
We are thrilled to announce a new set of updates for Azure Pipelines, the Continuous Integration and Continuous Delivery platform part of Azure DevOps. Our team has been hard at work for the past few months to deliver new features, including some that were much-requested by our users.
Improved CD capabilities for multi-stage YAML pipelines
Developers using multi-stage YAML pipelines can now manage deployment workflows in separate pipelines and trigger them using resources. As part of this experience we have added support for consuming other pipelines and images from Azure Container Registry (ACR) as resources.
“pipeline” as a resource
If you have an Azure Pipeline that produces artifacts, you can consume the artifacts by defining a pipeline resource, and you can also enable your pipeline to be automatically triggered on the completion of that pipeline resource.
resources:
pipelines:
- pipeline: SmartHotel
source: SmartHotel-CI
trigger:
branches:
- 'releases/*'
- master
You can find more details about pipeline resource here.
Azure Container Registry as “container” resource
You can also use Azure Container Registry (ACR) container images to trigger the execution of a pipeline in Azure Pipelines when a new image is published to ACR:
resources:
containers:
- container: MyACR
type: ACR
AzureSubscription: RMPM
resourcegroup: contosoRG
registry: contosodemo
repository: alphaworkz
trigger:
tags:
include:
- 'production*'
You can find more details about ACR resource here.
Just like with repositories, we support complete traceability for both pipelines and ACR container resource. For example, you can see the changes and the work items that were consumed in a run and the environment they were deployed to.
New deployment strategies
One of the key advantages of continuous delivery of application updates is the ability to quickly push updates into production for specific microservices. This gives you the ability to quickly respond to changes in business requirements.
With this update, we are announcing support for two new deployment strategies: canary for Azure Kubernetes Service (AKS), and rolling for Virtual Machines (in private preview). This is in addition to the rolling deployment strategy support for AKS that we introduced in the spring. Support for blue-green deployments and other resource types is coming in a few months.
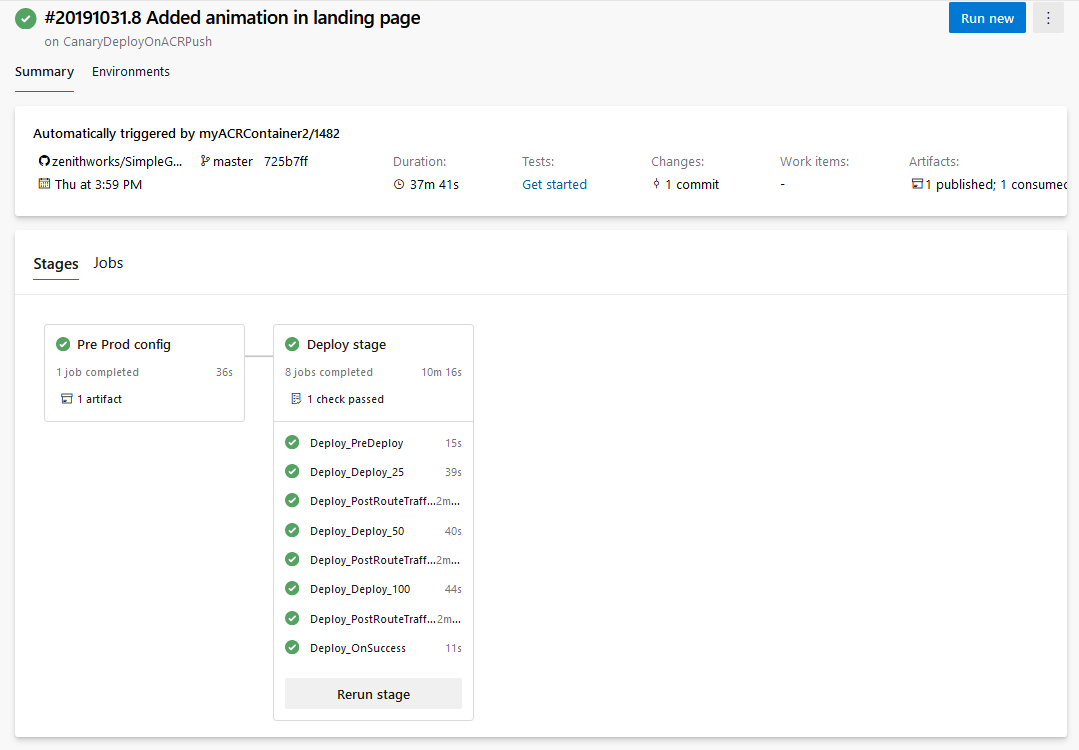
Canary: In this strategy, the newer version (canary) is deployed next to the current version (stable), but only a portion of traffic is routed to canary to minimize risk. Once canary is found to be good based on metrics and other parameters, the exposure to newer version is gradually increased.
Previously, when the canary strategy was specified with the KubernetesManifest task, the task created baseline and canary workloads whose replicas equaled a percentage of the replicas used for stable workloads. This was not exactly the same as splitting traffic up to the desired percentage at the request level. To tackle this, we have now introduced support for Service Mesh Interface-based canary deployments in KubernetesManifest task. Service Mesh Interface (SMI) abstraction allows for plug-and-play configuration with service mesh providers such as Linkerd and Istio, while the KubernetesManifest task takes away the hard work of mapping SMI’s TrafficSplit objects to the stable, baseline and canary services during the lifecycle of the deployment strategy. The desired percentage split of traffic between stable, baseline and canary is more accurate as the percentage traffic split is done at the request level in the service mesh plane.
Consider the following pipeline for performing canary deployments on Kubernetes using the Service Mesh Interface in an incremental manner:
- deployment:
displayName:
pool:
vmImage: $(pool)
environment: ignite.smi
strategy:
canary:
increments: [25, 50]
deploy:
steps:
- checkout: self
- task: KubernetesManifest@0
displayName: Deploy canary
inputs:
action: $(strategy.action)
namespace: smi
strategy: $(strategy.name)
trafficSplitMethod: smi
percentage: $(strategy.increment)
baselineAndCanaryReplicas: 1
manifests: 'manifests/*'
containers: '$(imageRepository):$(Build.BuildId)'
postRouteTraffic:
pool: server
steps:
- task: Delay@1
inputs:
delayForMinutes: '2'
on:
failure:
steps:
- script: echo deployment failed...
- task: KubernetesManifest@0
inputs:
action: reject
namespace: smi
strategy: $(strategy.name)
manifests: 'manifests/*'
success:
steps:
- script: echo 'Successfully deployed'
In this case, request are routed incrementally to the canary deployment (at 25%, 50%, 100%) while providing a way for the user to gauge the health of the application between each of these increments under the postRouteTraffic lifecycle hook.
Both canary and rolling strategies support following lifecycle hooks: preDeploy (executed once), iterations with deploy, routeTraffic and postRouteTraffic lifecycle hooks, and exit with either success and failure hooks.
To learn more, check out the YAML schema for deployment jobs and the deployment strategies design document.
We are looking for early feedback on support for Virtual Machine resource in environments and performing rolling deployment strategy across multiple machines, which is now available in private preview. You can enroll here.
Pipeline Artifacts and Pipeline Caching
Pipeline Artifacts and Pipeline Caching are now generally available.
You can use Pipeline Artifacts to store build outputs and move intermediate files between jobs in your pipeline. You can also download the artifacts from a pipeline from the build page, for as long as the build is retained. Pipeline Artifacts are the new generation of build artifacts: they take advantage of existing services to dramatically reduce the time it takes to store outputs in your pipelines.
Pipeline Caching can help reduce build time by allowing the outputs or downloaded dependencies from one run to be reused in later runs, thereby reducing or avoiding the cost to recreate or re-download the same files again. Caching is especially useful in scenarios where the same dependencies are compiled or downloaded over and over at the start of each run. This is often a time-consuming process involving hundreds or thousands of network calls.
What’s next
We’re constantly at work to improve the Azure Pipelines experience for our users. You can take a sneak peek into the work that’s planned for the next months by looking at our updated roadmap for this quarter.
As always, please let us know if you have any feedback by posting on our Developer Community, or by reaching out on Twitter at @AzureDevOps.
Thank you for your article it’s really helpful information!
@Roopesh, I’m having a hard time finding in your roadmap any features to support manual deployment. Currently, I use the “Manual only” pre-deployment trigger through the classic release UI. The multi-stage pipelines do not yet support this? Is there a plan to add feature parity for this specifically?
“YAML Schema for deployment jobs” and “deployment strategies” links both link to the same document. Also, I second the notice of the missing pipeline resource documentation. Please improve the documentation. What good is releasing a new feature if there is no documentation on how to use the new feature?
Thank you, fixed it
The linked documentation for “pipeline as a resource” doesn’t appear to contain any actual documentation on the feature.
https://github.com/MicrosoftDocs/vsts-docs/issues/6162
Does this feature mean I can create a build pipeline that is triggered when another build pipeline completes successfully?
Yes, you can use pipeline resource to trigger the current pipeline on completion of another pipeline. Will update the doc link