
Customer Impact:
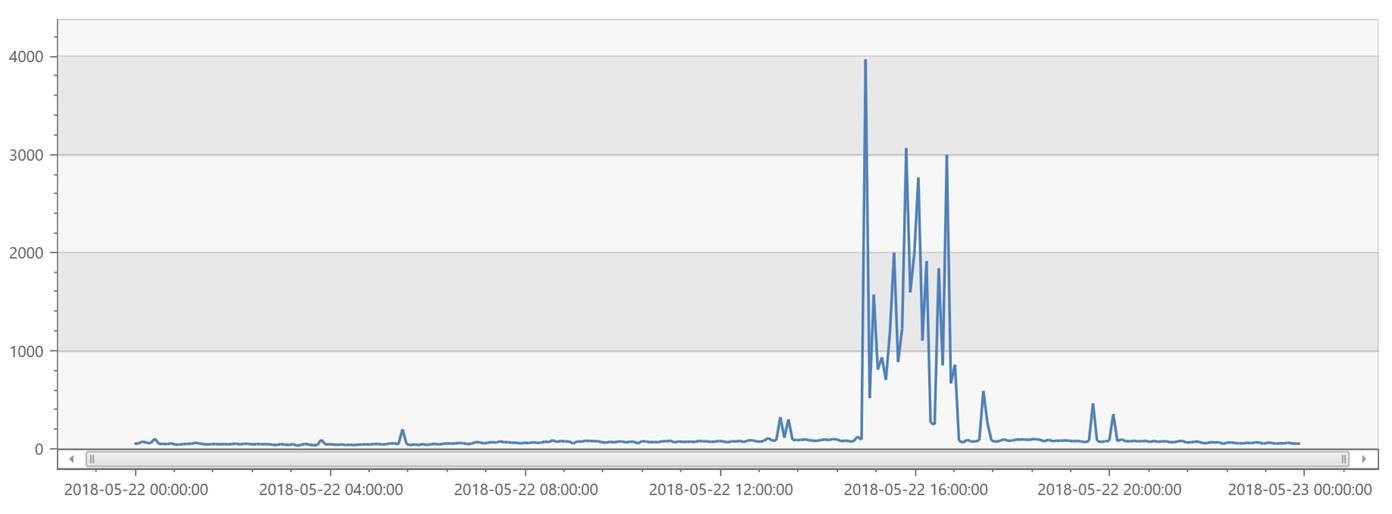
On 22 May 2018, Visual Studio Team Services (VSTS) experienced a major incident across multiple regions between 15:00 and 16:55 UTC. An event in a Western European scale unit of the Team Foundation Service (TFS), caused a chain reaction that sporadically took other TFS scale units offline in other regions. Based on our telemetry, we estimate a total of 20,800 users were impacted during the incident.
Impacted Users over time
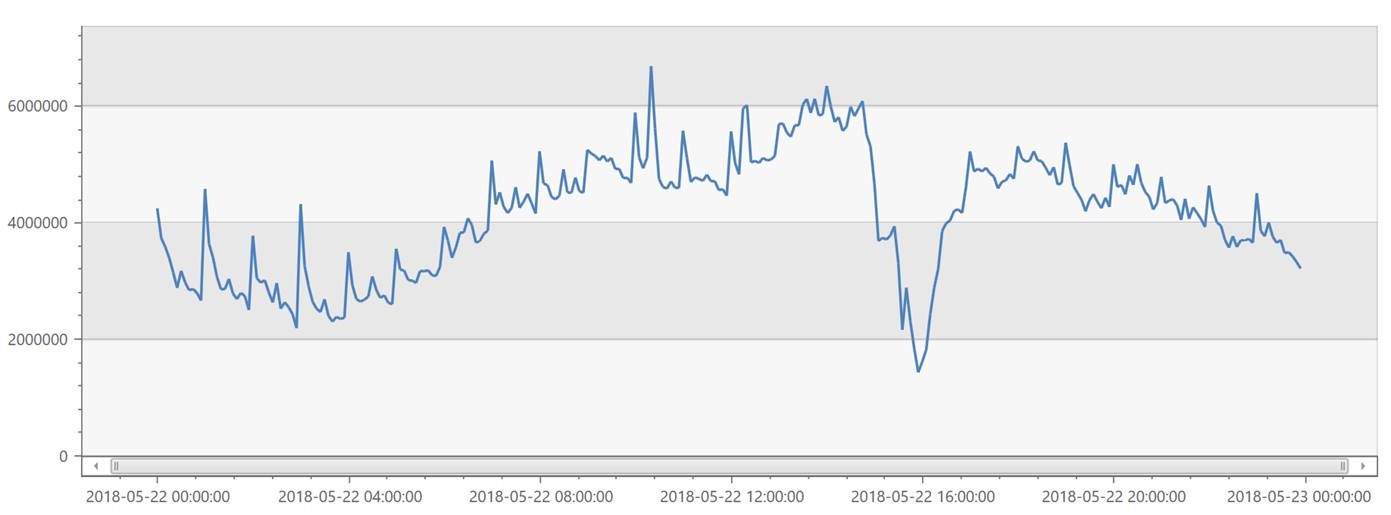
Total request volume over time
What Happened:
First, some background on a few components in VSTS.
- Request routing – we use Azure Front Door (AFD), an internal version of Azure CDN, to route initial requests to VSTS accounts as illustrated below:

{kind=link}
In the example:
- A user visits their account at {account}.visualstudio.com for the first time
- AFD sends the request to the scale unit with the least latency since it does not know which scale unit contains the data which can serve the request.
- That scale unit recognizes that the account lives on another scale unit and we use Application Request Routing to proxy the request.
- In the response we send headers which AFD caches, causing subsequent requests for that account to go directly to the correct scale unit, avoiding the proxy.
- Resource utilization – We also have a resource utilization service running on all TFS scale units which throttles or blocks unusually high volumes of requests. This includes a concurrent request limit on unauthenticated requests to ensure anonymous traffic cannot overwhelm the service.
- Load balancer probes – these are probes which the Azure software load balancer uses to determine the health of our application tiers (ATs). Additionally, AFD uses the same probes to determine whether a scale unit is healthy.
So, with that in mind, here’s what happened:
At 14:58 UTC, we updated the application tiers (ATs) on tfs-weu-2, a TFS scale unit, as part of a routine deployment. Two minutes later those ATs stopped taking traffic. At 15:10, the newly deployed ATs were rolled back based on automated deployment health checks.
Normally, that would have been the end of it. However, our routing configuration in AFD states that when one scale unit is unhealthy (as determined by AFD’s own health check requests), traffic will be routed to a different healthy scale unit. This is one of the contributing causes of our incident. When tfs-weu-2 was unhealthy and failing the AFD health checks, AFD began sending traffic to other scale units. Those scale units then used ARR to proxy the requests back to tfs-weu-2.
While this routing behavior works well for stateless services, it’s not good for a stateful service like VSTS. Still, it should not impact other scale units.
Unfortunately, our resource utilization service treated both the ARR requests and the load balancer health probes as anonymous requests. Given that the ARR requests were slow due to tfs-weu-2 being unavailable, we quickly hit the concurrent request limit and started returning a 429 response code for new ARR requests and the load balancer health probes. As soon as the load balancer and AFD received a few failed responses, they considered the ATs and scale unit offline and re-routed traffic to another scale unit. The new scale unit began to proxy a large amount of traffic, causing resource utilization to kick in and repeat the cycle. This mechanism led to a chain reaction as the proxied traffic spread across all of our scale units.
This was mitigated by disabling the blocking threshold for concurrent anonymous requests, which allowed the health checks to succeed reliably and requests to be processed. Initially, a broad mitigation was applied to a single scale unit at 16:08 UTC. After the behavior was better understood, all other scale units received a more scoped mitigation beginning at 16:21.
Next Steps:
We learned many things from this incident and are taking steps to ensure it will not reoccur:
- Health checks and ARR proxied traffic should not be held to the same throttling behaviors and thresholds as normal user traffic. The health check was updated in production later that day and the ARR changes will be deployed shortly.
- As a general principle, one unhealthy scale unit should not trigger more traffic to another. We are updating our AFD configuration to not re-route traffic when a scale unit is unavailable.
- It took longer than it should have to mitigate this in part due to the widespread nature of the impact across scale units. We are improving our tooling to expedite config changes like these.
- Once we have the critical fixes in place, we will verify the improvements through fault testing. We will issue alerts when ATs are unexpectedly taken out of the load balancer.
Also, we are still investigating what caused the original failure on tfs-weu-2 and will post an update to this postmortem when it’s better understood.
We recognize the significant impact this has on teams that rely on VSTS and sincerely apologize for this incident.
Sincerely, Chandru Ramakrishnan Group Engineering Manager, VSTS platform team
0 comments