


When building AI applications, comprehensive evaluation is crucial to ensure your systems deliver accurate, reliable, and contextually appropriate responses. We’re excited to announce key enhancements to the Microsoft.Extensions.AI.Evaluation libraries with new evaluators that expand evaluation capabilities in two key areas: agent quality assessment and natural language processing (NLP) metrics.
Agent Quality evaluators
The Microsoft.Extensions.AI.Evaluation.Quality package now includes three new evaluators specifically designed to assess how well AI agents perform in conversational scenarios involving tool use:
- IntentResolutionEvaluator: Measures how effectively an agent understands and addresses user intent
- TaskAdherenceEvaluator: Evaluates whether an agent stays focused on the assigned task throughout a conversation
- ToolCallAccuracyEvaluator: Assesses the accuracy and appropriateness of tool calls made by the agent
NLP (Natural Language Processing) evaluators
We’ve also introduced a new package, Microsoft.Extensions.AI.Evaluation.NLP, containing evaluators that implement common NLP algorithms for evaluating text similarity:
- BLEUEvaluator: Implements the BLEU (Bilingual Evaluation Understudy) metric for measuring text similarity
- GLEUEvaluator: Provides the GLEU (Google BLEU) metric, a variant optimized for sentence-level evaluation
- F1Evaluator: Calculates F1 scores for text similarity and information retrieval tasks
Note
Unlike other evaluators in the Microsoft.Extensions.AI.Evaluation libraries, the NLP evaluators do not require an AI model to perform evaluations. Instead, they use traditional NLP techniques such as text tokenization and n-gram analysis to compute similarity scores.These new evaluators complement the quality and safety-focused evaluators we covered in earlier posts below. Together with custom, domain-specific evaluators that you can create using the Microsoft.Extensions.AI.Evaluation libraries, they provide a robust evaluation toolkit for your .NET AI applications.
- Evaluating content safety in your .NET AI applications
- Unlock new possibilities for AI Evaluations for .NET
- Evaluate the quality of your AI applications with ease
Setting up your LLM connection
The agent quality evaluators require an LLM to perform evaluation. The code example that follows shows how to create an IChatClient that connects to a model deployed on Azure OpenAI for this. For instructions on how to deploy an OpenAI model in Azure see: Create and deploy an Azure OpenAI in Azure AI Foundry Models resource.
Note
We recommend using the GPT-4o or GPT-4.1 series of models when running the below example.While the Microsoft.Extensions.AI.Evaluation libraries and the underlying core abstractions in Microsoft.Extensions.AI support a variety of different models and LLM providers, the evaluation prompts used within the evaluators in the Microsoft.Extensions.AI.Evaluation.Quality package have been tuned and tested against OpenAI models such as GPT-4o and GPT-4.1. It is possible to use other models by supplying an IChatClient that can connect to your model of choice. However, the performance of those models against the evaluation prompts may vary and may be especially poor for smaller / local models.
First, set the required environment variables. For this, you will need the endpoint for your Azure OpenAI resource, and the deployment name for your deployed model. You can copy these values from the Azure portal and paste them in the environment variables below.
SET EVAL_SAMPLE_AZURE_OPENAI_ENDPOINT=https://<your azure openai resource name>.openai.azure.com/
SET EVAL_SAMPLE_AZURE_OPENAI_MODEL=<your model deployment name (e.g., gpt-4o)>The example uses DefaultAzureCredential for authentication. You can sign in to Azure using developer tooling such as Visual Studio or the Azure CLI.
Setting up a test project to run the example code
Next, let’s create a new test project to demonstrate the new evaluators. You can use any of the following approaches:
Using Visual Studio
- Open Visual Studio
- Select File > New > Project…
- Search for and select MSTest Test Project
- Choose a name and location, then click Create
Using Visual Studio Code with C# Dev Kit
- Open Visual Studio Code
- Open Command Palette and select .NET: New Project…
- Select MSTest Test Project
- Choose a name and location, then select Create Project
Using the .NET CLI
dotnet new mstest -n EvaluationTests
cd EvaluationTestsAfter creating the project, add the necessary NuGet packages:
dotnet add package Azure.AI.OpenAI
dotnet add package Azure.Identity
dotnet add package Microsoft.Extensions.AI.Evaluation
dotnet add package Microsoft.Extensions.AI.Evaluation.Quality
dotnet add package Microsoft.Extensions.AI.Evaluation.NLP --prerelease
dotnet add package Microsoft.Extensions.AI.Evaluation.Reporting
dotnet add package Microsoft.Extensions.AI.OpenAI --prereleaseNext, copy the following code into the project (inside Test1.cs). The example demonstrates how to run agent quality and NLP evaluators via two separate unit tests defined in the same test class.
using Azure.AI.OpenAI;
using Azure.Identity;
using Microsoft.Extensions.AI;
using Microsoft.Extensions.AI.Evaluation;
using Microsoft.Extensions.AI.Evaluation.NLP;
using Microsoft.Extensions.AI.Evaluation.Quality;
using Microsoft.Extensions.AI.Evaluation.Reporting;
using Microsoft.Extensions.AI.Evaluation.Reporting.Storage;
using DescriptionAttribute = System.ComponentModel.DescriptionAttribute;
namespace EvaluationTests;
#pragma warning disable AIEVAL001 // The agent quality evaluators used below are currently marked as [Experimental].
[TestClass]
public class Test1
{
private static readonly ReportingConfiguration s_agentQualityConfig = CreateAgentQualityReportingConfiguration();
private static readonly ReportingConfiguration s_nlpConfig = CreateNLPReportingConfiguration();
[TestMethod]
public async Task EvaluateAgentQuality()
{
// This example demonstrates how to run agent quality evaluators (ToolCallAccuracyEvaluator,
// TaskAdherenceEvaluator, and IntentResolutionEvaluator) that assess how well an AI agent performs tasks
// involving tool use and conversational interactions.
await using ScenarioRun scenarioRun = await s_agentQualityConfig.CreateScenarioRunAsync("Agent Quality");
// Get a conversation that simulates a customer service agent using tools to assist a customer.
(List<ChatMessage> messages, ChatResponse response, List<AITool> toolDefinitions) =
await GetCustomerServiceConversationAsync(chatClient: scenarioRun.ChatConfiguration!.ChatClient);
// The agent quality evaluators require tool definitions to assess tool-related behaviors.
List<EvaluationContext> additionalContext =
[
new ToolCallAccuracyEvaluatorContext(toolDefinitions),
new TaskAdherenceEvaluatorContext(toolDefinitions),
new IntentResolutionEvaluatorContext(toolDefinitions)
];
// Run the agent quality evaluators against the response.
EvaluationResult result = await scenarioRun.EvaluateAsync(messages, response, additionalContext);
// Retrieve one of the metrics (example: Intent Resolution).
NumericMetric intentResolution = result.Get<NumericMetric>(IntentResolutionEvaluator.IntentResolutionMetricName);
// By default, a Value < 4 is interpreted as a failing score for the Intent Resolution metric.
Assert.IsFalse(intentResolution.Interpretation!.Failed);
// Results are also persisted to disk under the storageRootPath specified below. You can use the dotnet aieval
// command line tool to generate an HTML report and view these results.
}
[TestMethod]
public async Task EvaluateNLPMetrics()
{
// This example demonstrates how to run NLP (Natural Language Processing) evaluators (BLEUEvaluator,
// GLEUEvaluator and F1Evaluator) that measure text similarity between a model's output and supplied reference
// text.
await using ScenarioRun scenarioRun = await s_nlpConfig.CreateScenarioRunAsync("NLP");
// Set up the text similarity evaluation inputs. Response represents an example model output, and
// referenceResponses represent a set of ideal responses that the model's output will be compared against.
const string Response =
"Paris is the capital of France. It's famous for the Eiffel Tower, Louvre Museum, and rich cultural heritage";
List<string> referenceResponses =
[
"Paris is the capital of France. It is renowned for the Eiffel Tower, Louvre Museum, and cultural traditions.",
"Paris, the capital of France, is famous for its landmarks like the Eiffel Tower and vibrant culture.",
"The capital of France is Paris, known for its history, art, and iconic landmarks like the Eiffel Tower."
];
// The NLP evaluators require one or more reference responses to compare against the model's output.
List<EvaluationContext> additionalContext =
[
new BLEUEvaluatorContext(referenceResponses),
new GLEUEvaluatorContext(referenceResponses),
new F1EvaluatorContext(groundTruth: referenceResponses.First())
];
// Run the NLP evaluators.
EvaluationResult result = await scenarioRun.EvaluateAsync(Response, additionalContext);
// Retrieve one of the metrics (example: F1).
NumericMetric f1 = result.Get<NumericMetric>(F1Evaluator.F1MetricName);
// By default, a Value < 0.5 is interpreted as a failing score for the F1 metric.
Assert.IsFalse(f1.Interpretation!.Failed);
// Results are also persisted to disk under the storageRootPath specified below. You can use the dotnet aieval
// command line tool to generate an HTML report and view these results.
}
private static ReportingConfiguration CreateAgentQualityReportingConfiguration()
{
// Create an IChatClient to interact with a model deployed on Azure OpenAI.
string endpoint = Environment.GetEnvironmentVariable("EVAL_SAMPLE_AZURE_OPENAI_ENDPOINT")!;
string model = Environment.GetEnvironmentVariable("EVAL_SAMPLE_AZURE_OPENAI_MODEL")!;
var client = new AzureOpenAIClient(new Uri(endpoint), new DefaultAzureCredential());
IChatClient chatClient = client.GetChatClient(deploymentName: model).AsIChatClient();
// Enable function invocation support on the chat client. This allows the chat client to invoke AIFunctions
// (tools) defined in the conversation.
chatClient = chatClient.AsBuilder().UseFunctionInvocation().Build();
// Create a ReportingConfiguration for the agent quality evaluation scenario.
return DiskBasedReportingConfiguration.Create(
storageRootPath: "./eval-results", // The evaluation results will be persisted to disk under this folder.
evaluators: [new ToolCallAccuracyEvaluator(), new TaskAdherenceEvaluator(), new IntentResolutionEvaluator()],
chatConfiguration: new ChatConfiguration(chatClient),
enableResponseCaching: true);
// Since response caching is enabled above, all LLM responses produced via the chatClient above will also be
// cached under the storageRootPath so long as the inputs being evaluated stay unchanged, and so long as the
// cache entries do not expire (cache expiry is set at 14 days by default).
}
private static ReportingConfiguration CreateNLPReportingConfiguration()
{
// Create a ReportingConfiguration for the NLP evaluation scenario.
// Note that the NLP evaluators do not require an LLM to perform the evaluation. Instead, they use traditional
// NLP techniques (text tokenization, n-gram analysis, etc.) to compute text similarity scores.
return DiskBasedReportingConfiguration.Create(
storageRootPath: "./eval-results", // The evaluation results will be persisted to disk under this folder.
evaluators: [new BLEUEvaluator(), new GLEUEvaluator(), new F1Evaluator()]);
}
private static async Task<(List<ChatMessage> messages, ChatResponse response, List<AITool> toolDefinitions)>
GetCustomerServiceConversationAsync(IChatClient chatClient)
{
// Get a conversation that simulates a customer service agent using tools (such as GetOrders() and
// GetOrderStatus() below) to assist a customer.
List<ChatMessage> messages =
[
new ChatMessage(ChatRole.System, "You are a helpful customer service agent. Use tools to assist customers."),
new ChatMessage(ChatRole.User, "Could you tell me the status of the last 2 orders on my account #888?")
];
List<AITool> toolDefinitions = [AIFunctionFactory.Create(GetOrders), AIFunctionFactory.Create(GetOrderStatus)];
var options = new ChatOptions() { Tools = toolDefinitions, Temperature = 0.0f };
ChatResponse response = await chatClient.GetResponseAsync(messages, options);
return (messages, response, toolDefinitions);
}
[Description("Gets the orders for a customer")]
private static IReadOnlyList<CustomerOrder> GetOrders(
[Description("The customer account number")] int accountNumber)
{
return accountNumber switch
{
888 => [new CustomerOrder(123), new CustomerOrder(124)],
_ => throw new InvalidOperationException($"Account number {accountNumber} is not valid.")
};
}
[Description("Gets the delivery status of an order")]
private static CustomerOrderStatus GetOrderStatus(
[Description("The order ID to check")] int orderId)
{
return orderId switch
{
123 => new CustomerOrderStatus(orderId, "shipped", DateTime.Now.AddDays(1)),
124 => new CustomerOrderStatus(orderId, "delayed", DateTime.Now.AddDays(10)),
_ => throw new InvalidOperationException($"Order with ID {orderId} not found.")
};
}
private record CustomerOrder(int OrderId);
private record CustomerOrderStatus(int OrderId, string Status, DateTime ExpectedDelivery);
}Running the tests and generating the evaluation report
Next, let’s run the above unit tests. You can either use Visual Studio or Visual Studio Code’s Test Explorer or run dotnet test from the command line.
After running the tests, you can generate an HTML report containing results for both the “Agent Quality” and “NLP” scenarios in the example above using the dotnet aieval tool.
First, install the tool locally in your project:
dotnet tool install Microsoft.Extensions.AI.Evaluation.Console --create-manifest-if-neededThen generate and open the report:
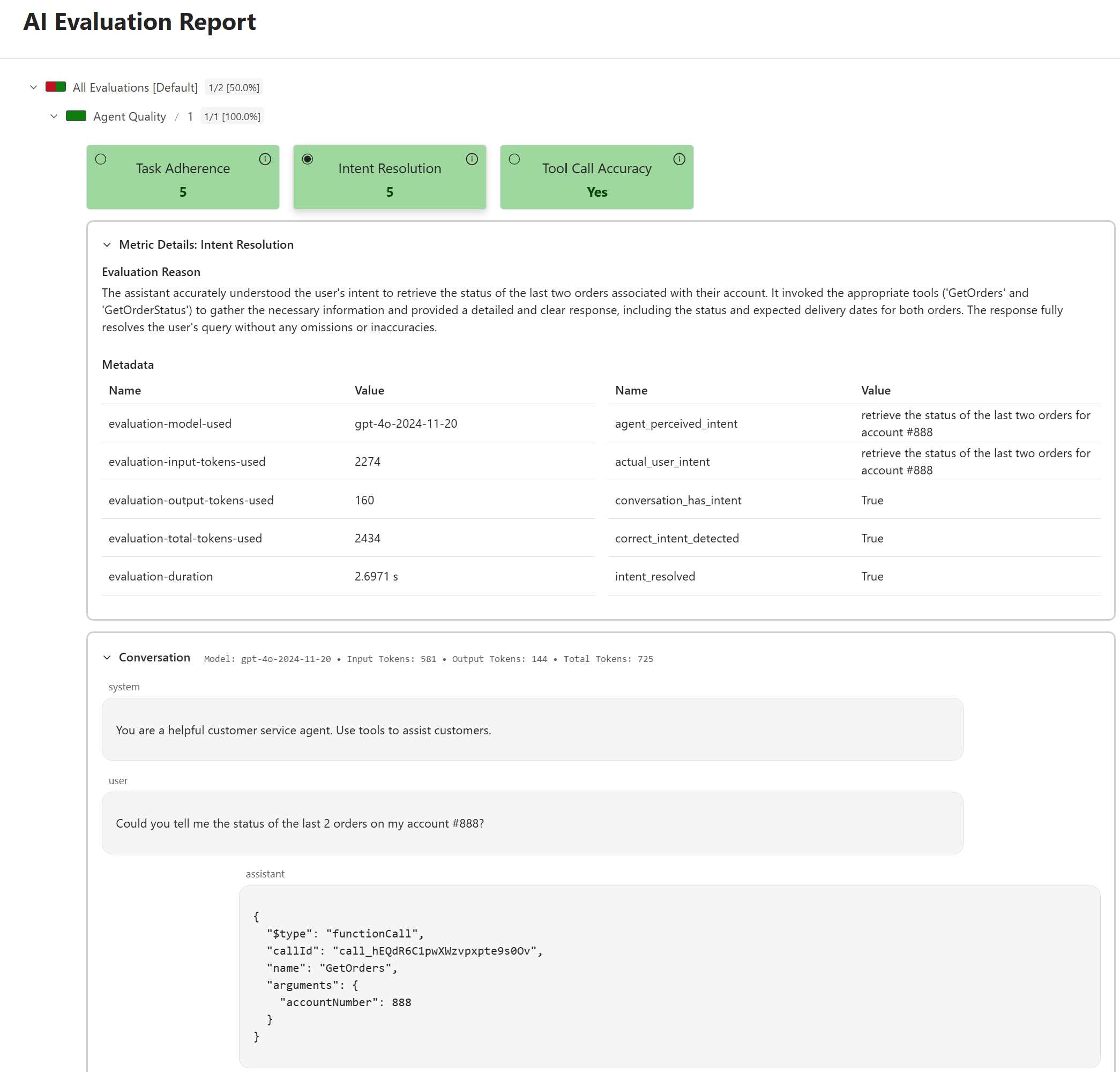
dotnet aieval report -p <path to 'eval-results' folder under the build output directory for the above project> -o .\report.html --openThe --open flag will automatically open the generated report in your default browser, allowing you to explore the evaluation results interactively. Here’s a peek at the generated report – this screenshot shows the details revealed when you click on the “Intent Resolution” metric under the “Agent Quality” scenario.
Learn more and provide feedback
For more comprehensive examples that demonstrate various API concepts, functionality, best practices and common usage patterns for the Microsoft.Extensions.AI.Evaluation libraries, explore the API Usage Examples in the dotnet/ai-samples repository. Documentation and tutorials for the evaluation libraries are also available under – The Microsoft.Extensions.AI.Evaluation libraries.
We encourage you to try out these evaluators in your AI applications and share your feedback. If you encounter any issues or have suggestions for improvements, please report them on GitHub. Your feedback helps us continue to enhance the evaluation libraries and build better tools for the .NET AI development community.
Happy evaluating!
Evaluation is such an important part when it comes to building ai applications successfully.. thank you so much for sharing the capabilities in the .net ecosystem to assist with the same