


My name is Bob Tabor and I’m a member of Microsoft’s Skilling organization. We create documentation and training content about Azure, developer tooling and languages, AI, Windows and much more hosted at Microsoft Learn. Our organization also develops and maintains the content publishing platform, the content hosting platform, the interactivity, and popular sites like Microsoft Q&A.
One of the most ambitious and impactful projects our engineers have built recently is Ask Learn, an API that provides generative AI capabilities to Microsoft Q&A and the ground truth necessary to power the new Microsoft Copilot for Azure experience.
This blog post details the story of collaboration between different product and engineering teams working together across Microsoft to build one of the world’s first retrieval-augmented generation (RAG) systems at such a massive scale. More importantly, this post shares insight into the lessons our engineers learned and advice to help you avoid some of the biggest pitfalls if you are tasked with building a Retrieval-Augmented Generation chat system for your organization.
Re-introducing Microsoft Copilot for Azure
At the Ignite conference in November 2023, the Azure portal team announced Microsoft Copilot for Azure and made it available in public preview. Copilot for Azure is a generative AI-powered chat experience in the Azure portal.
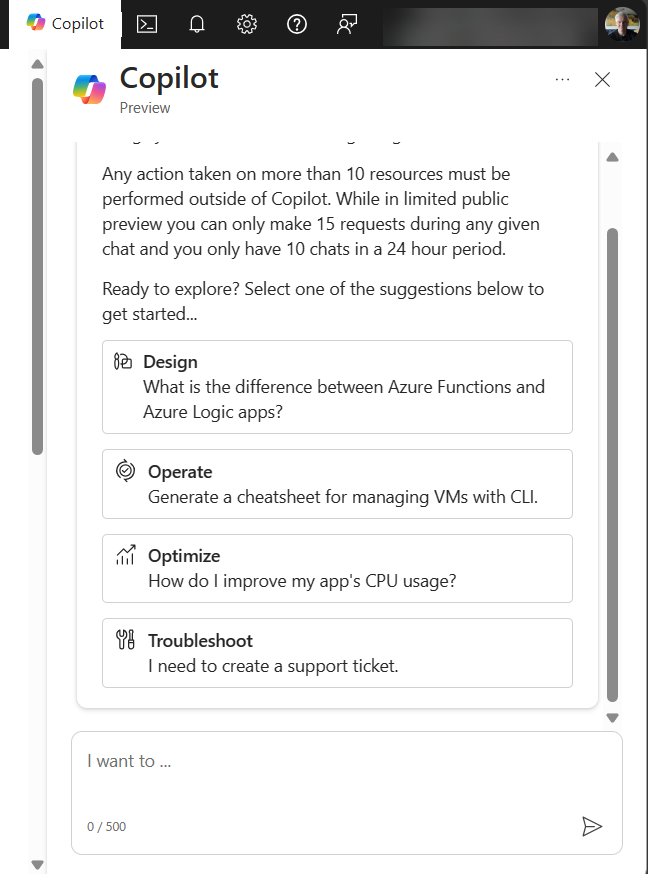
Customers can ask questions to learn more about Azure services, or they can ask questions about their existing Azure deployments. They can even ask the AI chatbot to take action on their account, like deploying a new service or even something as powerful as the request to shut down all running VMs in their subscription.
The user interface provides a friendly and familiar chat that removes the need to open another browser tab to find troubleshooting steps or an article in the Azure documentation in Microsoft Learn.
What may not be obvious is the amount of work goes into ensuring Copilot for Azure provides accurate, reliable, relevant, and verifiable results. Moreover, few could anticipate just how pivotal a role Microsoft Learn documentation plays in helping Copilot for Azure complete virtually all its tasks – beyond question-answering.
But this story begins with the intent to solve an entirely different problem.
From hackathon to new, powerful Microsoft Q&A features
Every February, the Skilling organization hosts an annual internal hackathon called “Fix. Hack. Learn.” During the February 2023 hackathon, virtually every participant experimented with using generative AI to improve some aspect of the customers’ experience or automate some internal process.
During this time, Skilling’s engineers experimented with ideas for enhancing the customer experience with Microsoft Q&A, the community-driven question-and-answer platform.
After asking a question, users typically must wait several hours for the community to engage with a new question. Usually, the community’s initial responses include clarifying questions needed to reach a helpful answer. So, the first problem the engineering team tackled was to help customers ask better questions so that they could get better answers more quickly. They introduced a new feature that gives customers generative AI feedback on how they worded their questions and even provides an option to “rewrite for me.”
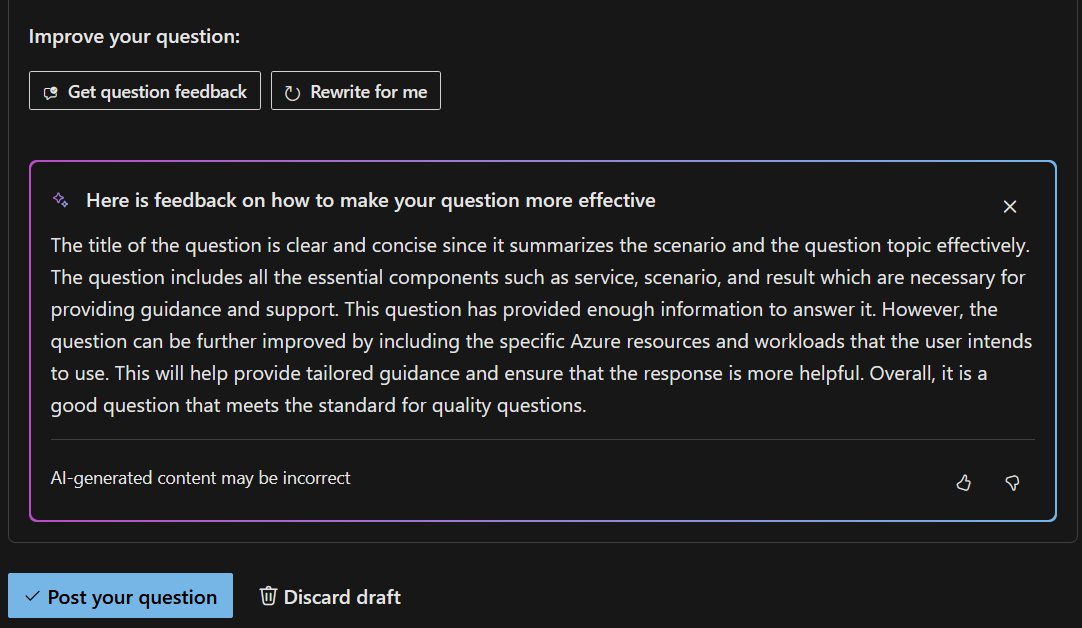
The next evolutionary step was to provide interim answers to customers via generative AI based on documentation from Microsoft Learn. To accomplish this, the team would need to locate portions of documentation that align closely to the question and feed those to the Large Language Model (LLM) so that it could generate a potential answer.
Answering questions using Retrieval-augmented Generation (RAG)
If you’ve followed developments for the past year or so with generative AI, you’ve likely heard of the retrieval-augmented generation (RAG) pattern. This pattern aims to provide the LLM with enough context from a reliable source about a given topic to compose an accurate answer. It accomplishes this by creating an embedding that represents the document (or, more often, a smaller portion of the document, called a “chunk”). An embedding is a vector of numbers that represent the text. Each number represents some facet of the chunk, including topic matter, keywords, language, tone, etc. Finally, you store those embedding values, the chunk, and other metadata in a vector database.

There’s usually a lot of post-chunking clean-up, a lot of tweaking to find the right chunk size, experimentation to the right amount of overlap between document chunks, and so on. There are also several strategies on how best to organize the chunks to improve retrieval.
With the ground truth data saved in a vector database, when a user asks a question, the system generates an embedding vector for the question itself, and then a search is performed to find similar vectors already stored in the database. Vector databases employ a search algorithm known as “cosine similarly” (or “nearest neighbor”) to find candidate article chunks that might help answer the user’s question. The final step is to send the original question and the closest matching article chunks it found to the LLM to formulate a response.
Usually, a RAG-based inference (question-answering) pipeline looks like the diagram below:
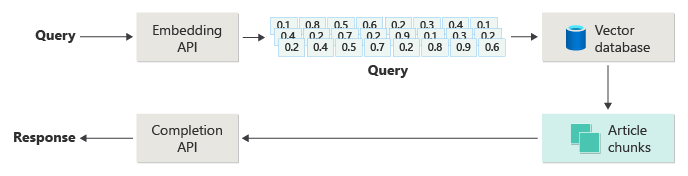
As we’ll discuss in a moment, this is an overly simplified depiction – in fact, one scholarly paper refers to it as a “naïve RAG”. It leaves out much of the complexity required for accurate, reliable results.
Naïve RAG gives you decent results. However, Microsoft’s customers expect reliable, relevant, accurate, and verifiable answers. That requires a lot more work, mostly in the form of adding a significant amount of logic and additional calls to the LLM before and after each stage in the process. (The same scholarly paper refers to this more complex version as “Advanced RAG”).
Advanced RAG adds pre- and post-processing tasks to virtually every step in the data collection process as well as the inference pipeline. For example, take the previous diagram, which depicts a simple inference pipeline. An Advanced RAG version of the earlier diagram might resemble this:

Pre-retrieval processing could include tasks like query rewriting, query expansion, and query clarification.
Post-retrieval processing could include tasks like re-ranking the document chunks retrieved from the vector database, expanding the chunks to provide more context (so, adding related document chunks to the result set), filtering irrelevant, redundant, or low-quality information from the retrieved set, and compressing the results into a more compact form, and more.
Once the pre-processing, retrieval, and post-processing are complete, you send the processed query and chunks to the LLM to complete a response. Once the LLM gives an answer, there may be even more processing to ensure that the answer meets the quality bar, doesn’t violate any safety, ethical, or operational guidelines and restrictions.
Building Microsoft Q&A Assist: An Advanced RAG
Skilling engineers had just a few months to implement many of the Advanced RAG features required to give customers high quality answers to their questions.
They designed a service-oriented architecture featuring a high-level orchestration layer responsible for calling individual services to handle each significant responsibility in the system.
For example, one of those individual services – perhaps the most essential service of all — is the Knowledge Service. Behind the scenes, the Knowledge Service is responsible for breaking Microsoft Learn’s technical documentation into chunks, creating embedding vectors for each chunk, and saving the vectors and chunks in a database. This is a huge data engineering effort, made more challenging by the need to keep the database updated when any one of hundreds of technical writers updates any one of hundreds of thousands of documents. Access to the vector database is made available via a web API and consumed by the orchestration layer.
Other services consumed by the orchestration layer handle pre- and post-processing tasks, various evaluations to determine the accuracy and reliability of the answer, and so on.
Solving the challenge of non-determinism
From the earliest stages of Q&A Assist’s development, a v-team of technical writers, engineers, data scientists from Skilling, and the CX Data & AI team looked for ways to improve the quality of the AI-generated results.
One of the most significant challenges with a generative AI system is that it is non-deterministic: given a set of inputs, you may never get the same output twice. So, organizations undertaking a “chat with your own data” project must start by investing the time to research and experiment in solving this engineering challenge – how do we influence generative AI models to get more reliable, relevant, and accurate results?
Building the “golden dataset”
The best place to start tackling the problem of non-determinism is by developing a “golden dataset.” A “golden dataset” is a carefully curated and annotated dataset that serves as a benchmark for evaluating the performance of AI models. When asked why they started with the “golden dataset,” Tom FitzMacken, one of the v-team members, said, “Here’s an example of its usefulness. The engineering team is considering a major change to what gets indexed for the knowledge service. They were able to run before and after tests over the golden dataset to see if performance improved or declined”.
In a RAG-based chat system, this benchmark dataset usually includes question-and-answer pairs, metadata (like topic and type of question), references to source documents that can serve as ground truth for answers, and perhaps even variations (different phrasings to capture the diversity of how users might ask the same questions). The “golden dataset” can be used in many capacities while Skilling’s engineers experiment with prompts, retrieval, monitoring, evaluation, etc.
The v-team started by working with experts across various technologies to build (and continue to grow) a “golden dataset” of questions, approved answers, and the best source articles to pull from. This benchmark has been immensely valuable in gauging the impact of code changes to produce the most accurate results.
The challenge of being “first”
As development on Q&A Assist progressed, Skilling engineers worked on various parts of the system — ingesting and chunking Microsoft Learn content, updating the vector database when the documentation was updated, building the inference pipeline, and integrating the results into Microsoft Q&A. Given how new these concepts were, in many cases, the engineers would be blazing a trail.
Trailblazing often means solving new technical, product, and organizational challenges. Being “first” often requires the team to become a forcing function to drive answers to questions the team needs to move forward. Joel Martinez, the Principal Engineering Manager on the Ecosystems Engineering team (aka, “Skilling’s engineers”) who helped design and build Q&A Assist described how they sought input and guidance from legal, AI ethics, privacy, and security teams, which required those teams to institute new policies and procedures – sometimes on the spot.
Furthermore, being “first” meant the engineering team could not simply leverage existing products, services, or pre-existing abstractions for portions of their solution architecture. Instead of waiting for product teams to release these building blocks, they built their own solutions in the interim. Once the components of the generative AI development stack started to emerge and the path became clearer, the team would choose whether to adopt what is becoming the standard or continue to build their own.
For example, Jeremy Stayton, a Senior Software Engineer who helped design and build the system, described how they built their solution using .NET to make calls directly to the Azure OpenAI’s Embedding and Completion APIs but later migrated to using the Azure SDK’s preview package for Azure OpenAI as it became available.
Another example was in the evaluation phase of the inference pipeline. Initially, Skilling’s engineers built custom Python notebooks to measure the quality of the documents retrieved from the vector store (to make sure they were relevant, given the user’s question), the groundedness of the answers (to make sure the generated response found its answers in facts from the documents), and the relevance of the answers. They also built a custom harms evaluation tool to evaluate answers for potential harm and identify gaps in the response that could put people at risk. Eventually, the engineering team would replace all of these evaluation tools with evaluation flows in Prompt flow.
While the product and engineering teams were pioneering certain aspects of the system, fortunately there were technical challenges that were “known,” and they could leverage the expertise of existing internal products and services. For example, one significant problem to be solved by Tianqi Zhang and the Knowledge Service team was updating their internal store of vector embeddings continuously, as technical writers publish updates. In this case, they were able to consult with and gain direction from the Discovery and Search teams and the Bing teams, who solved these engineering challenges years ago.
A milestone and an opportunity to provide “Answers as a service”
After just a few short, intense months of development, in May 2023, the team introduced Microsoft Q&A Assist, a significant milestone in harnessing Microsoft Learn content in a new way for our customers.
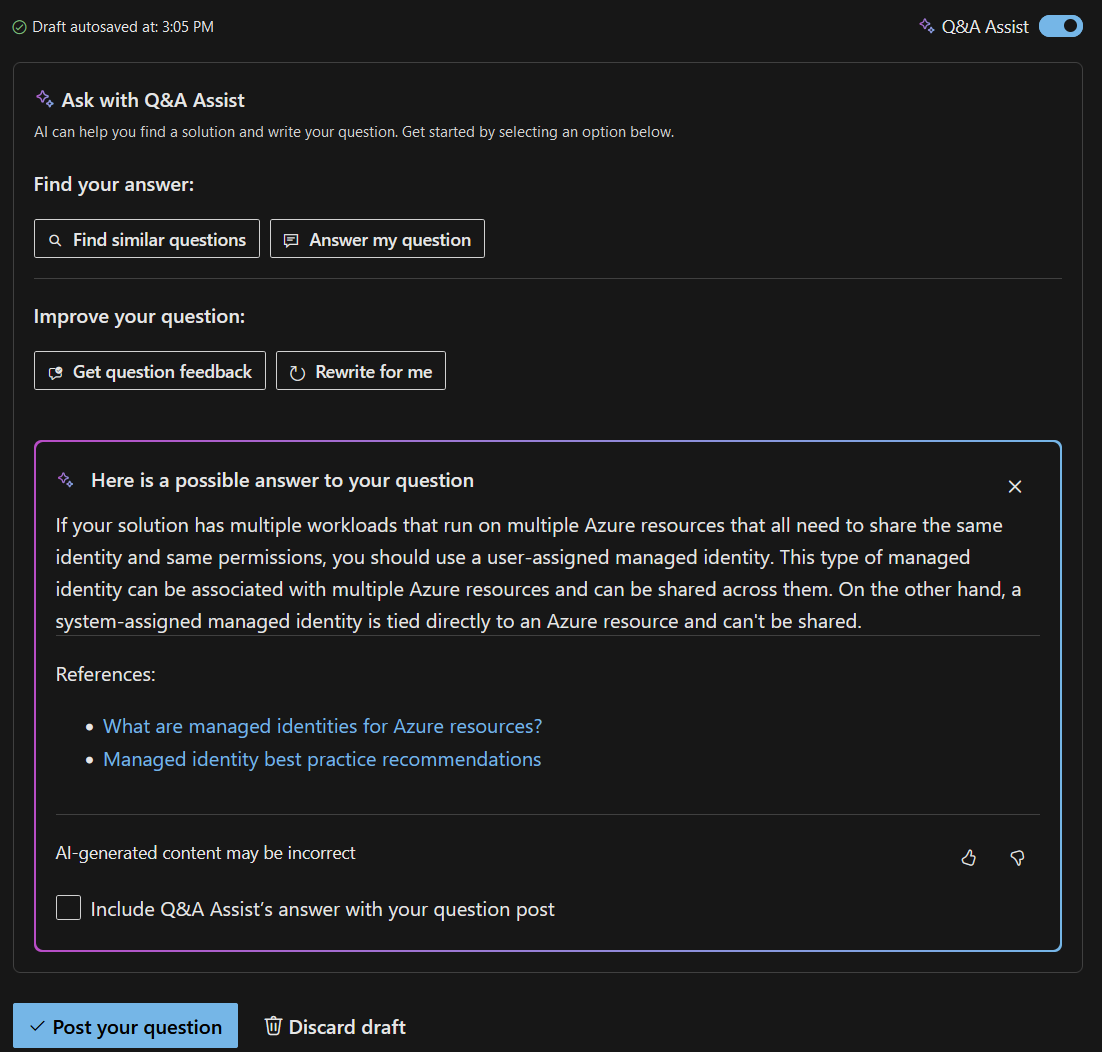
Soon after introducing the new AI-powered features, the Microsoft Q&A Assist team collaborated with the Azure Portal team to expose the underlying RAG system as a web API to be consumed by the new Copilot for Azure service. Fortunately, the Q&A Assist service was architected in a way that required only a few minor tweaks to serve the needs of Microsoft Q&A and be used as a Copilot plugin. The re-purposed service would be named “Ask Learn”.
“Ask Learn” is only one of many such services. The Azure Portal team relies on a series of providers from partner teams for the underlying functionality to do things like take action on my subscription (so for example, “Please shut down all of my VMs that are currently running.”).
The Copilot for Azure team had already begun partnering with Azure service teams to build a toolbox of functionality that could be orchestrated to complete customer tasks. Given that the Azure portal supports hundreds of thousands – if not millions – of distinct operations, the only way to solve this complexity was to employ an extensibility model. In other words, the various partner teams would create “chat handlers,” which are essentially super-powered Copilot plugins.
An expanded role for Ask Learn
Brian Steggeman, the product manager on the Learn Product and Platform team who helped create Microsoft Q&A Assist and Ask Learn, explained how Microsoft Copilot for Azure uses the results from Ask Learn in several ways. The most apparent is providing end users with a way to access the information they need while working in the Azure portal instead of opening a second tab to search the documentation for guidance, instructions, or troubleshooting information. Internally, the team referred to this paradigm as “ask, don’t search.” Context switching has costs, such as the cognitive load of sifting through search results to find the right article and the extra mental effort to adapt that article’s answer to the user’s situation. The team thinks Ask Learn will lessen this cognitive burden.
Less apparent are the other two critical scenarios that Ask Learn supports. First, it serves as grounding data for the Copilot and other chat handlers. In other words, Ask Learn provides an anchor of reliable facts and context that other components use to inform their actions. In some situations, the Copilot needs to orchestrate across several chat handlers to complete a task, and it may start with a call to Ask Learn to retrieve grounding data to ensure the final output is grounded and accurate. So, in this scenario, Ask Learn does not answer the question directly but contributes to the result for the user.
Second, Ask Learn serves as a fallback for the Copilot. In some situations where the Copilot can’t do what the user asked it to do or isn’t sure what to do to accomplish the user’s intent, rather than saying, “I’m sorry, I can’t help with that,” it can call Ask Learn to find helpful resources to help the user self-serve.
Capturing feedback from users
To successfully build generative AI solutions, you need feedback from users in production. However, capturing and acting on feedback was challenging, given Microsoft’s commitment to protecting the customer’s privacy. Microsoft’s privacy policies clearly state that the customer’s data belongs to the customer. Microsoft employees cannot see customer data such as generative AI inputs and outputs by default.
Upon the launch of Azure Copilot’s public preview, the team experimented with different ways to capture feedback on the quality of results. Customers were asked to rate the quality of the response (thumbs up / thumbs down ratings). At first, the responses were aggregated as quality metrics, which helped the team find broad issues.
Eventually, after working closely with Microsoft’s privacy team, Copilot for Azure engineers added a feature asking for the customers’ consent to share their chat history when giving feedback, along with verbatim feedback.
When the team acquires verbatim feedback about what they were expecting, they perform root cause analysis on each response – regardless of whether the responses were positive or negative. It is a time-intensive process, requiring the team to spend up to 30 minutes for each response investigating how the query produced the results, whether the correct chunks from Learn’s documentation were used, as well as the chunking strategy used to divide up a given Learn documentation article, additional pre- or post-processing steps that could have improved the result, etc. In some cases, the team identified content gaps when no ground truth was available in Microsoft Learn’s documentation for the question being asked.
One of the biggest takeaways is that this forensics step becomes increasingly challenging at scale. To address it, we’re currently developing an assessment pipeline with custom tooling to evaluate metrics that approximate answer quality. The assessment aims to answer questions like: “Given that the user asked this question, why did we give them this answer? What articles from Learn did we send to Azure OpenAI to answer this question? What were the results after running the prompt through our inference pipeline?” One outcome of this assessment is to improve Ask Learn’s inference pipeline – the steps before and after it sends the question to the AI.
Eventually, the assessment pipeline and metrics could improve the documentation by identifying gaps or improving how we communicate facts about our products.
Given the changes Skilling’s engineers already made in tooling, test data, and custom metrics, they feel much better equipped to make improvements to address relevance and accuracy going forward.
Lessons learned
An effort of this scale and complexity produced many learnings across many different areas of Microsoft. If your organization is thinking about building a RAG-based system to enable customers or employees to “chat over your data,” before you get started, consider these recommendations from the Ask Learn team based on the lessons they learned:
Plan ahead
Start with your existing content. Consider the kinds of questions and answers your system will be expected to field and then assess your content.
- Does your existing content answer those questions with sufficient context so that an LLM could re-purpose and re-phrase as needed?
- Is the content structured well and supported by metadata to be able to answer those questions?
- Will your content need to be processed? Does it need to be broken into chunks to fit within the model’s token limits/context window? How should you break it up to ensure that each chunk has enough quality data to be useful? (By the way, Azure AI Search now offers functionality to help make this easier.)
- Understand how your documentation team handles versioning and content age, where some product truths apply to specific versions but not others. How will you treat these edge cases?
- RAG projects can likely drive content changes. Make sure to get your content writers engaged and active in evaluating and understanding how their content affects what the LLM generates.
- Also, is your content up to date? Is it accurate? You’ll only get quality results from your RAG system when your content is fresh and accurate.
Evaluate success
Next, consider how you will evaluate success. Develop a set of metrics you will use to understand the improvements or regressions over time. Often, you’ll want to include metrics related to user satisfaction in terms of relevance since answer relevance is directly related to answer accuracy. But you may also want to develop a method to evaluate answers against grounded truth, if not for all your content, then at least a “golden dataset” – a curated set of questions and answers representing your entire content corpus. Decide up front how you will collect and evaluate customer feedback. If they’re not already in place, influence decision-makers to create data privacy and AI safety standards in the organization and decide how those will impact your technology and process decisions.
Understand the costs of evaluating customer feedback and how you will perform root cause analysis on the system’s output versus the customer’s expectations. Don’t underestimate the people-hours required to review, validate, and understand the inference steps and the documents used to generate answers. Reviewing questions and answers and deciding what you could do differently takes a lot of time.
Set expectations
You may need to educate your organization on how these systems work and set expectations accordingly. For example, design systems that play to the strengths of generative AI. It is good at summarization – perfect for the Ask Learn service. Generative AI is not as good yet (though improving) when you need logic or discriminative functionality.
Furthermore, generative AI systems are non-deterministic, and given minor variations in how the customer asks the question, the LLM may answer very differently. Question phrasing can even affect the truthfulness of the answer. The AI might answer a question correctly 999 times out of 1,000, but occasionally, it provides an incorrect answer. You will need some time of oversight to ensure it behaves appropriately.
Balance technical constraints
Finally, here’s a list of the engineering team’s “lessons learned” from the many technical challenges they solved.
- Adding multiple inference steps is one of the easiest ways to get better results. But when adding pre- and post-prompt processing steps, there’s a balance between improved results versus latency and cost. Measure the latency and costs as you experiment with multiple inference steps.
- Think about how you’re going to assess scale over time. Understand your throughput constraints and how they will affect capacity.
- Make safety and privacy part of your release plan. Some common safety and privacy deliverables include:
- Designing privacy and safety requirements (including governmental compliance requirements)
- Performing risk and privacy impact assessments
- Adding data protection measures at every customer touchpoint
- Testing and verifying the safeguards. Red-teaming was an important step in our Responsible AI safety evaluations. Red-teaming is the practice of simulating the actions of an adversary or attacker targeting the application to identify weaknesses or vulnerabilities. One of the biggest risks to LLMs is “jail breaking”, In the context of Large Language Models (LLMs), “jailbreaking” refers to techniques or strategies used by users to bypass or manipulate the model’s built-in safety, ethical, or operational guidelines and restrictions.
- Performing external safety reviews
- Documenting the safety and privacy aspects of the system
It’s easy to start building a RAG-based generative AI system, but the journey towards producing high-quality results will take time and effort. The journey could involve many of the considerations mentioned above, including improvements to your content, adding safeguards, continuous research, focusing on responsible AI, and more.
Learn more
For some guidance on building RAG-based chat systems, see: https://aka.ms/azai
For some guidance on evaluating results, see this repo as you start thinking about building an evaluation system: https://aka.ms/azai/eval
0 comments