

In the fast-paced world of software development, the ability to swiftly and accurately translate client needs into tangible product features is a critical success factor. This process begins with the often-detailed discussions and conversations that help define project requirements. However, managing and extracting actionable insights from these discussions can be a time-consuming and error-prone task.
But what if you could streamline and automate this process, saving both time and resources while ensuring a higher degree of precision? Welcome to the world of end-to-end automation, where we bridge the gap from requirement discussion transcripts to Azure DevOps features.
In this blog, we’ll embark on a journey through a well-structured folder system, equipped with historical data, custom skills, and project-related information. We’ll explore the seamless integration of these components, guided by a comprehensive Jupyter Notebook, to automate the generation of Azure DevOps features. This isn’t just about saving time; it’s about transforming the way we approach requirement management.
Join us as we unravel the power of automation, unlocking efficiency, accuracy, and a whole new level of agility in the software development process. Get ready to discover how you can transition from lengthy discussions to tangible Azure DevOps features with ease. It’s time to revolutionize your development pipeline and put automation at the heart of your success.
Let’s embark on this exciting journey, where technology meets innovation, and automation becomes your secret weapon for software development excellence.
Pre-requisite
- Visual studio code
Please install the extension below.
– Jupyter (Publisher- Microsoft)
– Python (Publisher- Microsoft)
– Pylance (Publisher- Microsoft)
– Semantic Kernel Tools (Publisher- Microsoft)
- Python
Please install the packages below.
- PIP
- Semantic-kernel
- Azure DevOps
Download the content of repo.
Process flow for End-to-end requirement gather process using OpenAI and Semantic kernel
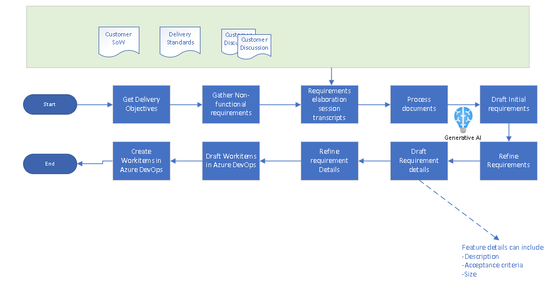
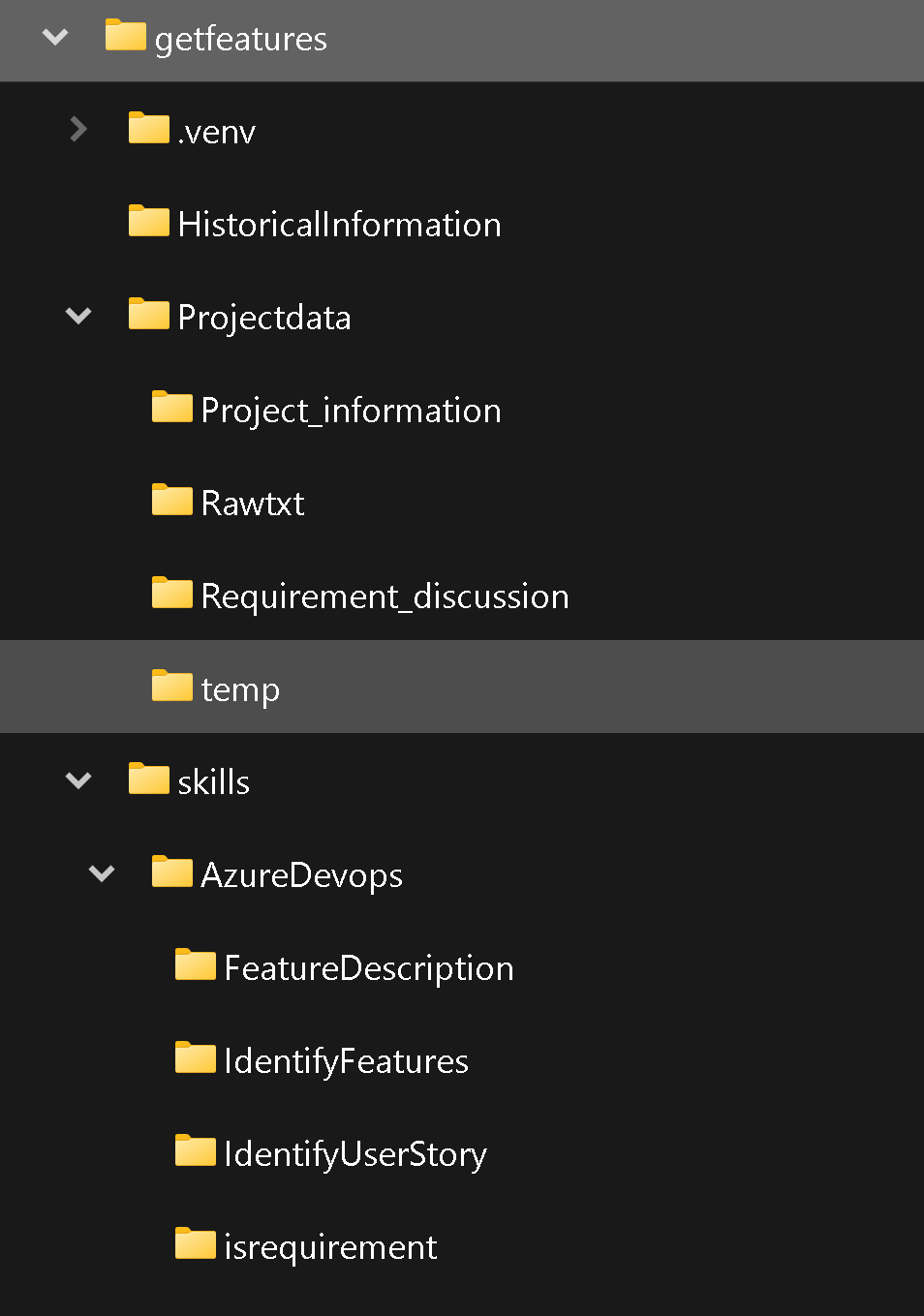
Folder structure
The folder structure you’ve described seems to be organized for managing historical information, skills, and project-related data for an automated requirement generation system within Azure DevOps. Here’s a detailed breakdown of the structure:
Root (Root folder containing all subfolders and files)
– HistoricalInformation (Contains historical data of features, descriptions, and acceptance criteria for previous projects)
– Feature_data.csv (A CSV storage for past information, possibly obtained from various data sources)
– Skills (Folder for storing custom skills used in requirement generation)
– AzureDevops (Specific skills related to Azure DevOps)
– FeatureDescription (Contains semantic functions for generating feature descriptions and acceptance criteria based on predefined templates)
– IdentifyFeature (Semantic function for identifying features or requirements in a given text)
– isRequirement (Semantic function to check if a string contains a requirement)
– native_function.py (Possibly a script or module for native functions, but marked as “Not used”)
– Projectdata (Folder containing data related to specific projects)
– Project_information (Contains reference information used in addition to discussion transcripts for identifying requirements)
– Customer_objective.txt (Contains the objectives the customer or company wants to achieve with the project)
– NFR.txt (Non-functional requirements for the project, even if not discussed)
– project_objective.txt (Contains the project sponsor’s objectives)
– Rawtxt (A folder where you place all the required discussion transcripts)
– Requirement_discussion (A folder used by scripts to store finalized sub-transcripts that are less than 3000 characters and contain requirements)
– temp (Temporary folder used for storing all transcripts generated as part of the transcript splitting process)
– End-to-end-requirement-genration-in-AzureDevops.ipynb (A Jupyter Notebook that integrates and orchestrates the various components for end-to-end requirement generation in Azure DevOps)
This structure seems well-organized and suitable for a system that automates requirement generation using historical data, custom skills, and project-related information within the context of Azure DevOps.
Information gathering
The output of these steps is all the relevant information which can directly or indirectly contribute to project success.
- Get Delivery Objectives (store the information in Root\Projectdata\Project_information\Customer_objective.txt and project_objective.txt)
- Gather Non-functional requirements (store the information in Root\Projectdata\Project_information\NFR.txt)
- Requirements elaboration session transcripts (Store the transcripts inside Root\Projectdata\Rawtxt)
Once you have this information you can start with document processing by performing the above-mentioned steps
Document processing
The objective of these steps is to reduce the size of documents to limited documents which actual contains requirement information.
The output of this step is to get all the sub transcripts containing requirement in Root\Projectdata\Requirement_discussion\ folder.
- Read raw discussion document from “Rawtxt” folders.
- Breaking big discussion transcripts into smaller transcripts of size 3000 character.
- Put them in temp folder
- Check whether the subpart of the discussion contains requirement or not.
- It contains requirement put into “Requirement_discussion” folder.
- Import historical feature data in memory.
Covered in steps 1 to 7.
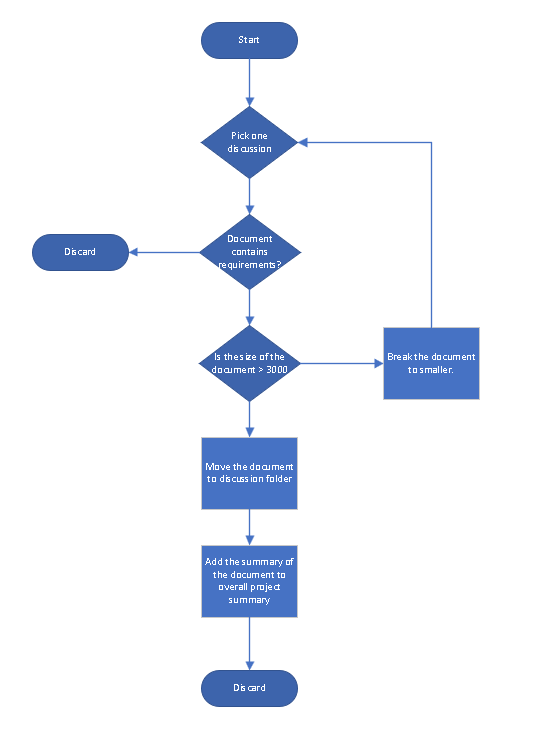
Once you have the list of documents which contains requirement, we can proceed further with feature identification.
Requirement identification and refinement
The objective of this process is to identify and groom features and make them ready for importing into Azure DevOps.The output of this step is finalized list of features and their details.
- Identify features from Proceed transcript.
- Remove duplicate.
- Refine, select, or add new feature.
- Groom the selected features
- Finalize feature details to be imported in Azure DevOps
Covered in steps 7 to 11.
Import features in Azure DevOps
The objective of this step is to import features in Azure DevOps with their respective metadata.
covered step 12 and 13.
Steps by steps process
To follow below steps, refer End-to-end-requirement-generation-in-AzureDevops.ipynb
- Step 1 Install all Python libraries.
- Step 2 Import Packages required and instantiate objects.
- Step 3 Import the Semantic functions: Azuredevops.
- Step 4 Splitting raw transcripts to files with <3000 char and copy them to Root\Projectdata\temp\
- Step 5 -Identify files which are containing requirement using “isrequirement” sementic function and copy them to Root\Projectdata\Requirement_discussion\ if they do have requirement.
- Step 6 Read all project information and set project folders.
- Step 7 import historical data in memory for using it subsequent steps. If we are using external sources such as SQL, Cognitive search, mongodb then these steps would change according to source.
- Step 8 We pick files from Root\Projectdata\Requirement_discussion\ folder and process those using “IdentifyFeatures” semantic function.Post that we would remove duplicate requirement.
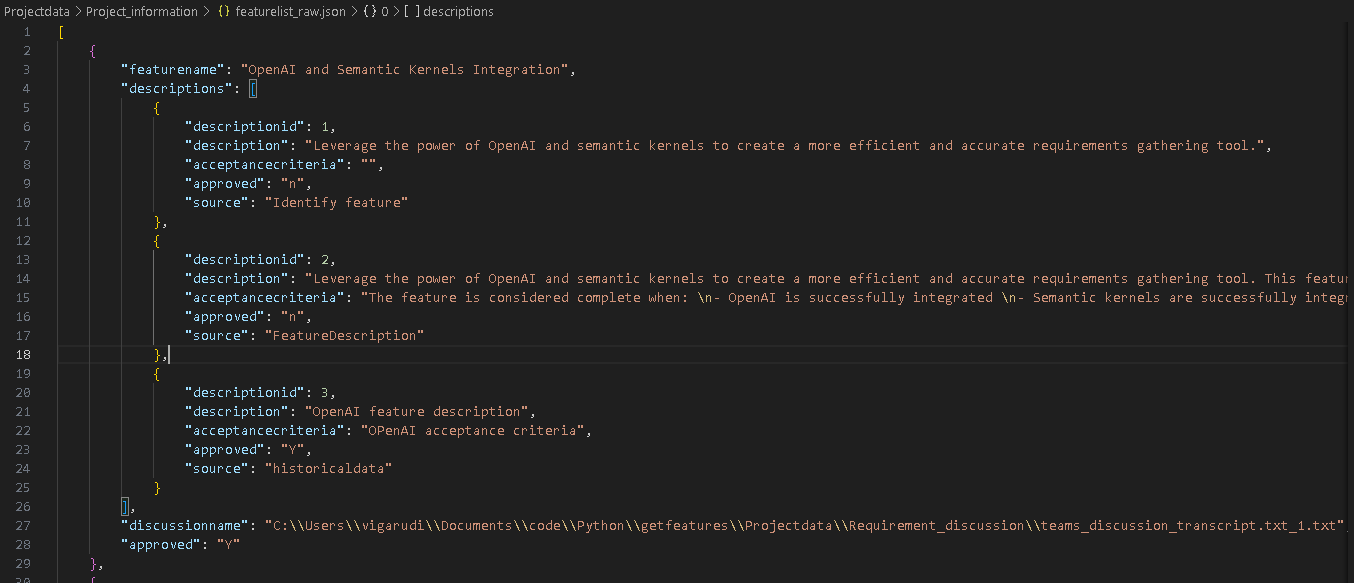
- Step 9 We would perform manual refinment of requirement by updating details in base feature list Json “\Projectdata\Project_information\featurelist_raw.json” In this step we can update feature title, description and select the feature which are required to implement project by changing the value of “approved” tag to “y”. We can manually add features if it’s missed in the list.
- Step 10 Once you have finalized the list of features, we groom these features using “FeatureDescription” semantic function and historical data from memory. The outcome of this step would be the addition of multiple options of description and acceptance criteria.
-
Step 11 This is the final step before we import these features in Azure DevOps. In this step, we would perform manual refinement of requirement by updating details in feature list Json “\Projectdata\Project_information\featurelist_raw.json”. In this step, we can update feature title, description and select the Description and acceptance criteria from “descriptions” array by changing the value of “approved” tag to “y”. We can manually add\update feature description if it’s been missed in list.
-
Step 12 – Once we have finalized list of features, description, acceptance criteria (you can include other parameters such as efforts business value priority etc. as well). We can execute the step below to import them in Azure DevOps.
-
Step 13 – Validate in azure DevOps.

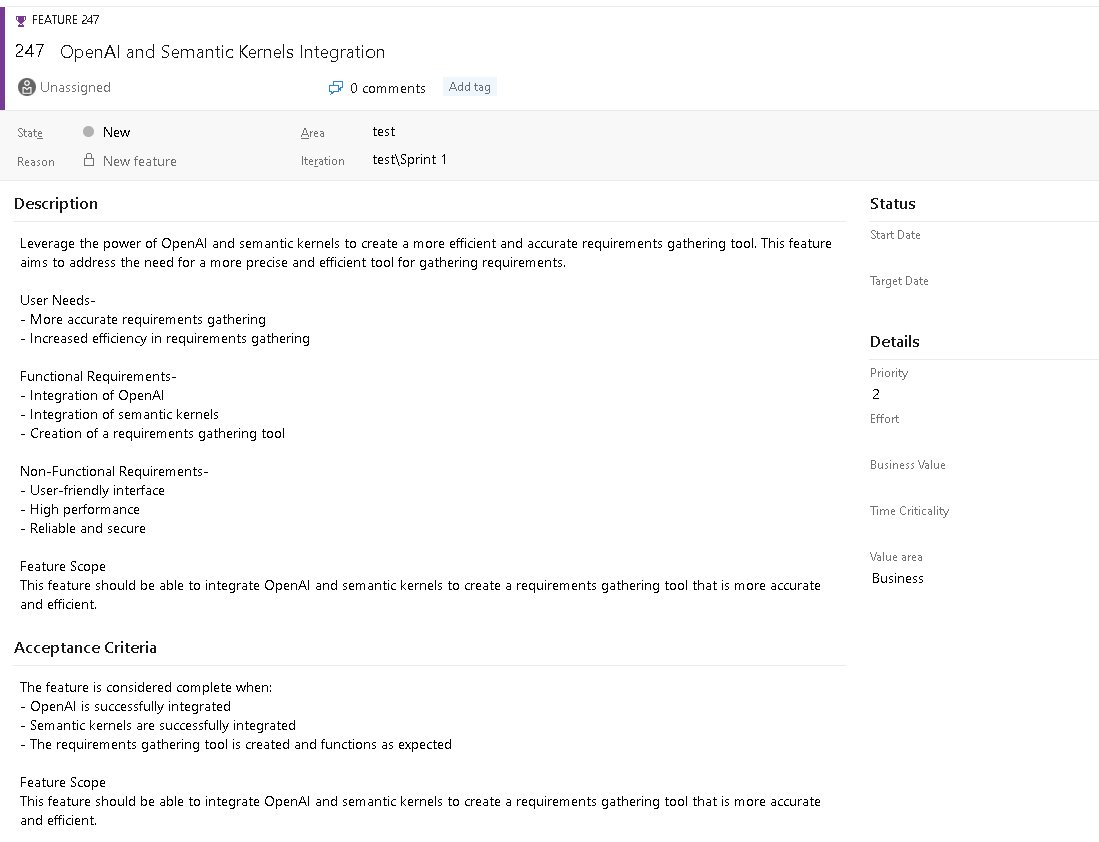
Conclusion
In the ever-accelerating world of software development, the ability to swiftly and accurately translate client requirements into tangible product features is paramount. These requirements often emerge from detailed discussions and conversations, forming the bedrock of any project. Yet, managing and extracting actionable insights from these discussions can be a time-consuming and error-prone endeavor.
However, what if there was a way to streamline and automate this process? What if you could save time and resources while ensuring a higher degree of precision? Welcome to the realm of end-to-end automation, where we seamlessly bridge the gap from requirement discussion transcripts to Azure DevOps features.
Throughout this blog, we’ve embarked on a journey through a well-structured system, armed with historical data, custom skills, and project-related information. We’ve delved into the seamless integration of these components, guided by a comprehensive Jupyter Notebook, and witnessed how automation can revolutionize requirement management.
It’s not just about time-saving; it’s about fundamentally transforming the way we approach requirements and development. With automation at its core, we’ve unraveled a world of efficiency, accuracy, and agility in the software development process.
This journey is a testament to how technology and innovation intersect, where automation becomes your secret weapon for software development excellence. With the power to transition from lengthy discussions to tangible Azure DevOps features, you can revolutionize your development pipeline.
So, join us in embracing the exciting future of software development, where the possibilities are limitless, and the potential is boundless.
0 comments