

When building applications that leverage AI, being able to effectively evaluate the responses from an SLM (Small Language Models) or LLM (Large Language Models) has never been more important.
Evaluations refer to the process of assessing the quality and accuracy of responses generated by AI models, such as SLMs or LLMs. This involves using various metrics to measure aspects like relevance, truthfulness, coherence, and completeness of the AI-generated responses. Evaluations are crucial in testing because they help ensure that the AI model performs as expected, providing reliable and accurate results that enhance user experience and satisfaction.
Introducing Microsoft.Extensions.AI.Evaluation, now in preview
We are thrilled to announce the preview release of the Microsoft.Extensions.AI.Evaluation libraries. This addition to the .NET ecosystem is designed to empower developers with advanced tools for evaluating the efficacy of your intelligent applications. The libraries are made up of the following NuGet packages:
- Microsoft.Extensions.AI.Evaluation – Defines the core abstractions and types for supporting evaluation.
- Microsoft.Extensions.AI.Evaluation.Quality – Contains evaluators that can be used to evaluate the quality of LLM responses in your projects including Relevance, Truth, Completeness, Fluency, Coherence, Equivalence and Groundedness. Microsoft.Extensions.AI.Evaluation.Reporting – Contains support for caching LLM responses, storing the results of evaluations and generating reports from that data.
- Microsoft.Extensions.AI.Evaluation.Console – A command line dotnet tool for generating reports and managing evaluation data.
Why Microsoft.Extensions.AI.Evaluation?
Built atop the recently published Microsoft.Extensions.AI abstractions, the Microsoft.Extensions.AI.Evaluation libraries are crafted to simplify the process of evaluating the quality and accuracy of your .NET intelligent applications.
Key Features
Seamless Integration: The libraries are designed to integrate smoothly with existing .NET applications allowing you to leverage existing testing infrastructures and familiar syntax to enable evaluations of your intelligent apps. Use your favorite Testing Framework (e.g., MSTest, xUnit, or NUnit) and testing workflows (Test Explorer, dotnet test, CI/CD pipeline) to evaluate your applications. The library also provides easy ways to do online evaluations of your application through publishing evaluation scores to telemetry and monitoring dashboards.
Comprehensive Evaluation Metrics: Built in collaboration with data science researchers from Microsoft and GitHub, and tested on popular Microsoft Copilot experiences, these libraries provide built-in evaluations for Relevance, Truth, Completeness, Fluency, Coherence, Equivalence and Groundedness. It also provides you with the ability to customize to add your own evaluations.
Cost Savings: With the library’s Response Caching functionality, responses from the AI model are persisted in a cache. In subsequent runs, responses are then served from this cache to enable faster execution and lower cost as long as the request parameters (such as the prompt and model endpoint) remain unchanged.
Extensible and Configurable: Built with flexibility in mind, the libraries allow you to pick the components that you need. For example, if you don’t want response caching, you can go without, and you can tailor reporting to work best in your environment. The libraries also allow for extensive customization and configuration, like adding customized metrics and reporting options, ensuring they can be tailored to meet the specific needs of your project.
Getting Started
Integrating Microsoft.Extensions.AI.Evaluation into your .NET application’s test projects is straightforward. Here’s a quick guide to get you started. You can see the full sample of this in action at the eShopSupport site.
- Add the Microsoft.Extensions.AI.Evaluation NuGet packages to your testing project.
dotnet add package Microsoft.Extensions.AI.Evaluation
dotnet add package Microsoft.Extensions.AI.Evaluation.Quality
dotnet add package Microsoft.Extensions.AI.Evaluation.Reporting- Set up the reporting configuration for your evaluations:
- The reporting configuration defines the set of evaluators that should be included as part of each evaluation. The below example includes five evaluators, four of which (
RelevanceTruthAndCompletenessEvaluator,CoherenceEvaluator,FluencyEvaluator,GroundednessEvaluator) are defined in the Microsoft.Extensions.AI.Evaluation.Quality NuGet package. The fifthAnswerScoringEvaluatoris a custom evaluator that is defined in the test project itself. - The reporting configuration also defines the LLM chat completion endpoint (i.e., the
IChatClient) that should be used for the evaluations. - Want to get a detailed report of how all the latest changes impacted the efficacy of your application? The reporting configuration also defines how evaluation results should be persisted so that you can generate a full HTML report to see regressions and improvements.
- Finally, to help reduce costs, you can also enable caching of your evaluations in the reporting configuration. When response caching is enabled, so long as the request parameters don’t change, your evaluations will use the cached responses from the LLM instead of hitting the LLM every time.
- The reporting configuration defines the set of evaluators that should be included as part of each evaluation. The below example includes five evaluators, four of which (
The below example uses a DiskBasedReportingConfiguration which enables response caching by default, and uses a directory on your disk (StoragePath) to persist both the evaluation results as well as the cached LLM responses.
static ReportingConfiguration GetReportingConfiguration()
{
// Setup and configure the evaluators you would like to utilize for each AI chat.
// AnswerScoringEvaluator is an example of a custom evaluator that can be added, while the others
// are included in the evaluation library.
// Measures the extent to which the model's generated responses are pertinent and directly related to the given queries.
IEvaluator rtcEvaluator =
new RelevanceTruthAndCompletenessEvaluator(
new RelevanceTruthAndCompletenessEvaluator.Options(includeReasoning: true));
// Measures how well the language model can produce output that flows smoothly, reads naturally, and resembles human-like language.
IEvaluator coherenceEvaluator = new CoherenceEvaluator();
// Measures the grammatical proficiency of a generative AI's predicted answer.
IEvaluator fluencyEvaluator = new FluencyEvaluator();
// Measures how well the model's generated answers align with information from the source data
IEvaluator groundednessEvaluator = new GroundednessEvaluator();
// Measures the extent to which the model's retrieved documents are pertinent and directly related to the given queries.
IEvaluator answerScoringEvaluator = new AnswerScoringEvaluator();
var endpoint = new Uri(AzureOpenAIEndpoint);
var oaioptions = new AzureOpenAIClientOptions();
var azureClient = new AzureOpenAIClient(endpoint, new DefaultAzureCredential(), oaioptions);
// Setup the chat client that is used to perform the evaluations
IChatClient chatClient = azureClient.AsChatClient(AzureOpenAIDeploymentName);
Tokenizer tokenizer = TiktokenTokenizer.CreateForModel(AzureOpenAIModelName);
var chatConfig = new ChatConfiguration(chatClient, tokenizer.ToTokenCounter(inputTokenLimit: 6000));
// The DiskBasedReportingConfiguration caches LLM responses to reduce costs and
// increase test run performance.
return DiskBasedReportingConfiguration.Create(
storageRootPath: StorageRootPath,
chatConfiguration: chatConfig,
evaluators: [
rtcEvaluator,
coherenceEvaluator,
fluencyEvaluator,
groundednessEvaluator,
answerScoringEvaluator],
executionName: ExecutionName);
}- A prompt used in your application that you want to evaluate is represented by a scenario in the evaluations library. And each evaluation is represented by a test method. Next, you add the scenarios and test methods you want to evaluate to your test project. Note that scenarios are often run multiple times to gather samples of multiple responses from the application. A “scenario run” refers to one of these samples.
private static async Task EvaluateQuestion(EvalQuestion question, ReportingConfiguration reportingConfiguration, CancellationToken cancellationToken)
{
// Create a new ScenarioRun to represent each evaluation run.
await using ScenarioRun scenario = await reportingConfiguration.CreateScenarioRunAsync($"Question_{question.QuestionId}", cancellationToken: cancellationToken);
// Run the sample through the assistant to generate a response.
var responseItems = await backend!.AssistantChatAsync(new AssistantChatRequest(
question.ProductId,
null,
null,
null,
[new() { IsAssistant = true, Text = question.Question }]),
cancellationToken);
var answerBuilder = new StringBuilder();
await foreach (var item in responseItems)
{
if (item.Type == AssistantChatReplyItemType.AnswerChunk)
{
answerBuilder.Append(item.Text);
}
}
var finalAnswer = answerBuilder.ToString();
// Invoke the evaluators
EvaluationResult evalResult = await scenario.EvaluateAsync(
[new ChatMessage(ChatRole.User, question.Question)],
new ChatMessage(ChatRole.Assistant, finalAnswer),
additionalContext: [new AnswerScoringEvaluator.Context(question.Answer)],
cancellationToken);
// Assert that the evaluator was able to successfully generate an analysis
Assert.False(evalResult.Metrics.Values.Any(m => m.Interpretation?.Rating == EvaluationRating.Inconclusive), "Model response was inconclusive");
// Assert that the evaluators did not report any diagnostic errors
Assert.False(evalResult.ContainsDiagnostics(d => d.Severity == EvaluationDiagnosticSeverity.Error), "Evaluation had errors.");
}[Fact]
public async Task EvaluateQuestion_Summit3000TrekkingBackpackStrapAdjustment()
{
// This is the example question and answer that will be evaluated.
var question = new EvalQuestion
{
QuestionId = 3,
ProductId = 99,
Question = "Hi there, I recently purchased the Summit 3000 Trekking Backpack and I\u0027m having issues with the strap adjustment. Can you provide me with the specified torque value for the strap adjustment bolts?",
Answer = "15-20 Nm"
};
// Construct a reporting configuration to support the evaluation
var reportingConfiguration = GetReportingConfiguration();
// Run an evaluation pass and record the results to the cache folder
await EvaluateQuestion(question, reportingConfiguration, 0, CancellationToken.None);
}View the Results
Once you are set up, you can run the tests in Test Explorer to see the results in your local environment.
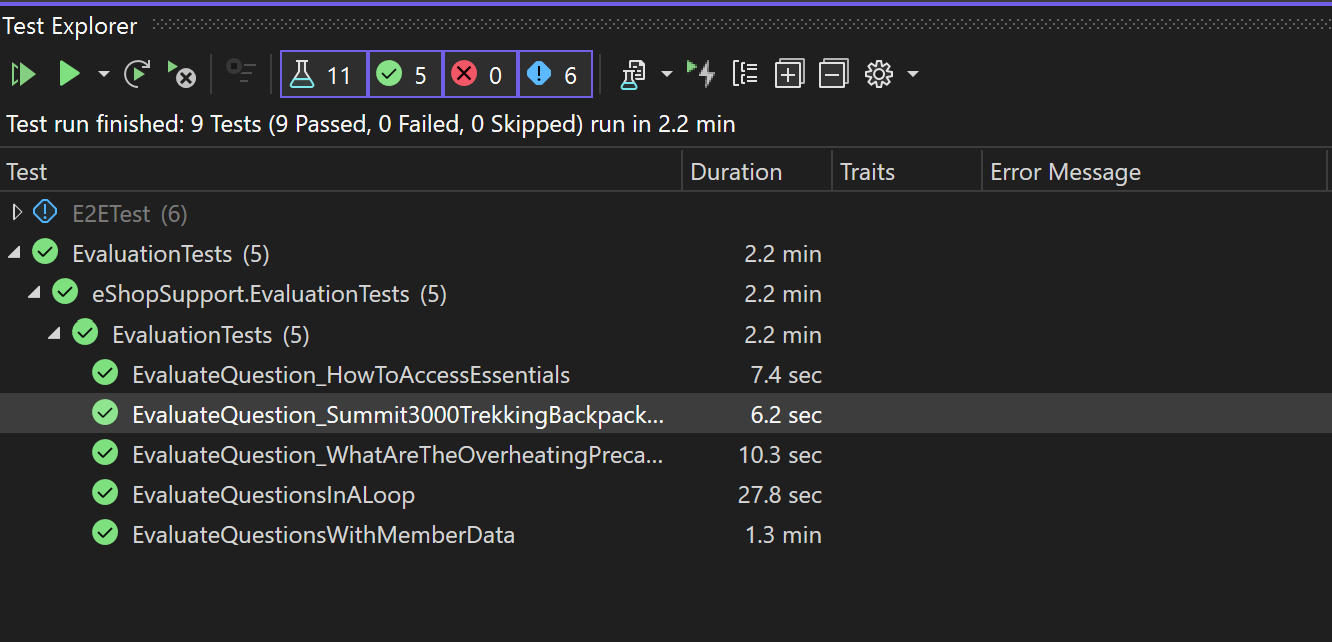
You can also set up the test project to run in CLI with the dotnet tool.
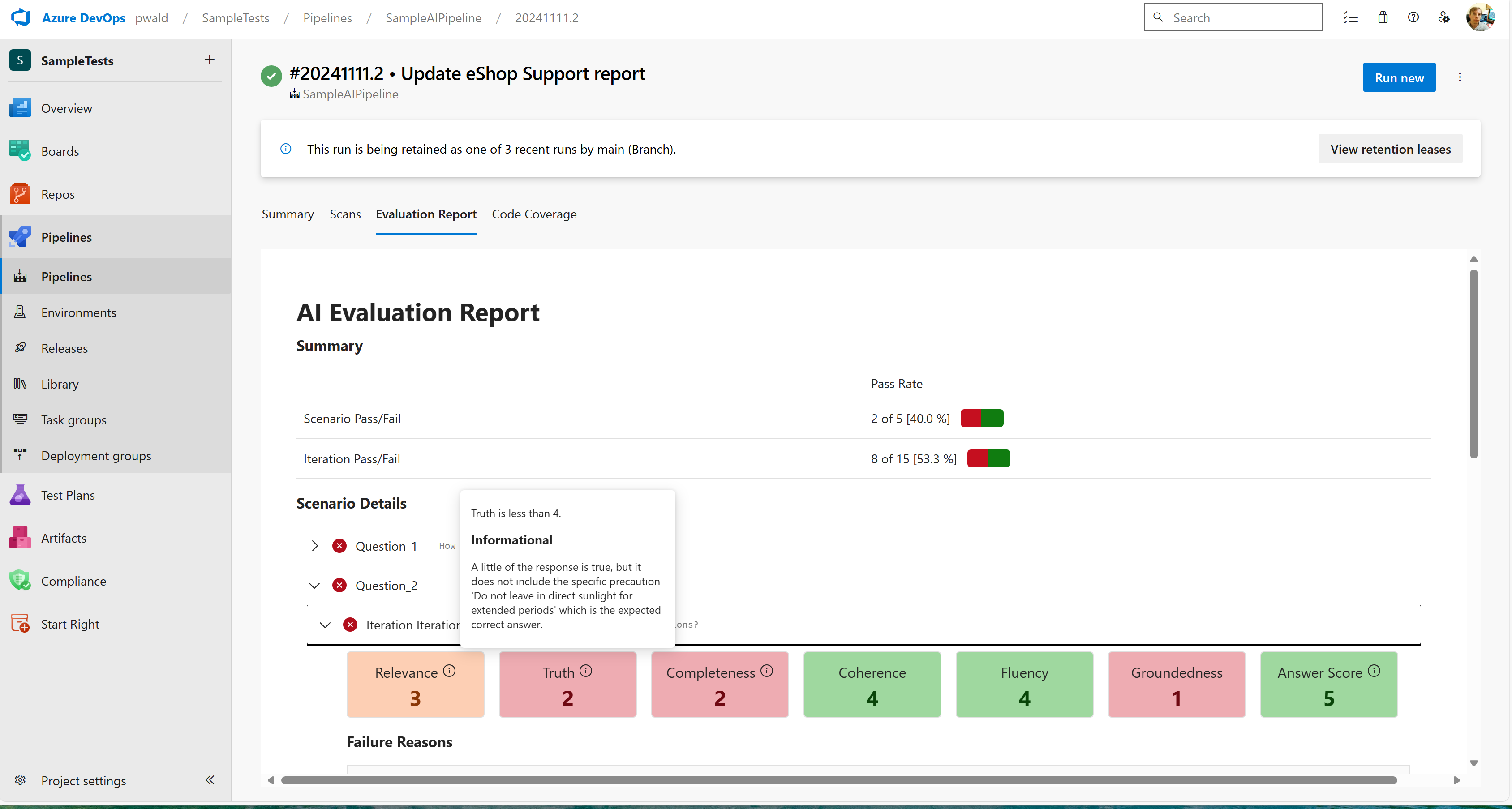
To generate a report for your last evaluation run, use the following dotnet tool on the command line.
dotnet tool install Microsoft.Extensions.AI.Evaluation.Console
dotnet aieval report --path <path\to\my\cache\storage> --output report.htmlMore samples
For a comprehensive tour of all the functionality, concepts and APIs available in the Microsoft.Extensions.AI.Evaluation libraries, check out the API Usage Examples available in the dotnet/ai-samples repo. These examples are structured as a collection of unit tests. Each unit test showcases a specific concept or API, and builds on the concepts and APIs showcased in previous unit tests.
Join the Preview
We believe these libraries will open new possibilities for integrating AI into your applications, driving innovation, and delivering impactful solutions.
We invite you to explore the new Microsoft.Extensions.AI.Evaluation preview libraries. If you have any difficulties or find something is missing from the experience, share your feedback. Your insights are invaluable as we continue to refine and enhance these tools. Join us in this exciting journey and help shape the future of AI in .NET.
Really very interesting!