
When I became a Program Manager, I gave up writing software for a living. So I did what many programmers do when faced with such a dilemma: I started working on open source software in my spare time. One of the projects that I work on is called libgit2.
You might not have heard of libgit2; despite that, you’ve almost certainly used it. libgit2 is the Git repository management library that powers many graphical Git clients, dozens of tools, and all the major Git hosting providers. Whether you host your code on GitHub, Azure Repos, or somewhere else, it’s libgit2 that merges your pull requests.
This is a big responsibility for a small open source project: keeping our code working and well-tested is critical to making sure that we keep your code working and well-tested. Bugs in our code would mean that your code doesn’t get merged. Keeping our continuous integration setup efficient and operational is critical to keeping our development velocity high while maintaining confidence in our code.
That’s why libgit2 relies on Azure Pipelines for our builds.
Here’s my five favorite things about Azure Pipelines for open source projects. Some of these are unique to Azure Pipelines, some are not, but all of them help me maintain my projects.
One Service, Every Platform
libgit2 tries to support many architectures and operating systems, but we have three “core” platforms that we want our master branch to always build on: Linux, Windows and macOS. This has always been a challenge for continuous integration build systems.

The libgit2 project originally did its CI on some Jenkins servers that were donated by GitHub from their internal build farm. The build machine was called “janky” and it’s hard to imagine a more appropriate name since we could only get a green checkmark on success or a red X on failure. Since this was an internal build server, open source contributors weren’t authorized to get the full build logs.
Eventually we moved over to Travis so that we could get more insight into build and test runs. This was a big step up, but it was Linux only. Inevitably someone would check in some code that worked great on Linux but called some function that didn’t exist in Win32. So then we added AppVeyor to the mix for our Windows builds, and this also seemed like a big step up.
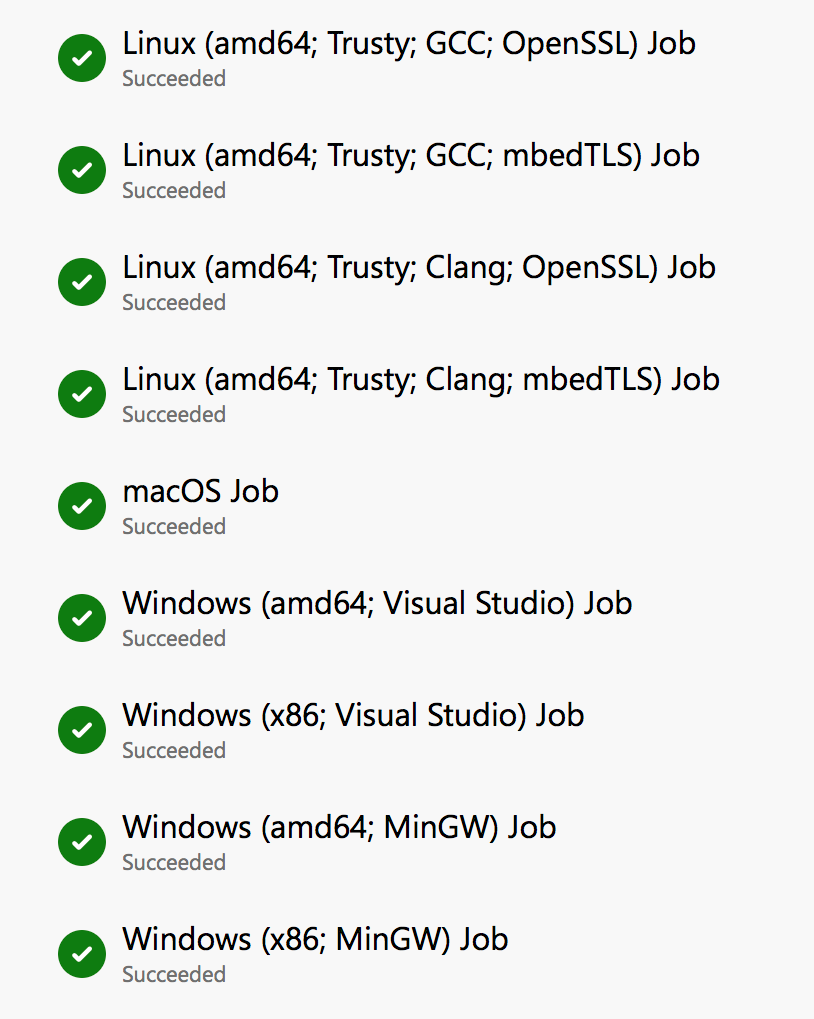
But it didn’t take long before we realized that having two different systems meant doing more than three times as much work on our infrastructure trying to coordinate the configuration and communication between them. And we were paying two different bills, trying to get the fastest builds that we could afford on donations into our shoestring budget. Over time, our CI configuration became incredibly frustrating and not really what I wanted to be working on in my free time hacking on open source. So when we were finally given the option to standardize on a single build system in Azure Pipelines, we jumped at it.
When we moved over to Azure Pipelines, we got a single source of truth for all our platforms. Linux, Windows and macOS, all hosted in the cloud, all offered in a single service. It simplified everything. There’s one configuration. One output to look at. One set of artifacts produced. One bill at the end of the month. Well, actually, there’s not, because…
Unlimited Build Minutes; 10 Parallel Pipelines; Zero charge
Azure Pipelines has a generous offer for open source projects: unlimited build minutes across 10 parallel build pipelines. All for free.
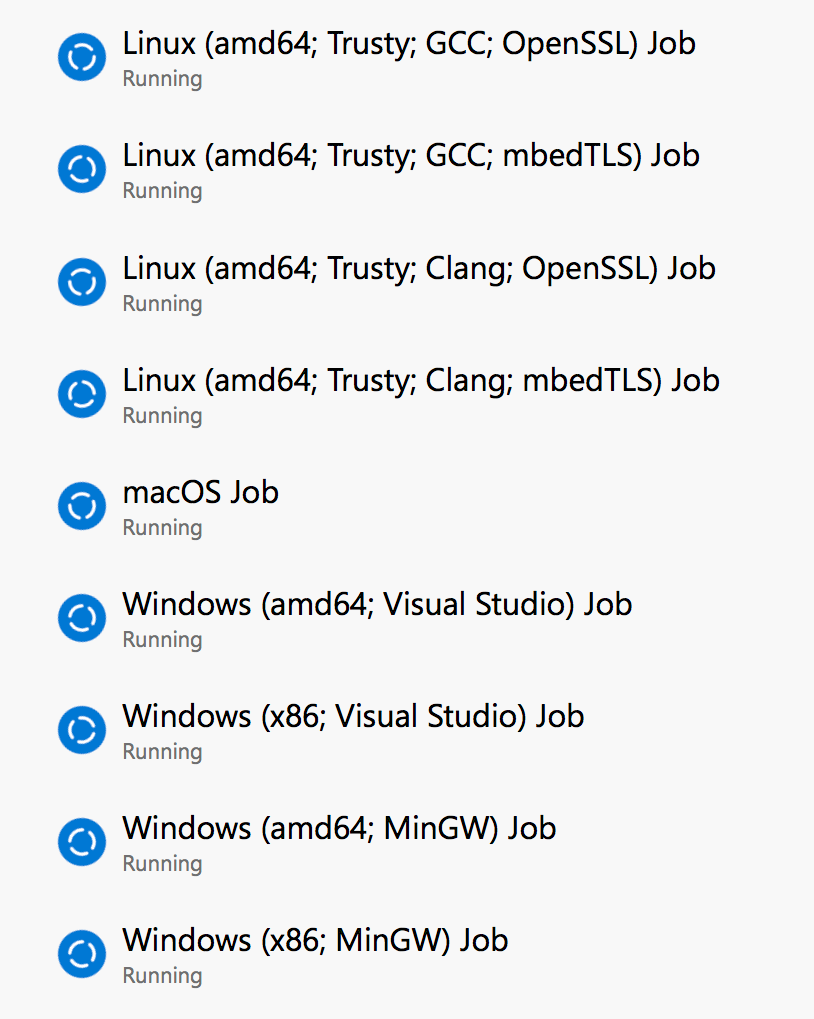
Having 10 concurrent build pipelines is incredible for libgit2, since we want to build on so many different platforms. Although we only have those three “core” targets that we want to target on every pull request build, there are actually small variances that we want to cover. For example, we want to target both x86 and amd64 architectures on Windows. We want to make sure that we build in gcc, clang, MSVC and mingw. And we want to build with both OpenSSL and mbedTLS.
Ultimately that means that we run nine builds to validate every pull request. This is actually more validation builds than we used to run with our old Travis and AppVeyor, and thanks to all that parallelism it’s much, much faster. We used to get just a few parallel builds running and long queue times, so when many contributors were working on their pull requests, tweaking and responding to feedback, it took an achingly long time to get validation builds done. And we were paying for that privilege.
Now we get almost instant start times and all nine builds running in parallel. And it’s free.
Scheduling Builds
If you were thinking that running nine builds on every pull request was a lot… I’m afraid that I have to disagree with you. Those nine builds just cover those core platforms: several Linux builds, a handful of Windows builds, and one for macOS. And those give us a reasonably high confidence in the quality of pull requests and the current state of the master branch.
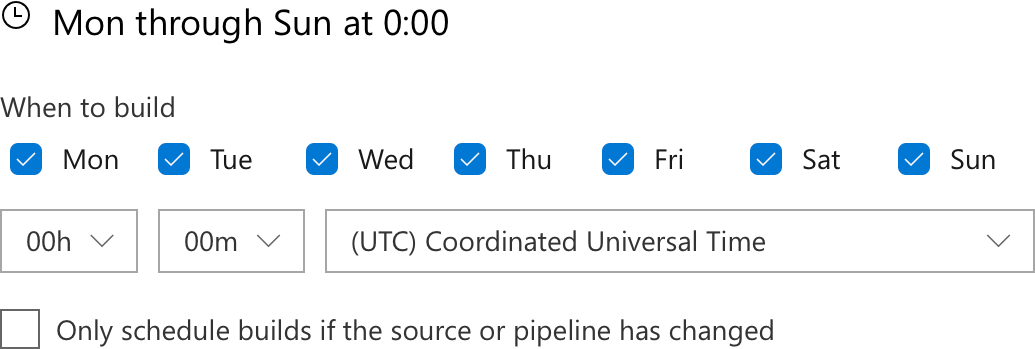
But always, we want more. Otherwise you might forget that on ARM platforms, chars are signed by default, unlike most other processors. Or that SPARC is aggressive about enforcing alignment. There are too many crazy little variances in other platforms that are hard to remember, that only show up when you run a build and test pass. So build and test we must, or else we accidentally ship a release that fails on those platforms.
But these platforms are sufficiently uncommon, and their idiosyncrasies mild enough that we don’t need to build every single pull request; it’s sufficient for us to build daily. So every night we queue up another fourteen builds, running on even more platforms, executing the long-running tests, and performing static code analysis.
This setup gives us a good balance between getting a quick result when validating the core platforms all the time, but still making sure we are validating all the platforms daily.
Publishing Test Results
When contributors push up a pull request, they often want more than just a simple result telling them whether the build succeeded or failed. When tests fail, especially, it’s good to get more insight into which ones passed and which didn’t.

If your test framework outputs a test results file, you can probably upload it to Azure Pipelines, where it can provide you a visualization of your tests. Azure Pipelines supports a bunch of formats: JUnit, NUnit (versions 2 and 3), Visual Studio Test (TRX), and xUnit 2. JUnit, in particular, is very commonly used across multiple build tools and languages.
All you have to do is add an “upload test results” task to your pipeline. You can either do that with the visual designer, or if you use YAML:
- task: PublishTestResults@2
displayName: Publish Test Results
condition: succeededOrFailed()
inputs:
testResultsFiles: 'results_*.xml'
searchFolder: '$(Build.BinariesDirectory)'
mergeTestResults: true
Now when you view a build, you can click on the Tests tab to see the test results. If there are any failures, you can click through to get the details.
Build Badges

Publishing test results give contributors great visibility into the low-level, nitty-gritty details of the test passes. But users of the project and would-be new contributors want a much higher-level view of the project’s health. They don’t care if the ssh tests are being skipped, they usually care about a much more binary proposition: does it build? Yes or no?
Build badges give a simple view of whether your build pipeline is running or not. And you can set up a different badge for each pipeline. If you have builds set up on maintenance branches, you can show each of them. If you’re running a scheduled or nightly build, you can show a badge for that.
It’s simple to add a build badge to your project’s README. In your build pipeline in Azure Pipelines, just click the ellipses (“…”) menu, and select Status Badge. From there, you’ll get the markdown that you can place directly in your README.
Want to tweak it? You can change the label that gets displayed in the build badge. This is especially helpful if you have multiple builds and multiple badges. Just add ?label=MyLabel to the end of the build badge URL.
Getting Started
These five helpful tips will help you use Azure Pipelines to maintain your project. If you’re not using Azure Pipelines yet, it’s easy – and free – for open source projects. To get started, just visit https://azure.com/pipelines.
0 comments