
Today at Spark + AI summit we are excited to announce .NET for Apache Spark. Spark is a popular open source distributed processing engine for analytics over large data sets. Spark can be used for processing batches of data, real-time streams, machine learning, and ad-hoc query.
.NET for Apache Spark is aimed at making Apache® Spark™ accessible to .NET developers across all Spark APIs. So far Spark has been accessible through Scala, Java, Python and R but not .NET.
We plan to develop .NET for Apache Spark in the open (as a .NET Foundation member project) along with the Spark and .NET community to ensure that developers get the best of both worlds.

https://github.com/dotnet/spark Star
The remainder of this post provides more specifics on the following topics:
- What is .NET For Apache Spark?
- Getting Started with .NET for Apache Spark
- .NET for Apache Spark performance
- What’s next with .NET For Apache Spark
- Wrap Up
What is .NET for Apache Spark?
.NET for Apache Spark provides high performance APIs for using Spark from C# and F#. With this .NET APIs, you can access all aspects of Apache Spark including Spark SQL, DataFrames, Streaming, MLLib etc. .NET for Apache Spark lets you reuse all the knowledge, skills, code, and libraries you already have as a .NET developer.
The C#/ F# language binding to Spark will be written on a new Spark interop layer which offers easier extensibility. This new layer of Spark interop was written keeping in mind best practices for language extension and optimizes for interop and performance. Long term this extensibility can be used for adding support for other languages in Spark.
You can learn more details about this work through this proposal.
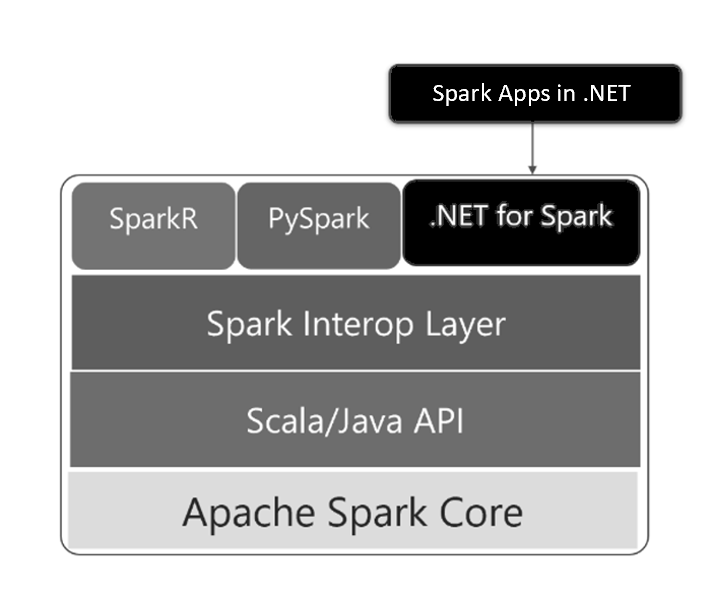
.NET for Apache Spark is compliant with .NET Standard 2.0 and can be used on Linux, macOS, and Windows, just like the rest of .NET. .NET for Apache Spark is available by default in Azure HDInsight, and can be installed in Azure Databricks and more.
Getting Started with .NET for Apache Spark
Before you can get started with .NET for Apache Spark, you do need to install a few things. Follow these steps to get started with .NET for Apache Spark
Once setup, you can start programming Spark applications in .NET with three easy steps.
In our first .NET Spark application we will write a basic Spark pipeline which counts the occurrence of each word in a text segment.
// 1. Create a Spark session
var spark = SparkSession
.Builder()
.AppName("word_count_sample")
.GetOrCreate();
// 2. Create a DataFrame
DataFrame dataFrame = spark.Read().Text("input.txt");
// 3. Manipulate and view data
var words = dataFrame.Select(Split(dataFrame["value"], " ").Alias("words"));
words.Select(Explode(words["words"])
.Alias("word"))
.GroupBy("word")
.Count()
.Show();
.NET for Apache Spark performance
We are pleased to say that the first preview version of .NET for Apache Spark performs well on the popular TPC-H benchmark. The TPC-H benchmark consists of a suite of business oriented queries. The chart below illustrates the performance of .NET Core versus Python and Scala on the TPC-H query set.
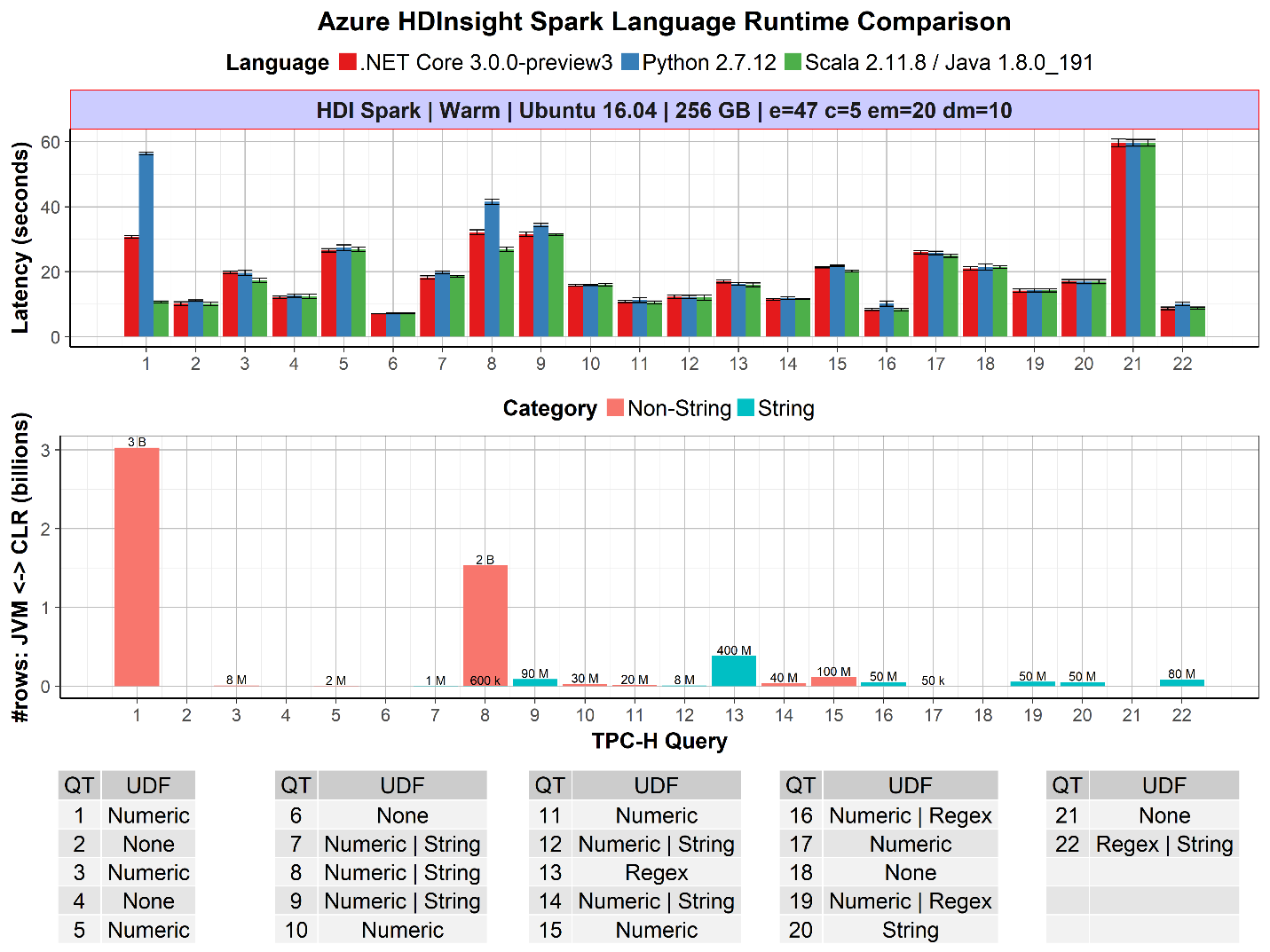
The chart above shows the per query performance of .NET for Apache Spark versus Python and Scala. .NET for Apache Spark performs well against Python and Scala . Furthermore, in cases where UDF performance is critical such as query 1 where 3B rows of non-string data is passed between the JVM and the CLR .NET for Apache Spark is 2x faster than Python.
It’s also important to call out that this is our first preview of .NET for Apache Spark and we aim to further invest in improving and benchmarking performance (e.g. Arrow optimizations). You can follow our instructions to benchmark this on our GitHub repo.
What’s next with .NET For Apache Spark
Today marks the first step in our journey. Following are some features on our near-term roadmap. Please follow the full roadmap on our GitHub repo.
- Simplified getting started experience, documentation and samples
- Native integration with developer tools such as Visual Studio, Visual Studio Code, Jupyter notebooks
- .NET support for user-defined aggregate functions
- .NET idiomatic APIs for C# and F# (e.g., using LINQ for writing queries)
- Out of the box support with Azure Databricks, Kubernetes etc.
- Make .NET for Apache Spark part of Spark Core. You can follow this progress here.
See something missing on this list, please drop us a comment below
Wrap Up
.NET for Apache Spark is our first step in making .NET a great tech stack for building Big Data applications.
We need your help to shape the future of .NET for Apache Spark, we look forward to seeing what you build with .NET for Apache Spark. You can provide reach out to us through our GitHub repo.
https://github.com/dotnet/spark Star
This blog is authored by Rahul Potharaju, Ankit Asthana, Tyson Condie, Terry Kim, Dan Moseley, Michael Rys and the rest of the .NET for Apache Spark team.
Thank you for allowing me to read it, welcome to the next in a recent article. And thanks for sharing the nice article, keep posting or updating news article.
https://www.gangboard.com/big-data-training/hadoop-training
Sounds really great, looking forward to it. Is this in any way related to https://github.com/Microsoft/Mobius ?
Yes it is! Take a look at the github repository https://github.com/dotnet/spark, it is mentioned there.
Hi Carlos,
I would like to ask you about https://github.com/Microsoft/Mobius -> because if I understood correctly, this is old/first version of C# implementation to connect to Spark.
.NET Spark is a new solution which is great, but unfortunately I could not find “CreateDataFrame” method which can be used for create a dataframe from C# List for instance… as it was it in Mobius.
Will it be added (support for create data frame) to .NET Spark in the near future ?
Good to know C# will be available on Spark but I have a question. Why do you choose to use TPC-H instead of TPC-DS for benchmarking given that Spark is mainly used for big data? Will you provide numbers from TPC-DS?. Thank you
Thanks for your feedback. We are going to be working on collecting performance benchmarking data on TPC-DS as a part of our roadmap.
.NET needs another alteration. Please make C# programs performance like(no, rather, faster than) Rust language. Ok?
not Microsoft, but Unity started working on something: High Performance C#, http://lucasmeijer.com/posts/cpp_unity/
Maybe MS can adopt it later on like it did with Mono/Unity/…
Sorry, please answer me. is it possible? does Microsoft work on this issue(performance) for C# more? Of course my only choose is C# but i expect to be best of bests. Thanks.