
This week’s blog post is by Brian Lui, one of our summer interns on the .NET team, who’s been hard at work. Over to Brian:
Hello everyone! This summer I interned in the .NET team, working on ML.NET, an open-source machine learning platform which enables .NET developers to build and use machine learning models in their .NET applications. The ML.NET 0.6 release just shipped and you can try it out today.
At the start of my internship, ML.NET code was already relying on vectorization for performance, using a native code library. This was an opportunity to reimplement an existing codebase in managed code, using .NET Hardware Intrinsics for vectorization, and compare results.
What is vectorization, and what are SIMD, SSE, and AVX?
Vectorization is a name used for applying the same operation to multiple elements of an array simultaneously. On the x86/x64 platform, vectorization can be achieved by using Single Instruction Multiple Data (SIMD) CPU instructions to operate on array-like objects.
SSE (Streaming SIMD Extensions) and AVX (Advanced Vector Extensions) are the names for SIMD instruction set extensions to the x86 architecture. SSE has been available for a long time: the CoreCLR underlying .NET Core requires x86 platforms support at least the SSE2 instruction set. AVX is an extension to SSE that is now broadly available. Its key advantage is that it can handle 8 consecutive 32-bit elements in memory in one instruction, twice as much as SSE can.
.NET Core 3.0 will expose SIMD instructions as API’s that are available to managed code directly, making it unnecessary to use native code to access them.
ARM based CPU’s do offer a similar range of intrinsics but they are not yet supported on .NET Core (although work is in progress). Therefore, it is necessary to use software fallback code paths for the case when neither AVX nor SSE are available. The JIT makes it possible to do this fallback in a very efficient way. When .NET Core does expose ARM intrinsics, the code could exploit them at which point the software fallback would rarely if ever be needed.
Project goals
- Increase ML.NET platform reach (x86, x64, ARM32, ARM64, etc.) by creating a single managed assembly with software fallbacks
- Increase ML.NET performance by using AVX instructions where available
- Validate .NET Hardware Intrinsics API and demonstrate performance is comparable to native code
I could have achieved the second goal by simply updating the native code to use AVX instructions, but by moving to managed code at the same time I could eliminate the need to build and ship a separate binary for each target architecture – it’s also usually easier to maintain managed code.
I was able to achieve all these goals.
Challenges
It was necessary to first familiarize myself with C# and .NET, and then my work included:
- use
Span<T>in the base-layer implementation of CPU math operations in C#. If you’re unfamiliar withSpan<T>, see this great MSDN magazine article C# – All About Span: Exploring a New .NET Mainstay and also the documentation. - enable switching between AVX, SSE, and software implementations depending on availability.
- correctly handle pointers in the managed code, and remove alignment assumptions made by some of the existing code
- use multitargeting to allow ML.NET continued to function on platforms that don’t have .NET Hardware Intrinsics APIs.
Multi-targeting
.NET Hardware Intrinsics will ship in .NET Core 3.0, which is currently in development. ML.NET also needs to run on .NET Standard 2.0 compliant platforms – such as .NET Framework 4.7.2 and .NET Core 2.1. In order to support both I chose to use multitargeting to create a single .csproj file that targets both .NET Standard 2.0 and .NET Core 3.0.
- On .NET Standard 2.0, the system will use the original native implementation with SSE hardware intrinsics
- On .NET Core 3.0, the system will use the new managed implementation with AVX hardware intrinsics.
As the code was originally
In the original code, every trainer, learner, and transform used in machine learning ultimately called a SseUtils wrapper method that performs a CPU math operation on input arrays, such as
MatMulDense, which takes the matrix multiplication of two dense arrays interpreted as matrices, andSdcaL1UpdateSparse, which performs the update step of the stochastic dual coordinate ascent for sparse arrays.
These wrapper methods assumed a preference for SSE instructions, and called a corresponding method in another class Thunk, which serves as the interface between managed and native code and contains methods that directly invoke their native equivalents. These native methods in .cpp files in turn implemented the CPU math operations with loops containing SSE hardware intrinsics.
Breaking out a managed code-path
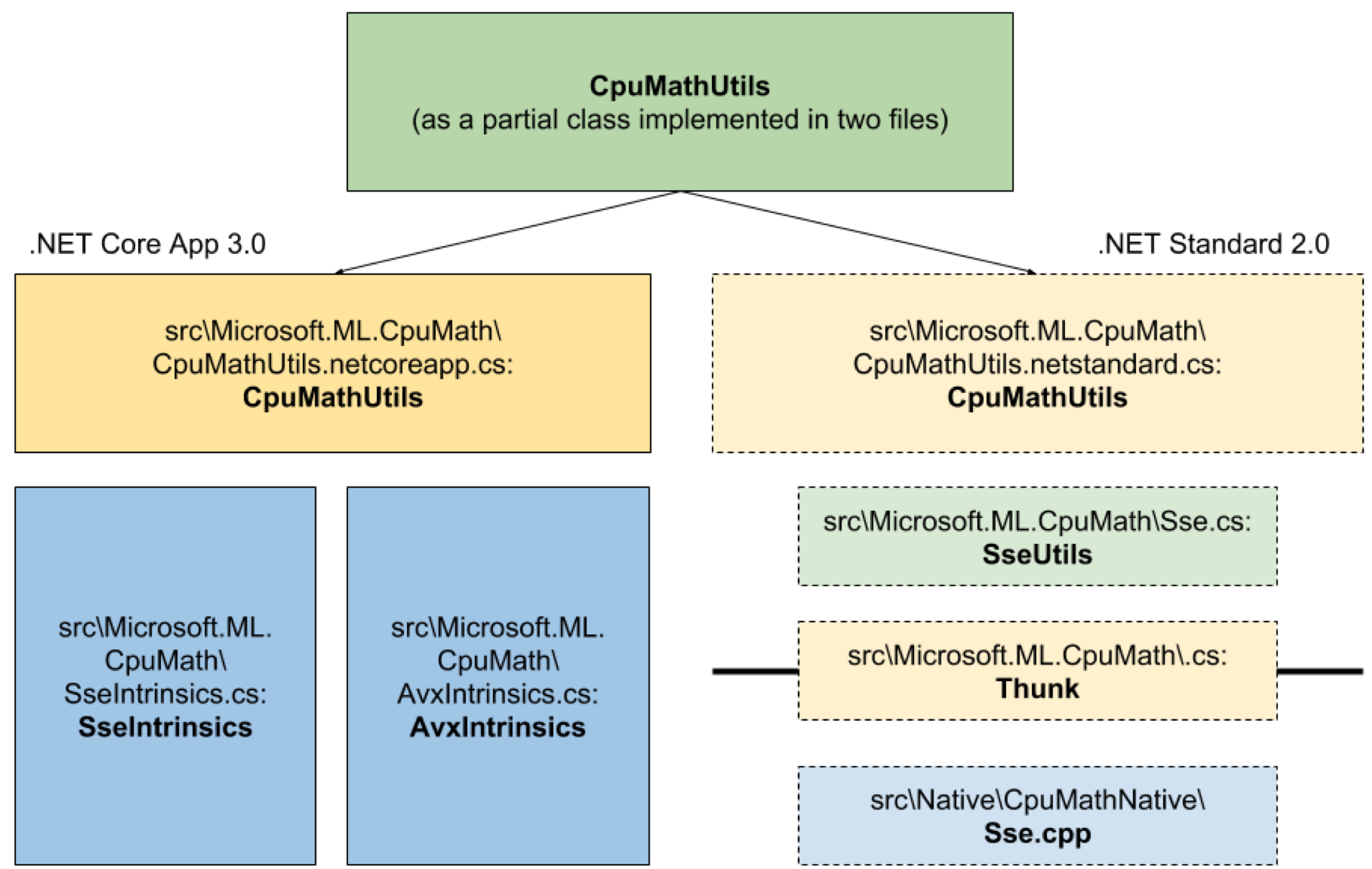
To this code I added a new independent code path for CPU math operations that becomes active on .NET Core 3.0, and by keeping the original code path running on .NET Standard 2.0. All previous call sites of SseUtilsmethods now called CpuMathUtils methods of the same name instead, keeping the API signatures of CPU math operations the same.
CpuMathUtils is a new partial class that contains two definitions for each public API representing CPU math operation, one of which is compiled only on .NET Standard 2.0 while the other, only on .NET Core 3.0. This conditional compilation feature creates two independent code paths for CpuMathUtils methods. Those function definitions compiled on .NET Standard 2.0 call their SseUtils counterparts directly, which essentially follow the original native code path.
Writing code with software fallback
On the other hand, the other function definitions compiled on .NET Core 3.0 switch to one of three implementations of the same CPU math operation, based on availability at runtime:
- an
AvxIntrinsicsmethod which implements the operation with loops containing AVX hardware intrinsics, - a
SseIntrinsicsmethod which implements the operation with loops containing SSE hardware intrinsics, and - a software fallback in case neither AVX nor SSE is supported.
You will commonly see this pattern whenever code uses .NET Hardware Intrinsics – for example, this is what the code looks like for adding a scalar to a vector:
If AVX is supported, it is preferred, otherwise SSE is used if available, otherwise the software fallback path. At runtime, the JIT will actually generate code for only one of these three blocks, as appropriate for the platform it finds itself on.
To give you an idea, here what the AVX implementation looks like that’s called by the method above:
You will notice that it operates on floats in groups of 8 using AVX, then any group of 4 using SSE, and finally a software loop for any that remain. (There are potentially more efficient ways to do this, which I won’t discuss here – there will be future blog posts dedicated to .NET Hardware Intrinsics.)
You can see all my code on the dotnet/machinelearning repository.
Since the AvxIntrinsics and SseIntrinsics methods in managed code directly implement the CPU math operations analogous to the native methods originally in .cpp files, the code change not only removes native dependencies but also simplifies the levels of abstraction between public APIs and base-layer hardware intrinsics.
After making this replacement I was able to use ML.NET to perform tasks such as train models with stochastic dual coordinate ascent, conduct hyperparameter tuning, and perform cross validation, on a Raspberry Pi, when previously ML.NET required an x86 CPU.
Here’s what the architecture looks like now (Figure 1):
Performance improvements
So what difference did this make to performance?
I wrote tests using Benchmark.NET to gather measurements.
First, I disabled the AVX code paths in order to fairly compare the native and managed implementations while both were using the same SSE instructions. As Figure 2 shows, the performance is closely comparable: on the large vectors the tests operate on, the overhead added by managed code is not significant.
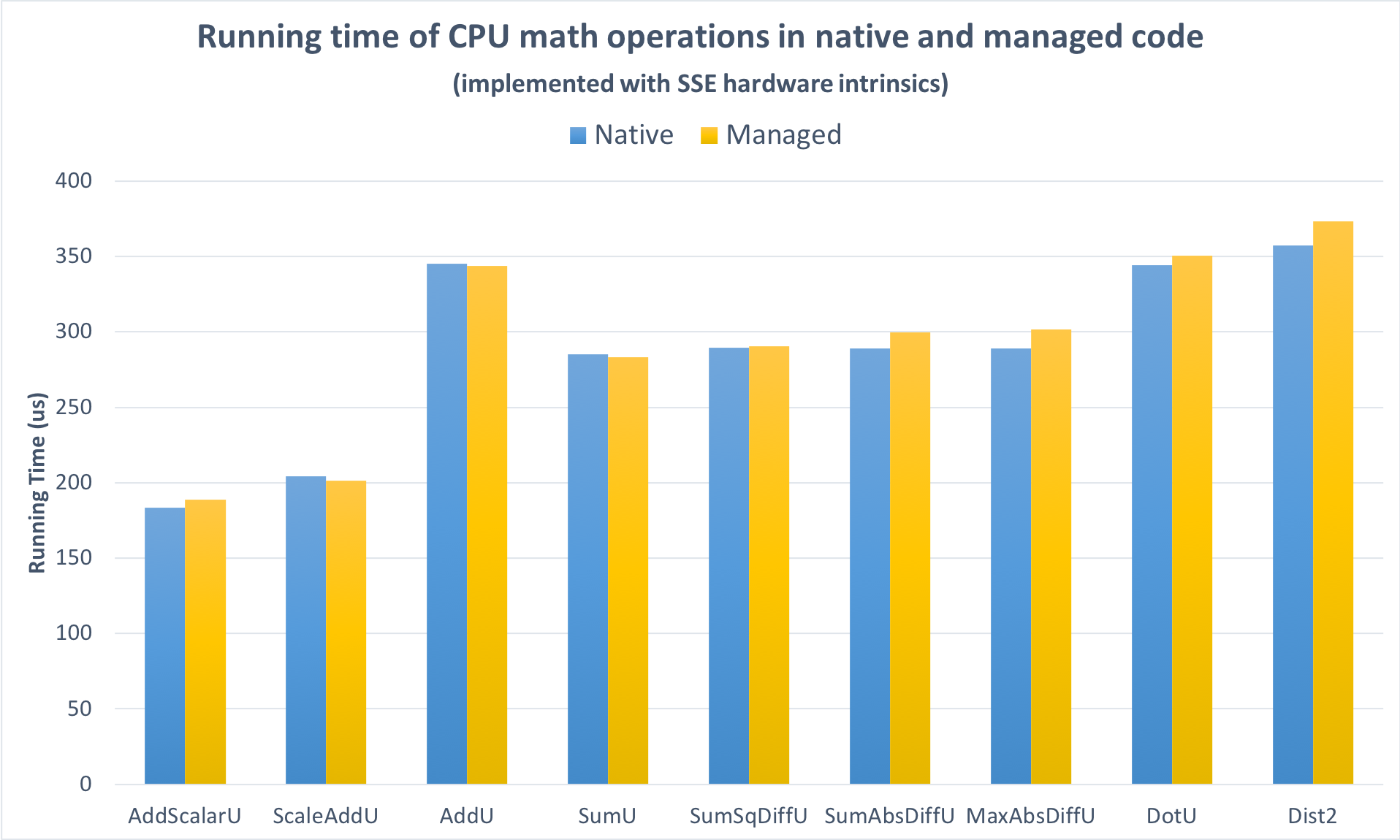
Figure 2
Second, I enabled AVX support. Figure 3 shows that the average performance gain in microbenchmarks was about 20% over SSE alone.
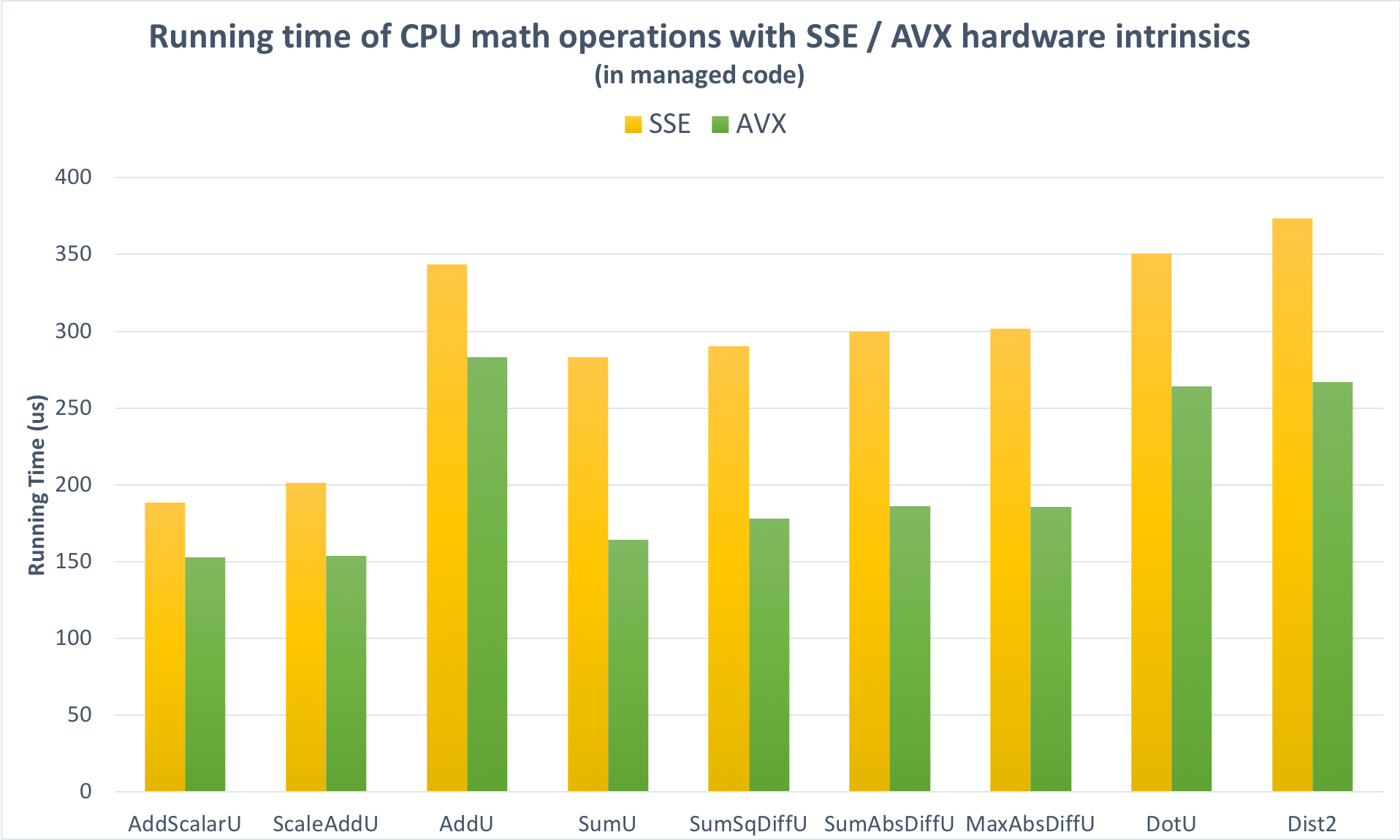
Figure 3
Taking both together — the upgrade from the SSE implementation in native code to the AVX implementation in managed code — I measured an 18% improvement in the microbenchmarks. Some operations were up to 42% faster, while some others involving sparse inputs have potential for further optimization.
What ultimately matters of course is the performance for real scenarios. On .NET Core 3.0, training models of K-means clustering and logistic regression got faster by about 14% (Figure 4).
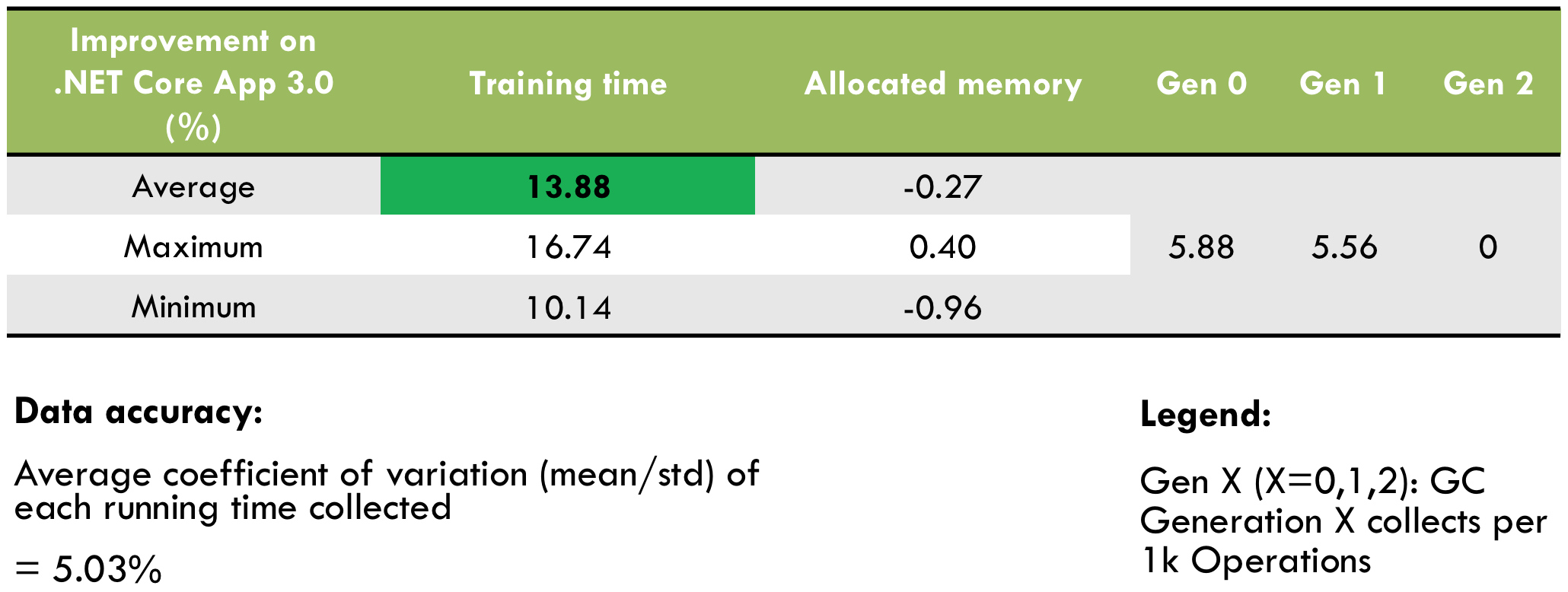
Figure 4
In closing
My summer internship experience with the .NET team has been rewarding and inspiring for me. My manager Dan and my mentors Santi and Eric gave me an opportunity to go hands-on with a real shipping project. I was able to work with other teams and external industry partners to optimize my code, and most importantly, as a software engineering intern with the .NET team, I was exposed to almost every step of the entire working cycle of a product enhancement, from idea generation to code review to product release with documentation.
I hope this has demonstrated how powerful .NET Hardware Intrinsics can be and I encourage you to consider opportunities to use them in your own projects when previews of .NET Core 3.0 become available.
Hi,Really cool article, I never thought I could use intrinsics in .Net…I tried to do some stuff with this but had to notice that the entire Microsoft.ML.Internal.CpuMath library is…well, internal. I couldn’t use any of the things you talked about and, as the whole thing is licensed as MIT, had to copy the source code to my project (which is really inefficient…).Would you be so kind to release that library as an actual library that could be used by third parties? Best regards