
We recently worked with SMART Business, a Ukrainian consulting services company, along with their partner, a large manufacturer of confectionery products in Central & Eastern Europe, to build a machine learning model which validates whether distributors are stocking chocolates correctly.
This code story provides an overview of different image classification approaches for various levels of complexity that we explored while developing our solution.
Background
The company we worked with has a huge distribution network of supermarket chains across over fourteen countries. Each of these distributors is required to arrange chocolates on their stands according to standardized policies. Each policy describes what shelf a given chocolate should be on and in what order it should be stocked.
There are huge costs associated with “routine” audit activities to enforce these policies. SMART Business wanted to develop a system in which an auditor or store manager could take a picture and be told immediately whether the shelf was stocked correctly, like in the image below.

Investigation
During our scoping, we investigated a couple of approaches to image classification including Microsoft’s Custom Vision Service, Transfer Learning using CNTK ResNet, and Object Detection with CNTK Fast-RCNN. While Object Detection with Fast-RCNN ended up being the best fit, during our investigation we determined that each of these approaches involved different levels of complexity, each with its own strengths and weaknesses.
Custom Vision Service
Training and consuming a REST-based service is dramatically easier than training, deploying and updating a custom computer vision model. As a result, we first investigated Microsoft’s Custom Vision Service. The Custom Vision Service is a tool for building custom image classifiers and improving them over time. We trained a model on a sample data set of 882 images (sorted into 505 valid and 377 invalid images) containing standalone shelves of chocolate.
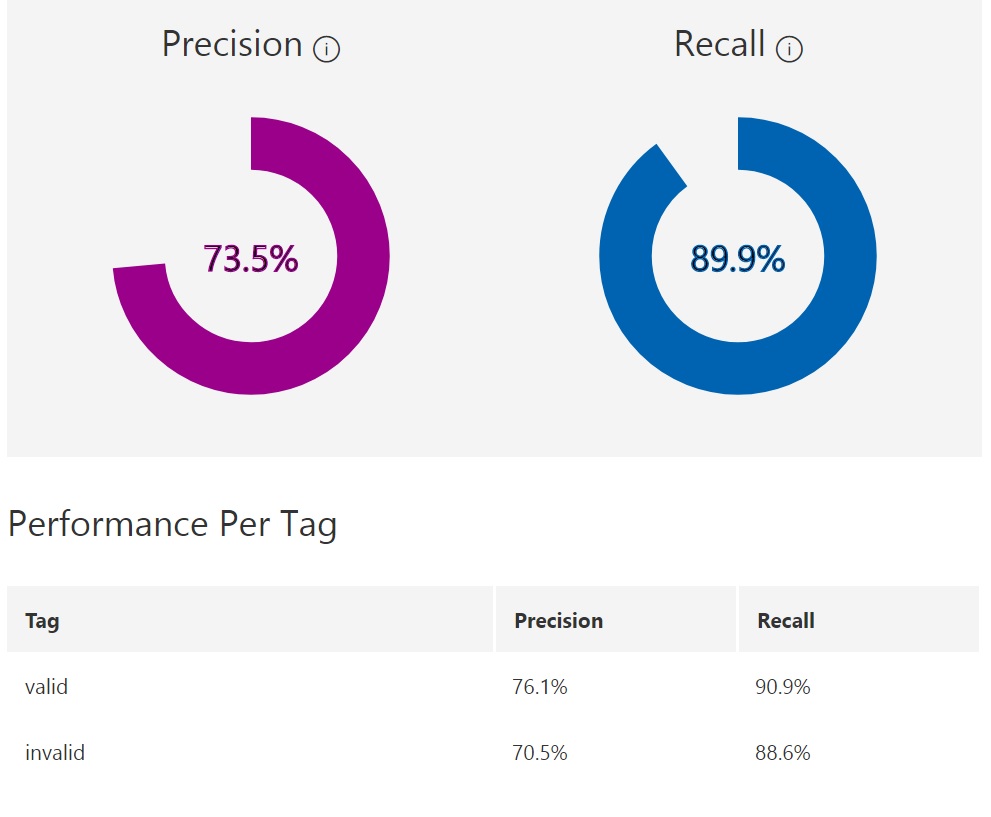
We were able to train a relatively strong baseline model using the Custom Vision Service with the following benchmarks below:
Additionally, we ran the model on an unseen dataset of 500 images to supplement this data and make sure that we had a consistent baseline.
| Label | Precision | Recall | F-1 Score | Support |
| Invalid | 0.71 | 0.74 | 0.72 | 170 |
| Valid | 0.87 | 0.85 | 0.86 | 353 |
| Avg / Total | 0.82 | 0.81 | 0.82 | 523 |
| 125 | 45 |
| 52 | 301 |
These limitations are best expressed in the following quote from the official Custom Vision Service documentation:
The methods Custom Vision Service uses are robust to differences, which allows you to start prototyping with so little data. In theory very few images are required to create a classifier — 30 images per class is enough to start your prototype. However, this means Custom Vision Service is usually not well suited to scenarios where you want to detect very subtle differences.
The Custom Vision Service worked well when we narrowed down the scope of our policy problem to one policy and standalone shelves of chocolate, however, the service’s 1000 image training limit narrowed our ability to fine-tune the model around certain consistent but subtle policy edge cases.
For example, the Custom Vision Service excelled at detecting the flagrant policy violations that represented the majority of our dataset, like the examples below:


However, it consistently failed to recognize more subtle yet persistent violations that were off by one chocolate, such as the first shelf in this picture:

To transcend the limitations of the Custom Vision Service, we toyed with the idea of creating multiple models and then ensembling their results using a voting classifier. While this would have no doubt improved the results of the model, and may be worth investigating for other scenarios, it would have also increased the API cost, as well as run-time. In addition, it would still not be scalable beyond one or two policies, since the Custom Vision Service caps the number of models per account at nineteen.
Transfer Learning using CNTK and ResNet
To work around the dataset limits of the Custom Vision Service, we next investigated building an image recognition model with CNTK and Transfer learning on top of ResNet with the following tutorial. ResNet is a deep convolutional neural network architecture developed by Microsoft for the image-net competition in 2015.
In this evaluation, our training dataset contained two sets of 795 images representing valid and invalid policy.
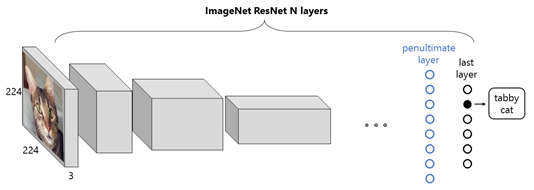
Since we did not have enough data (i.e., tens of thousands of samples) or the processing power to train our own large-scale CNN model from scratch, we decided to leverage ResNet by retraining its output layer on our train dataset.
Results
We ran the transfer learning ResNet model on three runs of 20, 200, and 2000 epochs respectively. We received the best results on our test dataset during our run of 2000 epochs.
| Label | Precision | Recall | F-1 Score | Support |
| Invalid | 0.38 | 0.96 | 0.54 | 171 |
| Valid | 0.93 | 0.23 | 0.37 | 353 |
| Avg / Total | 0.75 | 0.47 | 0.43 | 524 |
Confusion Matrix
| 165 | 6 |
| 272 | 81 |
As we can see, the transfer learning approach severely under performed compared to the Custom Vision Service.
Transfer learning on ResNet can be a powerful tool for training strong object recognition with limited datasets. However, when we apply the model to new images that stray too far from the domain of the original 1000 ImageNet classes, the model struggles to capture new representative features due to its reused abstract features “learned” from the ImageNet training set.
Investigation Conclusions
We saw promising results classifying individual policies using object recognition approaches, such as the Custom Vision Service considering the large quantity of brands and potential ways to order them on a shelf, it was prohibitive to determine policy adherence from an image using standard object recognition with the amount of available data.
The complexity of the validation corner cases combined with SMART Business’ concern about the ease of building new models for each policy using standard object recognition methods encouraged us to examine a more creative solution for their problem domain.
The Solution
Object Detection and Fast R–CNN
To strengthen the policy signal while maintaining classification accuracy, we decided to use Object Detection and Fast R-CNN with AlexNet to detect valid shelves in images. If we detected all valid shelves in a picture, then we could consider that stand as valid. In this way, we were not only able to classify our images but also to reuse pre-classified shelves to generate new configurable policies. We decided to use Fast R-CNN over alternatives such as Faster R-CNN since the implementation and evaluation pipeline was already proven to work well on top of CNTK see Object Detection Using CNTK.
First, we used the new image support feature of the Visual Object Tagging Tool (VoTT) to tag a valid policy on a slightly larger 2600 image dataset. For an explanation of how to tag image directories with VOTT, see Tagging an Image Directory.

By tweaking the filtration aspect ratios, quantity and minimum sizes of our region of interest, we were able to get quality results from our dataset.
Results

While the results of this model at first glance seem to be marginally worse than the results of the Custom Vision Service solution, the gains in modularity and the ability to generalize across certain persistent edge cases encouraged SMART Business to continue with the more advanced object detection approach.
Opportunities for Reuse
Below is an outline of the advantages and disadvantages of the contextual methodologies for image classification that we investigated, in order of complexity.
| Methodology | Advantages | Disadvantages | When to use |
| Custom Vision Service |
|
|
|
| CNN / Transfer Learning |
|
|
|
| Object Detection using VoTT |
|
|
|
The Deep Learning ecosystem is rapidly advancing with new algorithms being quickly iterated upon and released daily. After reading about state of the art performance on traditional benchmarks, it can be tempting to throw the newest available DNN algorithm at a classification problem. However, it is equally (if not more) important to evaluate these new technologies within the context of their application. Too often in machine learning, the use of “new algorithms” overshadows the importance of well thought out methodology.
The methodologies investigated during our collaboration revealed a spectrum of classification methodologies of varying complexity and with trade-offs that are useful to consider when building image classification systems.
Our investigations show that it is important to weigh the trade-offs of factors such as implementation complexity, scalability, and optimization potential against others like dataset size, class instance variation, class similarity, and performance.