
Whether you’re a machine learning practitioner, app developer, or just curious about the latest in AI, this guide shows how you can quickly boost image classification accuracy using cutting-edge Vision-Language Models (VLM) on Azure—no deep learning expertise required.
In this walkthrough, you’ll see how to fine-tune GPT-4o on Azure OpenAI for image classification using the Stanford Dogs dataset.

Illustrations of some of dogs’ breeds images presented on the dataset.
We’ll use the Vision Fine-Tuning API and compare the results to a lightweight CNN baseline, so you can see the impact of modern Vision-Language Models versus traditional approaches.
You’ll learn how to:
- Prepare your data
- Run batch inference
- Fine-tune the model
- Evaluate metrics
- Weigh cost and latency trade-offs
Want to try it yourself? All the scripts, notebooks, and experiment details are available in this GitHub repository so you can replicate or extend the project on your own.
Let’s dive in.
What Is Image Classification and Why Is It Useful?
Computer Vision has been a key field of Artificial Intelligence / Machine Learning (AI/ML) for decades. It enables many use-cases across various industries with tasks such as Optical Character Recognition (OCR) or image classification.
Let’s focus on image classification, it can enable filtering, routing, and you might already using it on your daily applications without noticing.
The backbone of these models has been heavily based on Convolutional Neural Network (CNN) architecture and has been there since 1998 (LeNet). Since 2017 and the arrival of Large Language Models (LLMs), the field of AI/ML has completely evolved, leveraging new capabilities and enabling plenty of exciting use-cases.
One of the latest capabilities of these models has been the introduction of vision (image / video) input in addition to text. This new type of Vision Language Model (VLM) like latest GPT-5 models from OpenAI, aims to not only generate text from an input but understand vision input to generate text.
This has democratized access to computer vision while achieving great performance as these models have been trained on a large corpus of data, covering plethora of topics. Now, anyone can access to a VLM via a consumer app (e.g., ChatGPT, Le Chat, Claude) or via an API, upload an image (e.g., a picture of your dog), type the task you want the model to perform (e.g., “what is the dog’s breed in the picture?”) and run it.
Getting Started: Choosing and Deploying Your Vision-Language Model on Azure
Azure AI Foundry lets you choose from thousands of models of any type (LLM, Embeddings, Voice) from our partners such as OpenAI, Mistral AI, Meta, Cohere, Hugging Face, etc.
In this post, we’ll select Azure OpenAI GPT-4o (2024-08-06 model version) as our base model. This is also one of the models which supports both:
- Azure OpenAI Batch API (batch inference for half the price)
- Azure OpenAI Vision Fine-Tuning API (teach base model to perform better or learn a new specific task)
We’ll first evaluate how behaves GPT-4o (base model) on our test set using the Batch API (for cost efficiency), then fine-tune it with the Vision Fine-Tuning API with the training and validation sets and compare metrics using the same test set.
Step 1: Run Cost-Effective Batch Inference with Azure OpenAI
Let’s measure performance of the GPT-4o on the Stanford Dogs Dataset. This dataset contains thousands of dogs’ images across 120 breeds. For the sake of cost management, we’ll down sampled this dataset and only keep 50 images per breed with the following split: 40 train / 5 validation / 5 test.
With the following ratio, our dataset contains:
- Train set (4,8k images)
- Validation set (600 images)
- Test set (600 images)
To send our requests to Batch API, we must format them in a strict JSONL format. Below is an example of a line within the JSONL:
{"model": “gpt-4o-batch”,
"messages": [
{"role": "system", "content":"Classify the following input image into one of the following categories: [Affenpinscher, Afghan Hound, ... , Yorkshire Terrier]." },
{"role": "user", "content":
[ {"type": "image_url", "image_url": {"url": "b64", "detail": "low"}} ]} ]}This JSONL contains:
- model deployment name (here a gpt-4o 2024-08-06 deployed for batch inference)
- system message (here is the image classification task described with list of potential breeds)
- user input (here is the dog’s image encoded in base64, with low detail resolution to be cost effective)
This JSONL intentionally doesn’t include the full list of parameters such as response_format. If you want to have more details, please have a look at the associated repository.
We’ve removed the actual dog’s breed (the output) as we want the model to run inference on these requests so then we can compare with each actual breed to evaluate its performance.
The Batch API has the benefit of processing your requests while being 50% cheaper than usual base inference, with the tradeoff of getting the model’s response within 24 hours. Please note that this is best effort and there is no guarantee from the Azure OpenAI Service that you can retrieve model’s response within 24 hours in 100% cases.
After having waited 15 minutes, the Batch API returned an output JSONL that contains for each line the model’s response.
Azure AI Foundry Batch job details.
Now, let’s extract the Batch API output response and compute the performance of the base model against the test set that will become our baseline.
Step 2: Fine-Tune GPT-4o for Your Images Using the Vision API
Fine-Tuning aims to post-train the model with new data that hasn’t been used during its initial training to make the model learn new knowledge, improve performance on certain tasks, or emphasis on a specific tone.

This process can lead to better performance, decreasing latency and may be cost-effective as you might send less tokens to the fine-tuned model to set its guidelines.
Azure OpenAI enables Fine-Tuning among different models and with different alignment techniques such as Supervised Fine-Tuning (SFT), Direct Preference Optimization (DPO) and Reinforced Fine-Tuning (RFT).
In 2024, we introduced Vision Fine-Tuning, that takes image and text as inputs and passes over following hyperparameters which you can control (epochs, batch size, learning rate multiplier, etc.).
Fine-tuning job pricing differs from base model inference due to couple of factors:
- total tokens used during training job (number of tokens in the train/validation datasets multiplied by number of epochs)
- endpoint hosting (priced per hour)
- inference (input/outputs tokens)
In the repo, we’ve taken a gpt-4o (2024-08-06 model version) and have constructed training and validation datasets in JSONL format. It follows supervised fine-tuning (SFT) technique where it uses input/output pairs to fine-tune the model.
Let’s have a look to a single line of the training set JSONL:
{"messages": [
{"role": "system", "content": "Classify the following input image into one of the following categories: [Affenpinscher, Afghan Hound, ... , Yorkshire Terrier]."},
{"role": "user", "content":
[{"type": "image_url", "image_url": {"url": "data:image/jpeg;base64,<encoded_springer_spaniel_image_in_base64>", "detail": "low"}}]},
{"role": "assistant", "content": "Springer Spaniel"}
]}Here we’ve selected the following hyper-parameters for fine-tuning:
- Batch size: 6 (how many examples are processed per training step)
- Learning rate: 0.5 (adjusts how quickly the model learns during training)
- Epochs: 2 (number of times the model trains on the entire dataset)
- Seed: 42 (ensures training results are reproducible when using the same settings)
See more on hyper-parameters recommendations here.
Once completed, the fine-tuning job returns a result file that contains data points such as training loss per step. These data points can also be viewed through the Azure AI Foundry portal (see below screenshots).
Azure AI Foundry Fine-Tuning job details
Azure AI Foundry Fine-Tuning job metrics
Step 3: Compare Against a Classic CNN Baseline
To provide another reference point, we trained a lightweight Convolutional Neural Network (CNN) on the same subset of the Stanford Dogs dataset used for the VLM experiments. This baseline is not meant to be state-of-the-art; its role is to show what a conventional, task-specific model can achieve with a relatively small architecture and limited training, compared to a large pre-trained Vision-Language Model.
This baseline reached a mean accuracy of 61.67% on the test set (see the Comparison section below for numbers alongside GPT-4o base and fine-tuned). It trained in less than 30 minutes and can easily run locally or in Azure Machine Learning.
Results at a Glance: Accuracy, Latency, and Cost
After having run our experimentations, let’s compare these 3 models (base VLM, fine-tuned VLM, lightweight CNN) on key metrics such as accuracy, latency and cost. Find below a table that consolidates these metrics.
| Aspect | Base gpt-4o (zero-shot) | Fine-Tuned gpt-4o | CNN Baseline |
| Mean accuracy (more is better) | 73.67% | 82.67% (+9.0 pp vs base) | 61.67% (-12.0 pp vs base) |
| Mean latency (less is better) | 1665ms | 1506ms (-9.6%) | — (not benchmarked here) |
| Cost (less is better) | Inference costs only $$ | Training + Hosting + Inference $$$ | Local infra $ |
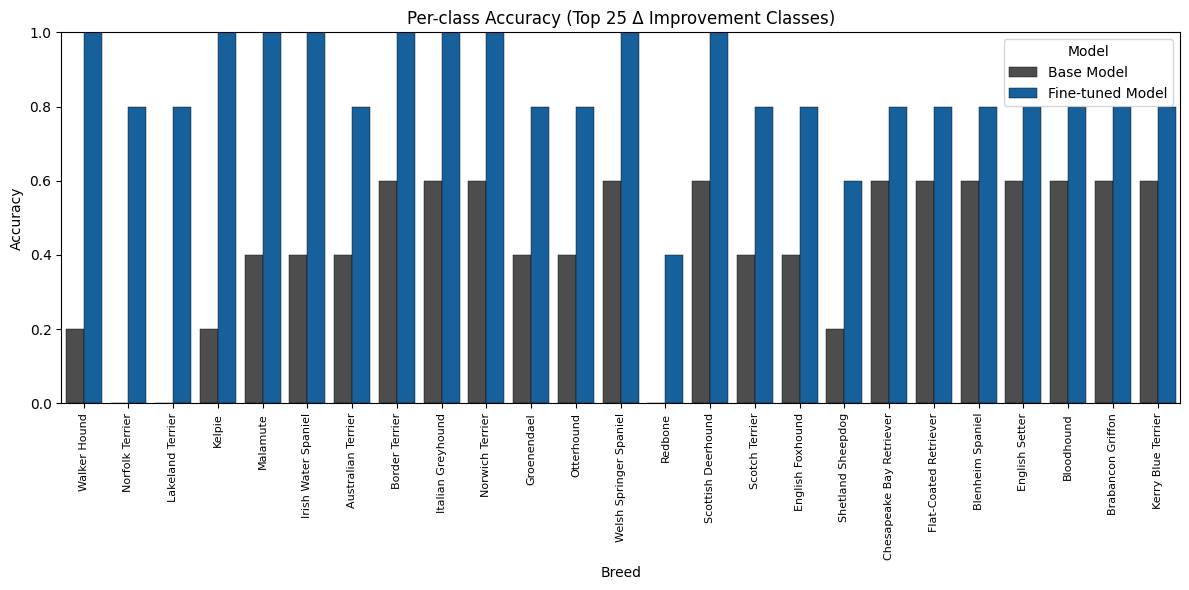
Accuracy
The fine-tuned GPT-4o model achieved a substantial boost in mean accuracy, reaching 82.67 % compared to 73.67 % for the zero-shot base model and 61.67 % for the lightweight CNN baseline.
This shows how even a small amount of domain-specific fine-tuning on Azure OpenAI can significantly close the gap to a specialized classifier.
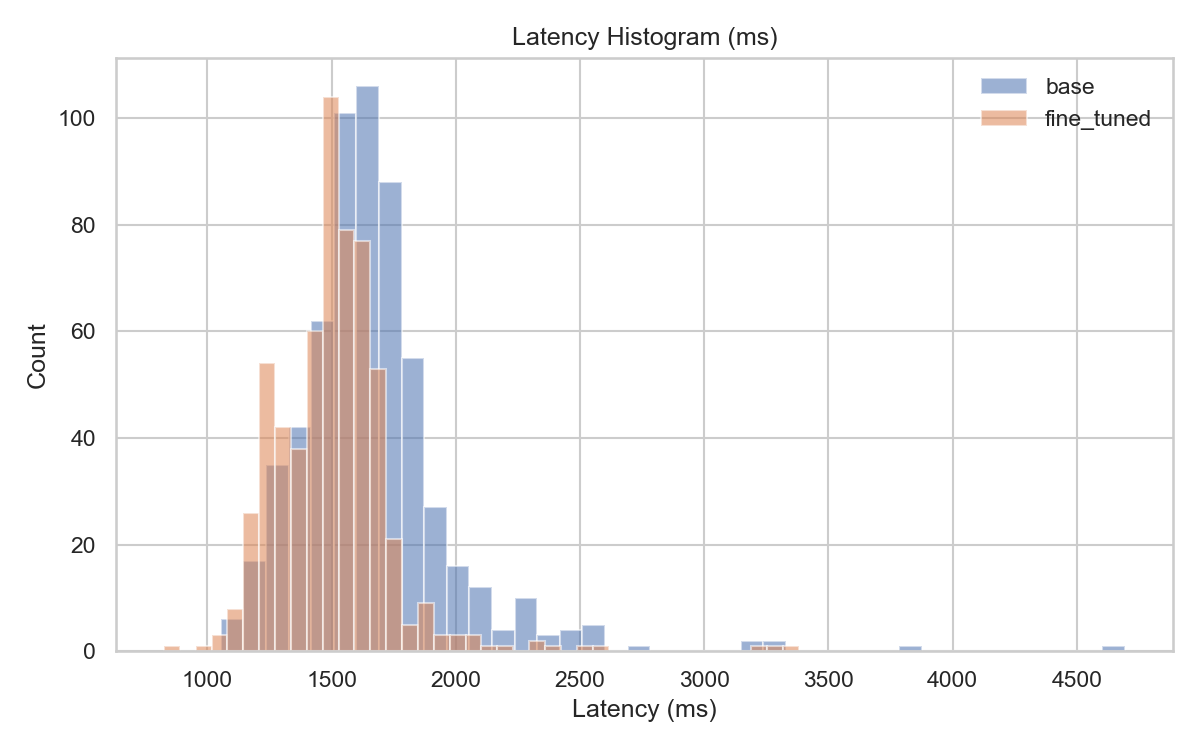
Latency
Inference with the base GPT-4o took on average 1.67 s per image, whereas the fine-tuned model reduced that to 1.51 s (around 9.6 % faster). This slight improvement reflects better task alignment. The CNN baseline was not benchmarked for latency here, but on commodity hardware it typically returns predictions in tens of milliseconds per image, which can be advantageous for ultra-low-latency scenarios.
Cost
Using the Azure OpenAI Batch API for the base model only incurs inference costs (at a 50 % discount vs. synchronous calls).
Fine-tuning introduces additional costs for training and hosting the new model plus inference, but can be more economical in the long run when processing very large batches with higher accuracy. Here, the fine-tuning training job has costed $152 and inference is 10% more expensive than the base model across input, cached input, and output.
The CNN baseline can be hosted locally or on inexpensive Azure Machine Learning compute; it has low inference cost but requires more effort to train and maintain (data pipelines, updates, and infrastructure).
Key takeaways
Across all three models, the results highlight a clear trade-off between accuracy, latency, and cost.
- Fine-tuning GPT-4o on Azure OpenAI produced the highest accuracy while also slightly reducing latency.
- The zero-shot GPT-4o base model requires no training and is the fastest path to production, but with lower accuracy.
- The lightweight CNN offers a low-cost, low-infrastructure option, yet its accuracy lags far behind and it demands more engineering effort to train and maintain.
Next Steps: How to Apply This in Your Own Projects
This walkthrough demonstrated how you can take a pre-trained Vision-Language Model (GPT-4o) on Azure AI Foundry, fine-tune it with your own labeled images using the Vision Fine-Tuning API, and benchmark it against both zero-shot performance and a traditional CNN baseline.
By combining Batch API inference for cost-efficient evaluation with Vision Fine-Tuning for task-specific adaptation, you can unlock higher accuracy and better latency without building and training large models from scratch.
If you’d like to access more insights on the comparison, replicate or extend this experiment, check out the GitHub repository for code, JSONL templates, and evaluation scripts.
From here, you can:
- Try other datasets or tasks (classification, OCR, multimodal prompts).
- Experiment with different fine-tuning parameters.
- Integrate the resulting model into your own applications or pipelines.
With Azure AI Foundry, you can move from prototype to production quickly while taking advantage of a diverse model catalog in Azure AI Foundry Models, managed infrastructure, and enterprise-grade security.
Learn More
▶️Register for Ignite’s AI fine-tuning in Azure AI Foundry to make your agents unstoppable
👩💻Explore fine-tuning with Azure AI Foundry documentation
👋Continue the conversation on Discord
0 comments