


I created my first graphic in 1981 using a language called “BASIC” on a computer by Texas Instruments called the TI-99/4A. The code to enter and run BASIC, by the way, was written by a new company at the time named Microsoft. In July of 1991, a program called “POV-Ray” was released that made it possible to render complex 3D scenes using a domain specific language. I tried writing my own software in the past and decided that I just didn’t want to invest in the learning the complex math involved with rendering in three dimensions. POV Ray empowered me to create complex 3D illustrations. The only catch: some of my scenes could take over 24 hours to render, so I had to time it for days when I didn’t need the computer for other tasks. Oh, and I had to learn the specific domain language POV used to render its scenes.
Fast forward to today, and AI now empowers us to create incredibly detailed scenes simply by describing them using natural language. It is a game-changing feature and makes it possible for anyone to create diagrams, art, and educational visuals. For developers, it makes it possible to create experiences that were simply too costly to tackle in the past. As is “par for the course” with many software development kits (SDKs), especially those in the Artificial Intelligence realm, the SDKs to create images and underlying capabilities vary from provider to provider.
As part of our ongoing work to provide a common and universal interface for interacting with large language models and agents in .NET, the AI extensions team has been actively developing and refining text-to-image abstractions and are exploring other modalities (in the context of AI, modalities are forms of input and output the agent or LLM can consume and/or produce). The text-to-image capabilities are designed to empower developers to generate images from natural language prompts and/or existing images using a consistent and extensible API surface. When you encounter “MEAI” in this post, it is a reference to all APIs available in Microsoft.Extensions.AI and related packages.
Why Text-to-Image?
Text-to-image generation unlocks a wide range of scenarios:
- Marketing: Automatically generate visuals for campaign assets.
- Education: Create diagrams or illustrations from lesson plans.
- Accessibility: Convert textual descriptions into visual content.
- Prototyping: Rapidly visualize UI concepts or product ideas.
Additional tasks include:
- Refining the image generated from an initial prompt iteratively until satisfied
- Editing an existing image
- Personalizing an image, diagram, or theme
- Merging multiple images into a single one, such as putting a character into a scene or a package into a diagram
Of course, there may be other use cases and reasons to use this modality. We’re curious about what modalities you are using, how you are using them, and how we can provide you with the best possible experience for writing code the uses them. If you have a moment, we’d love to hear your thoughts, so please take a moment to fill out our AI Modalities in .NET survey.
Why bother with abstractions?
As we continue to expand the capabilities of AI across the .NET ecosystem, the integration of modalities (such as text, speech, image, and video) demands a consistent and scalable developer experience. MEAI provides a unified abstraction layer that simplifies how developers interact with diverse AI services. By standardizing APIs for modalities, MEAI enables:
- Plug-and-Play Modality Support: Developers can easily integrate new modalities via adapters without rewriting core logic. This abstraction allows seamless transitions between providers like Azure AI, OpenAI, and ONNX Runtime.
- Provider-Agnostic Interoperability: Whether you’re using Azure AI Inference, Copilot Studio, or third-party SDKs, MEAI ensures consistent interfaces across services. This reduces friction and accelerates adoption.
- Extensibility and Ecosystem Growth: MEAI empowers SDK authors and app developers to contribute new modalities and tools, fostering a vibrant ecosystem of reusable components.
- Accelerated Innovation: By abstracting common patterns like chat, embeddings, and streaming, MEAI allows teams to focus on building differentiated experiences rather than reinventing infrastructure.
This approach is already informing our work across Teams AI, Azure AI Foundry, and the Agent Framework. We intend MEAI to be the foundation for scalable, interoperable, and future-proof AI development in .NET. The goal is to streamline and simplify your development, so if it’s not accomplishing the goal or, worst case, adding more complexity or overhead to your processes, please let us know so we can understand why and address it as quickly as possible.
How to Get Started
The text-to-image feature is built into the latest preview of the Microsoft.Extensions.AI package. Let’s start with a simple console example.
The Text2ImageSample demonstrates an automated process that takes two pieces of input (your Azure Open AI endpoint and an image that is expected to be of a person) and generates a sequence of images. It is intended to show two variations of the text-to-image modality: image generation and image modification.
A practical example of this might be using the user’s description of a room to place a painting in the room so they can visualize how it will fit in the space. The same could be done for furniture. The point is that not all interactions have to take place through chat.
The main structure of the program is a workflow that executes sequential steps until completed. The main thread has no affinity to a specific provider, but instead takes a dependency on the IChatClient and IImageGenerator abstractions provided by the extensions for AI. This simplification gives you a very consistent and easy-to-use model for interacting with agents despite their abilities (or limitations) provided they either support the Microsoft Extensions for AI, or have an adapter. In this case, we’re using the Open AI adapter.
The building blocks of transactions with agents in M.E.A.I. are the xxxContent types that include TextContent and DataContent. By using these primitives, the adapter or SDK can determine if and how to translate the content for their own use.
Use MEAI abstractions to generate images
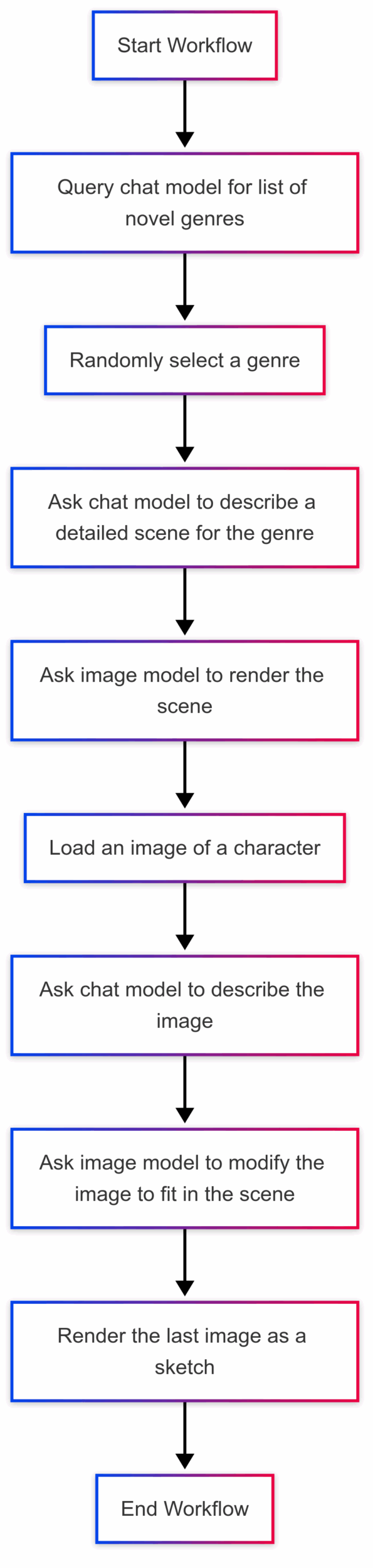
The sample application runs a sequential workflow:
- It queries the chat model for a list of genres for a novel. The novel part is important because otherwise I often get back music genres instead.
- It randomly selects a genre.
- It asks the chat model to describe a detailed scene that fits the genre.
- It asks the image model to render the scene.
- It loads an image you specify of a “character.”
- It asks the chat model to describe the image.
- It asks the image model to modify the image to fit in the scene.
- Finally, it renders the last image as a sketch.
The generic image client is accessible via the IImageGenerator interface. You can obtain an instance in a similar fashion to the way you “cast” a provider’s proprietary chat client into the generic IChatClient using our extension methods.
IImageGenerator openAiGenerator = openAi.GetImageClient("my-image-model").AsIImageGenerator();You can achieve “text-to-image” by passing your eloquent description of an item or scene to the image generator. You will receive the data back in an DataContext container.
DataContent imageBytes =
(await imageGenerator.GenerateImagesAsync("Draw me something so amazing it can't be described.")).ContentsOfType<DataContent>().First();When I receive the image from the image generator, I save it to disk by inspecting the mime type and then streaming the bytes. This is done in the SaveImage method of the Renderer class:
private string SaveImage(
DataContent content,
string name)
{
var extension = content.MediaType.Split(@"/")[1];
var path = Path.Combine(
baseDirectory,
$"{name}.{extension}");
File.WriteAllBytes(path, content.Data.ToArray());
return Path.GetFileName(path);
}File extensions
Not all MIME types map cleanly to file extensions. You may need to use a dictionary lookup or other means if you support more than a few basic image types.For my testing, I provided an image of me breaking the rack in a pool game. It’s an extremely low resolution image because I don’t like spending too many tokens!

The LLM provided a list of genres and we randomly selected “Drama.” ChatGPT then generated this description:
Agent: Nestled in a remote valley surrounded by towering, jagged mountains, lies a secluded locale known as the Vale of Echoes. This breathtaking landscape serves as the heart of the drama, a place where emotions resonate amidst nature’s relentless beauty. The entire setting is shrouded in a perpetual golden hour, where the sun hangs low on the horizon, casting a warm, diffused light across the terrain that imbues everything with a sense of nostalgia and urgency. The valley is ringed by ancient trees with gnarled roots that twist above ground, their bark a tapestry of deep browns and mossy greens. These trees loom like silent sentinels, their leaves whispering secrets to the wind. The foliage is vibrant, ranging from vivid crimson and amber in the fall to lush emerald in spring, each season painting the valley in a palette that ebbs and flows with the narrative’s mood. Here, sunlight dapples through the branches, creating shifting patterns of light and shadows that dance across the soft, forest floor carpeted with wildflowers that bloom in an array of colors, their intoxicating fragrance hanging in the air. At the center of the vale, a crystalline lake glimmers, its surface like a vast mirror reflecting the peaks above and the ever-changing sky. The water is a deep azure, so clear that you can see the smooth pebbles of its bed and the occasional darting silver fish. It is said that the lake has mystical properties; those who gaze into its depths often confront their innermost truths, and the water’s gentle lapping mimics the heartbeat of the earth, resonating with the emotions present in the air. Cascading from one side of the vale is a waterfall that plunges down from an elevated cliff rich with cascading vines and vibrant moss. The water tumbles in silken ribbons, creating a fine mist that hangs in the air and creates rainbows on sunny days. Beneath its spray is a small stone alcove cloaked in emerald ferns, often used as a refuge or a place of contemplation. The sound of the waterfall blends with the soft chirping of birds and the rustling of leaves, creating a symphony of nature that envelops the vale. Scattered throughout the landscape are majestic rock formations, each uniquely shaped and often resembling the forms of human figures in agonizing poses, as if they eternally suffer from emotions unresolved. These formations serve as natural sculptures, inviting characters to engage with their surroundings, explore their inner turmoil, and reflect on their journeys. Along the edges of the vale, meandering trails weave through thickets and into hidden clearings, each one offering a new perspective of this extraordinary landscape. Some paths lead to ancient stone ruins, long forgotten remnants of a civilization that revered the land but vanished under the weight of their own dramas. Moss-covered altars and crumbled walls invite you to ponder stories untold, adding an air of mystery and history. Wildlife thrives here in harmony with the land, including elusive foxes with russet coats, great horned owls that hoot softly at night, and iridescent butterflies that flit through the air like living jewels. The occasional deer can be seen grazing near the lake’s edge, their graceful movements contrasting with the heavy stillness that envelops the vale, creating a palpable tension between serenity and the unresolved stories that linger in the very soil. The Vale of Echoes is not simply a location; it is a character in its own right, a vivid backdrop that mirrors the tumultuous emotions and complexities of the narrative unfolding within its embrace. Here, every corner offers a canvas for reflection, confrontation, and perhaps, ultimately, resolution.
The image generator created this scene from the description you just read:

From there, the example moves from image generation using a text prompt to editing an existing image by combining it with a prompt.
Tip
An interesting exercise would be to ask the model to describe the generated scene then compare the description with the original prompt used to create the image.Edit an existing image
It’s possible to take an existing image, then combine it with a prompt and receive an edited version. Passing an image to the prompt is as simple as loading the bytes and content type into a DataContent container and then passing it to the IImageGenerator via the EditImageAsync method.
DataContent original = new DataContent();
DataContent variation = (await myImageGenerator.EditImageAsync(
Context.Character!,
$"The source image should contain a person. Create a new image that transforms the person into a character in a {Context.Genre} novel. They should be doing something interesting/productive in this location: {Context.SceneDescription}", cancellationToken: ct);
Context.ModifiedCharacter = variation.Contents.OfType<DataContent>().First();📣 Call for Feedback
We’re reaching out to internal teams and external partners to understand:
- Use cases for text-to-image and other modalities
- Preferred models and providers
- Business scenarios driving adoption
If you’re using agents for multimodal tasks—whether in .NET or another platform — we’d love to hear from you. Your feedback will help shape the future of MEAI and ensure we support the right abstractions and workflows.
Shape the future of Microsoft’s extensions for AI in .NET
🧪 What’s Next?
Text-to-image is just the beginning. Our team is also exploring:
- Image-to-image: Style transfer, enhancement, transformation
- Image-to-video: Animation and synthesis pipelines
- Text-to-speech: Real-time streaming with Azure Speech and others
- Speech-to-text: Transcription and voice command support
We’re building a modality matrix to track coverage across providers and ensure our abstractions are aligned with real-world needs. Stay tuned for upcoming blog posts, samples, and surveys, and please, let us know what you think!
It seems the example in the “Edit-an-existing-image” section is not using the variable named original. I think it should be passed to EditImageAsync() method instead of the Context.Character!.
It would have been nice if the repo used a model that didn’t require the dev to request access from Microsoft before using. Use a model that is readily available for all to use. Thanks