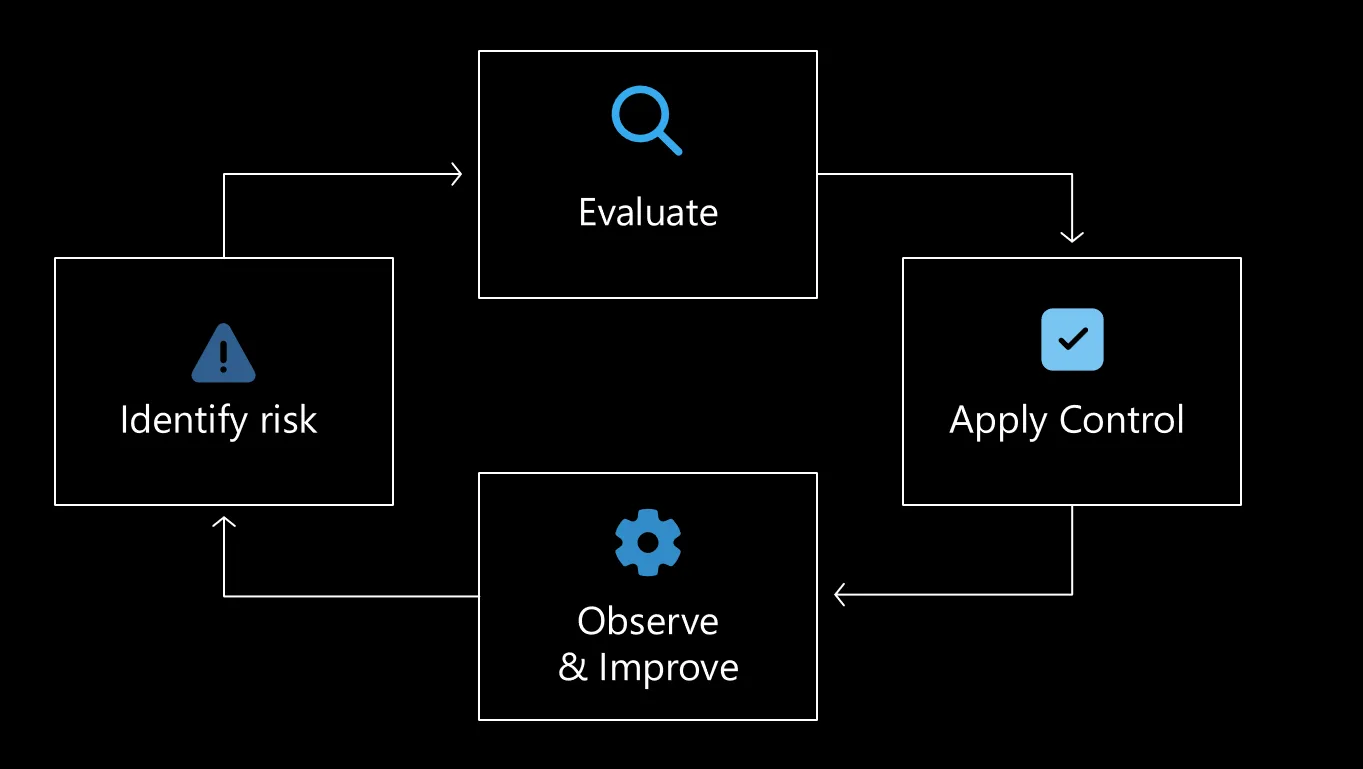
Continuous governance in Foundry: Guardrails recommended for your agent
Most teams know they need guardrails, but far fewer know which guardrails apply to their agent.
Guided Guardrail Setup in Foundry, now in public preview, gives developers personalized guardrail recommendations in minutes. A short questionnaire about your agent’s audience, data access, and use case surfaces the specific risks relevant to your scenario and recommends the right controls, including personally identifiable information (PII) filters, jailbreak protection, and task adherence, all with no security expertise required.
Learn more about guided guardrail setup in Foundry.
Most teams know they need guardrails, but far fewer know which guardrails apply to their agent. Guided Guardrail Setup closes that gap by translating your agent’s actual context into a concrete configuration you can ship with confidence.
Continuous observability in Foundry: See, evaluate, and improve agent behavior at every stage
Shipping an agent is the beginning, not the end. Keeping agents accurate, safe, and aligned with users requires the ability to see, evaluate, and improve behavior across the full lifecycle.
This spring marked a major milestone: tracing and evaluations in Foundry reached general availability, delivering production-ready visibility into agent behavior, with hosted agents coming soon. At Build 2026, we are building on that foundation with a new wave of capabilities. Learn more about agent observability.
Rubric: Context-aware evaluation at scale
Rubric evaluator, now in public preview, is a new evaluator in Microsoft Foundry that automatically generates evaluation criteria based on your agent’s specific context.
Unlike static benchmarks, Rubric:
- Creates custom quality criteria from your agent definition and use case.
- Uses a two-step process to generate the rubric, then evaluate performance against it.
- Applies weighted dimensions for aggregate scoring, giving a more nuanced view of quality.
- Feeds directly into Agent Optimizer, using evaluation results to drive continuous improvement across traces, evaluations, and memory.
Rubric bridges development-time evaluation and production monitoring. Where ASSERT is your open-source, safety-focused tool for inner-loop development, Rubric is your Foundry-native evaluator for measuring and improving quality at scale in production.
Interoperability and core observability
Foundry observability is designed to integrate with your existing stack. These capabilities bring production-grade tracing and evaluation to any agent without requiring teams to change frameworks or workflows.
- Tracing and evaluations for any agent framework, now in public preview, brings Foundry’s production-grade tracing and evaluations to agents built on LangChain, Semantic Kernel, or any custom framework, so no team has to choose between their stack and their observability.
- Azure Developer CLI (AZD) observability developer experience, now in public preview, brings tracing, logging, and insights directly into the developer workflow. This reduces friction and helps teams diagnose and improve applications without leaving their development environment.
Tracing, evaluation, and optimization
These capabilities help teams evaluate real-world performance, surface issues earlier, and close the loop from production signals to better agents.
- Multi-turn evaluation, now in public preview, evaluates agent quality across full multi-step conversations, not just single responses, catching degradation and safety issues that only surface when context accumulates over time.
- User Simulation, now in public preview, automatically generates realistic multi-turn conversations and scenarios to evaluate how agents perform.
- Evaluations with intelligent sampling, now in public preview, automatically run evaluations against a curated sample of live production traces, using smart filtering to surface the most signal-rich interactions so quality monitoring happens continuously without the cost of evaluating every request.
- Traces to dataset, now in public preview, converts production traces into relevant structured evaluation datasets to improve offline test coverage.
- Trace replay and visualization, now in public preview, replays and visually steps through agent execution traces to understand exactly how outcomes are produced. This makes debugging faster, improves model behavior, and builds confidence in production AI systems.
- Agent Optimizer in Foundry Agent Service, now in private preview, runs Foundry’s full evaluation suite directly within Foundry AI Operations Service and feeds results into Foundry Optimizer, closing the loop from production signal to continuous improvement.
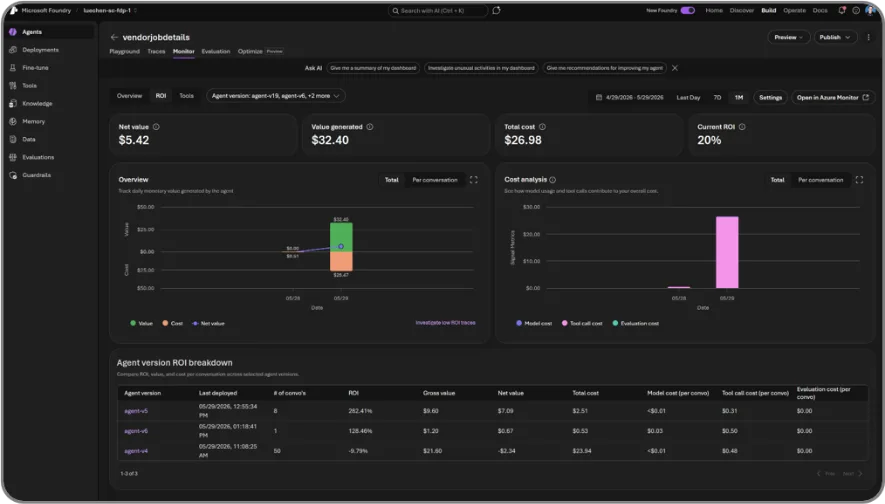
Business value
Knowing your agent works is critical, but so is proving that it delivers business value. We are introducing a new capability to help close that gap.
Return on investment (ROI) for agents in Microsoft Foundry, now in private preview, measures the real business impact of your agents, including task completion rates, time saved, and cost efficiency, giving stakeholders the data they need to justify investment and prioritize what to improve.
By combining evaluations and tracing capabilities in Microsoft Foundry with Azure Monitor, we transform AI into an enterprise-grade, production-ready system with built-in observability and continuous optimization — enabling ongoing evolution across the agent lifecycle and accelerating NTT DATA’s Smart AI Agent® vision.
— Yuji Shono, Head of the Global AI Office, NTT DATA Group Corporation
Security in Foundry: Developer-scoped data protection for agents
Evaluation and observability tell you how your agent is behaving. Security ensures every interaction adheres to your data protection policies, across prompts, responses, and tool calls. At Build 2026, Foundry brings Purview-grade data protection directly into the agent development experience, enabling real-time policy enforcement as agents are built and deployed.
- Runtime Data Loss Prevention (DLP) in Foundry, now in public preview, extends Microsoft Purview DLP into agent interactions, enabling real-time detection and blocking of sensitive data in prompts and across AI interaction flows within Foundry-built apps and agents. By bringing Purview enforcement directly into the developer workflow, teams building agents can apply data protection controls as they build, rather than relying solely on centralized policy rollout. Learn more about Purview for developers.
- Purview insights embedded directly into the Foundry Control Plane, now generally available, brings rich data security context to the place developers already work. Purview surfaces crucial signals, such as sensitive information types (SITs) detected in agentic interactions, the percentage of agentic interactions involving sensitive data, and the spread of high-risk users, in-line so Foundry admins can understand how AI apps and agents are built. This shift enables developers to make faster, better decisions in the moment, reducing rework and closing security gaps early on. For customers, the value is clear: stronger security by design and at enterprise scale, accelerated development cycles, and reduced risk of data leaks or compliance issues without slowing down innovation.
Together, these capabilities raise the bar for building safe agents, with built-in enforcement of data protection and policy at every interaction. Data protection moves into the inner loop, alongside evaluation, control, and observability, as a core part of building production agents.
Get started today
To learn more about ASSERT and ACS, check out these deeper-dive resources:
Join our open-source community:
Explore Microsoft Foundry documentation:
If you are attending Microsoft Build 2026, or watching on-demand content later, be sure to check out these sessions:
0 comments
Be the first to start the discussion.