
Claiming expenses is usually a manual process. This project aims to improve the efficiency of receipt processing by looking into ways to automate this process.
This code story describes how we created a skeletal framework to achieve the following:
- Classify the type of expense
- Extract the amount spent
- Extract the retailer (our example is limited to the most common retailers)
We found a few challenges in addressing these goals. For instance, the quality of an Optical Character Recognizer (OCR) is crucial to tasks like accurately extracting the information of interest and modeling text-based classifiers (e.g., the expense category classifier). In addition, we discovered some retailers use logos instead of text for their names, which makes the extraction process more complex.
The figure below shows the stages of addressing the goals of the framework, as well as the aforementioned challenges.
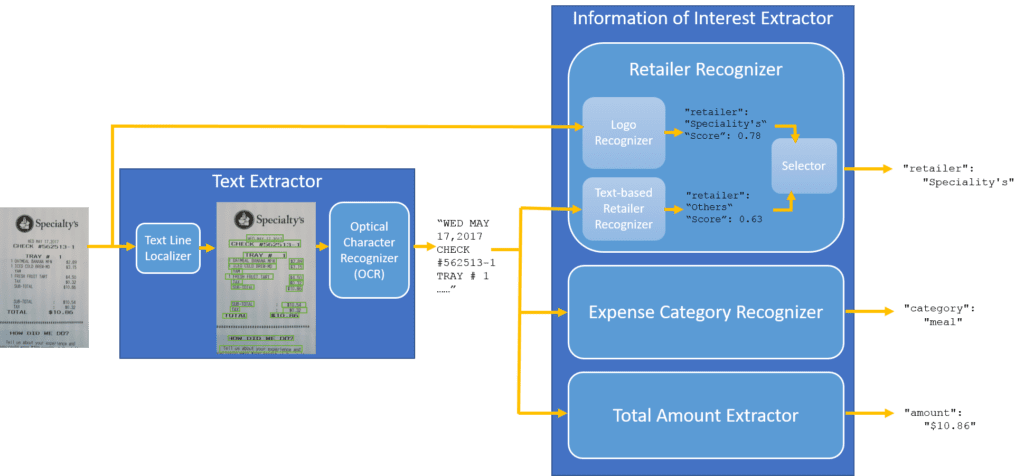
First, a receipt is captured via a camera. Next, that image is passed to the Logo Recognizer, and the Text Line Localizer, where the outputs (smaller chunks of texts) are then passed on to the Optical Character Recognizer (OCR) in the Text Extractor.
The output of an OCR is a string of characters, which is then simultaneously passed to the Text-based Retailer Recognizer, Expense Category Recognizer, and Total Amount Extractor. The Retailer Recognizer consists of two components: the Logo Recognizer and the Text-based Retailer Recognizer.
One of the predicted results from both the Logo Recognizer and the Text-based Retailer Recognizer is then selected.
The functions, methodologies, and code used for each module are as follows:
Text Extractor
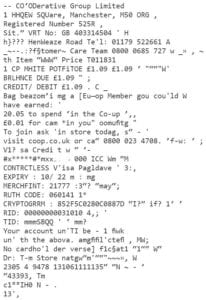
The purpose of an OCR is to extract text out of an image. Here, we have experimented with Microsoft Computer Vision OCR, and open-source Tesseract OCR (online demo). Both support multiple languages. There are other OCRs out there which are mostly licensed. The table below shows example output from both OCRs.
| Receipt | Microsoft-OCR | Tesseract-OCR |
|---|---|---|
 |
 |
 |
Text Line Localizer
Text Connectionist Proposal Network (TCPN) and its authors’ Caffee implementation, is used to break the whole image into smaller sub-images based on the existence of text.In other words, it locates lines of text in a natural image. It is a deep learning approach based on both recurrent neural networks and convolutional networks. Ideally, when an image is broken up into smaller regions before passing them into an OCR, it will help to boost the OCR’s performance. In a small set of samples, we found performance gains when feeding a whole image versus a sub-image into an OCR. The figure below shows the comparison with and without Text Line Localizer, in combination with Tesseract-OCR.
| Receipt | Tesseract-OCR | TCPN + Tesseract-OCR Text Localization | TCPN + Tesseract-OCR Extracted Text |
|---|---|---|---|
 |
tlttl vuxen 200.000r ARLANDA m 9a-rtomrttrSlOg- _ 20N1 'CT, I Zen 1 " Arhnda 0 Kontant |
 |
 |
The authors claimed that the algorithm works reliably on multi-scale and multi- language texts without further post-processing and computationally efficient. We have made available the code for deploying this Caffe model in the Windows environment, specifically in an Azure Data Science Virtual Machine.
If you are interested in using both Text Line Localizer and OCR (in this example, Tesseract-OCR) in a sequential manner, wrapped in a web API, please refer to Node.js web server with ML model (TODO @Eero).
Information of Interest Extractor
This consists of a Retailer Recognizer, Expense Type Recognizer and Total Amount Extractor.
Retailer Recognizer (Logo Recognizer)
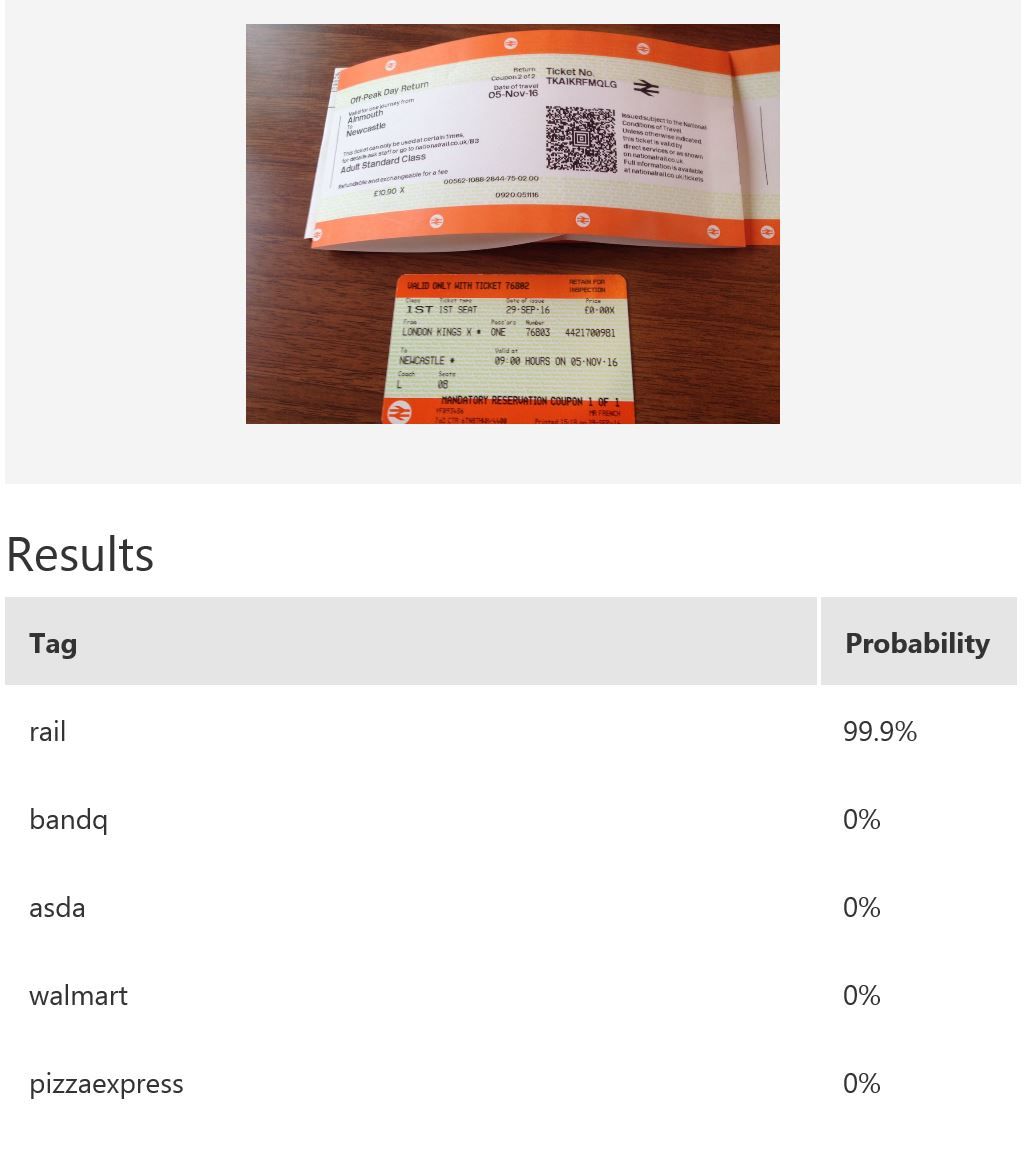
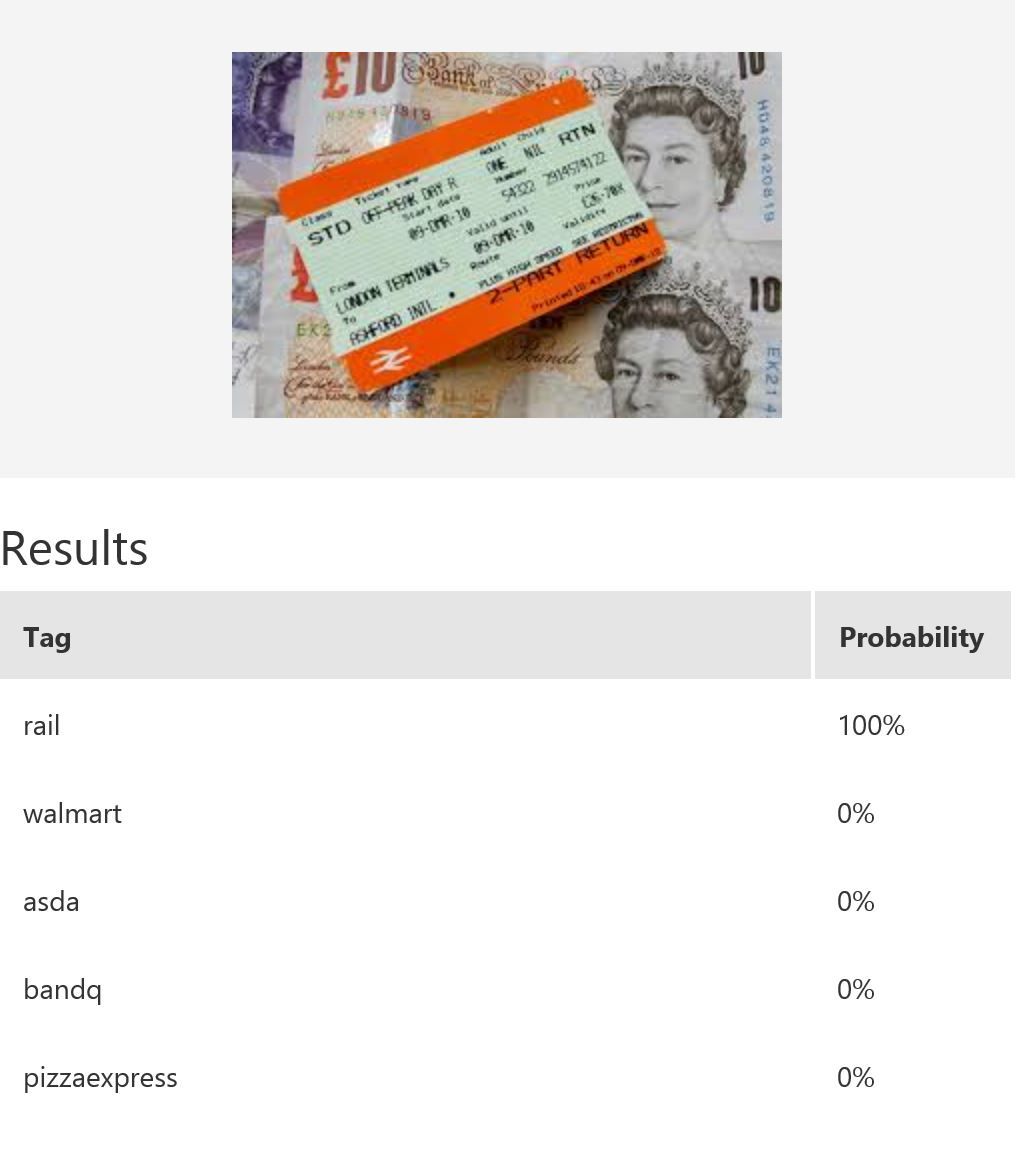
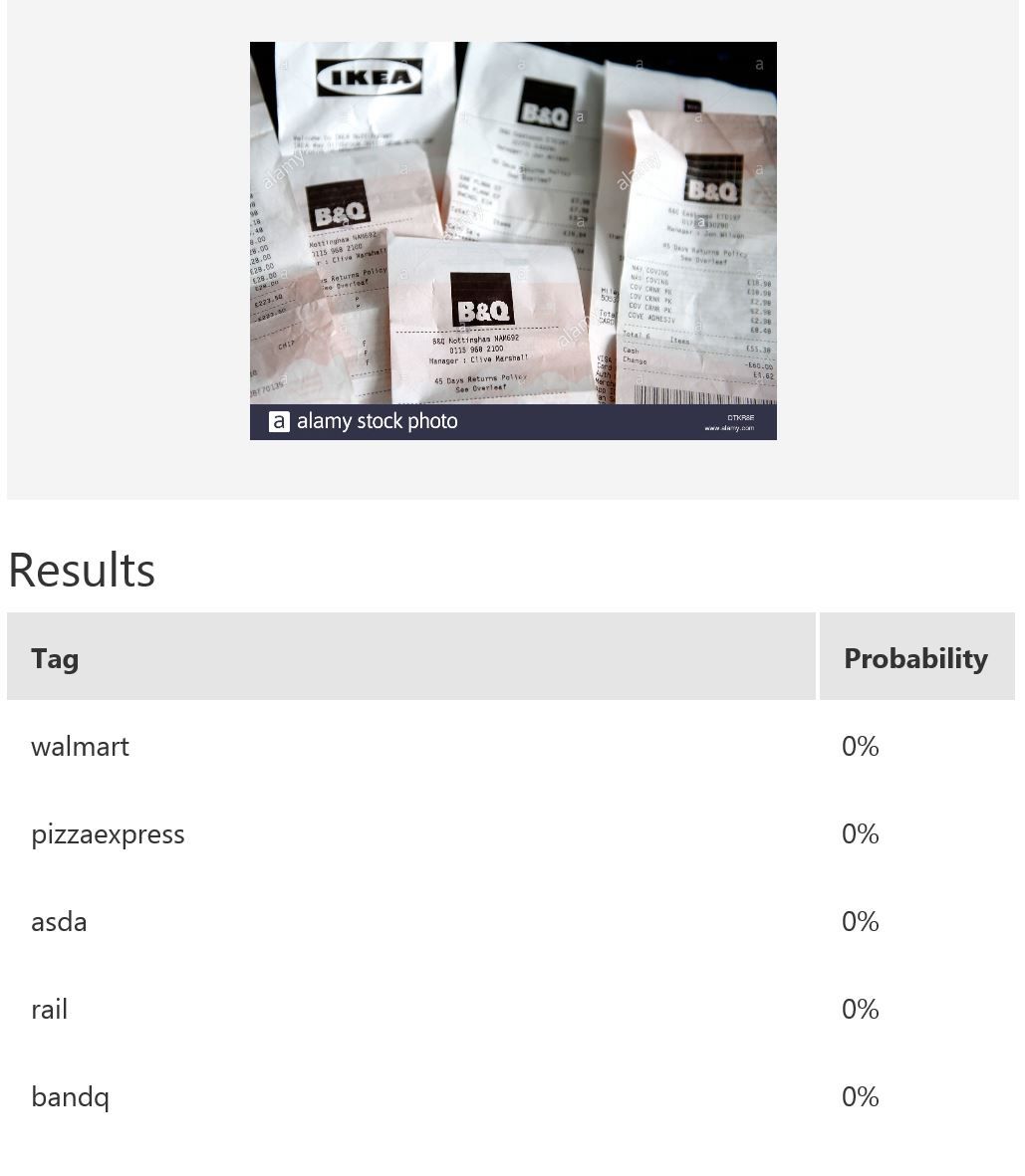
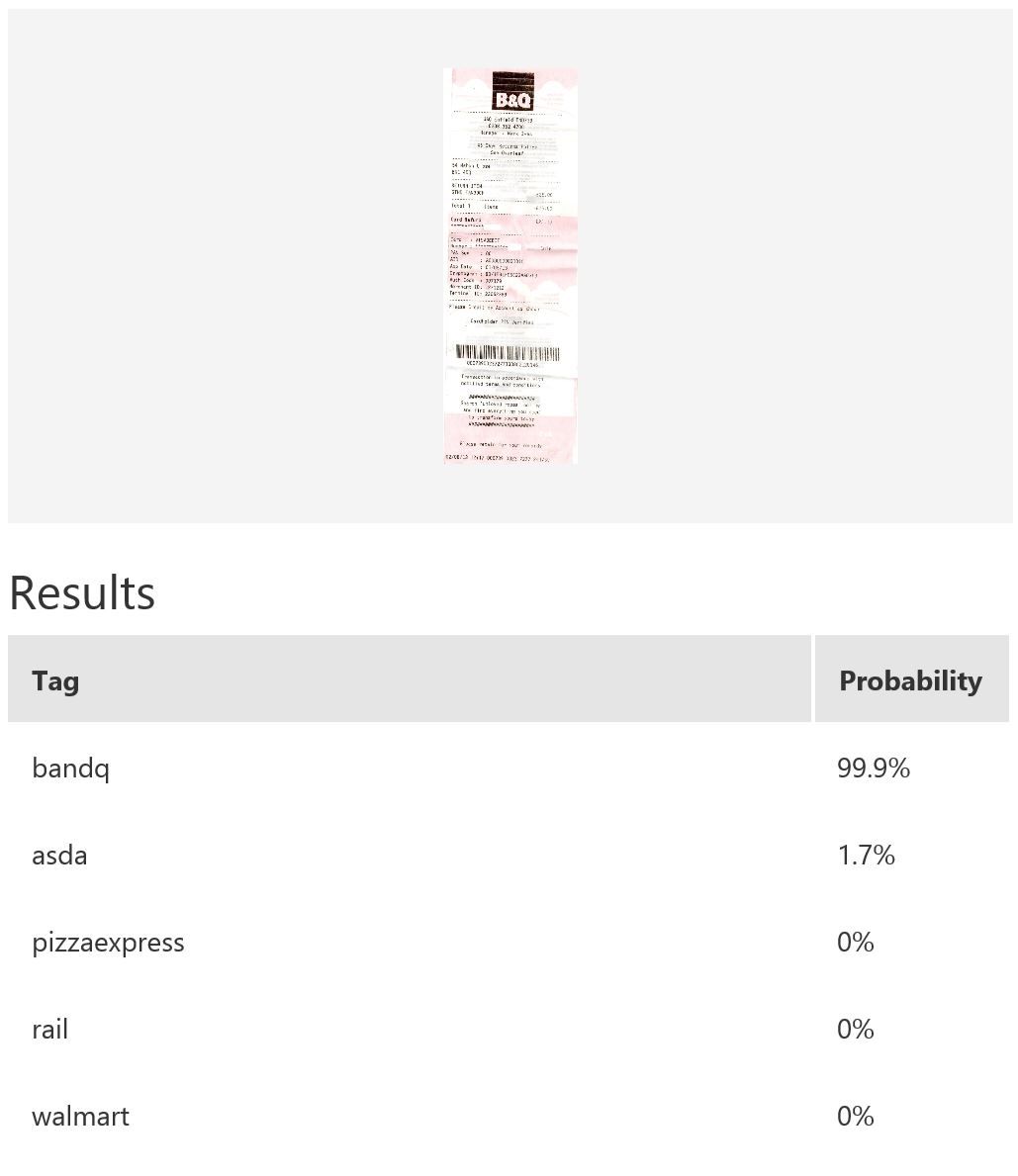
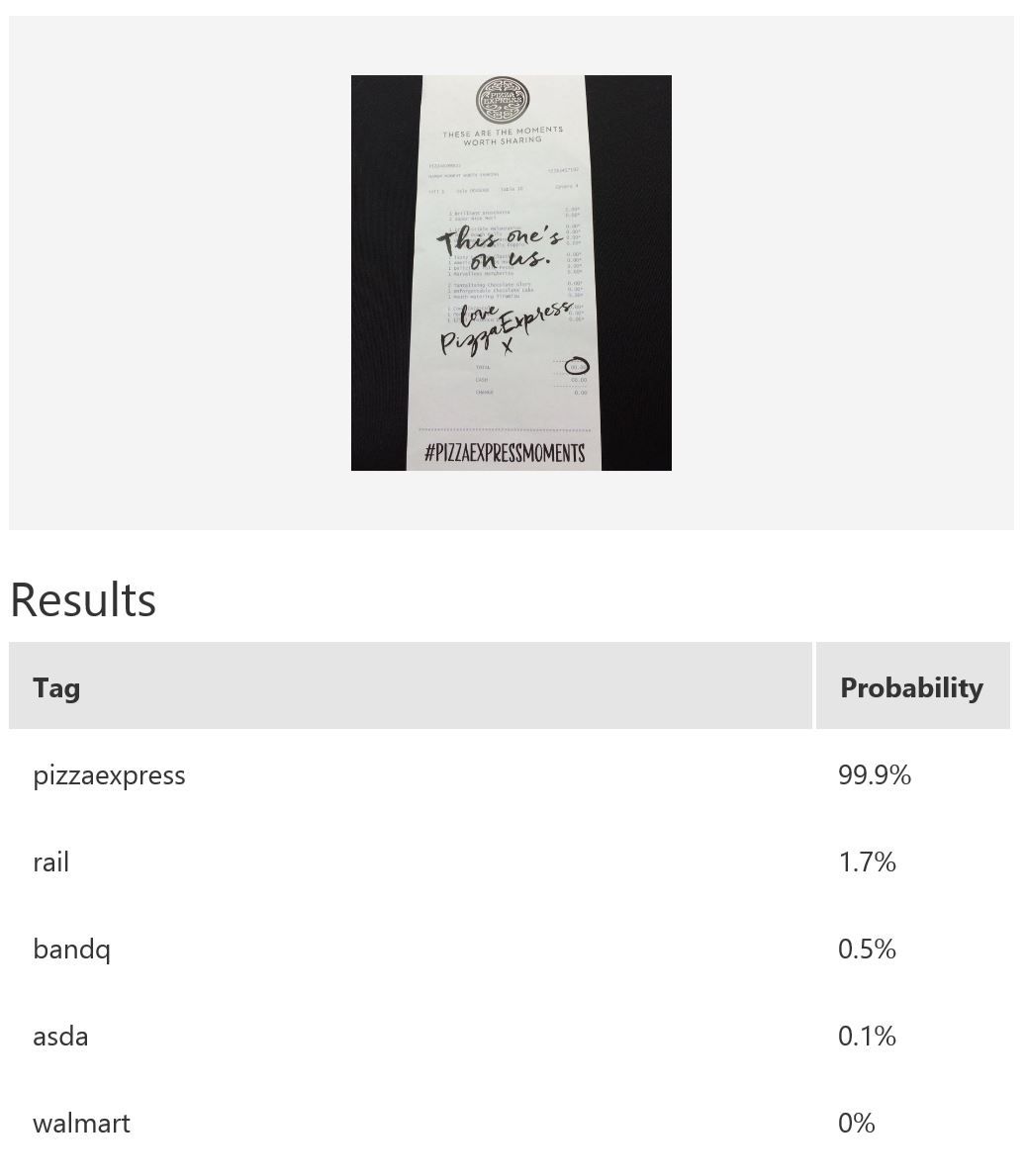
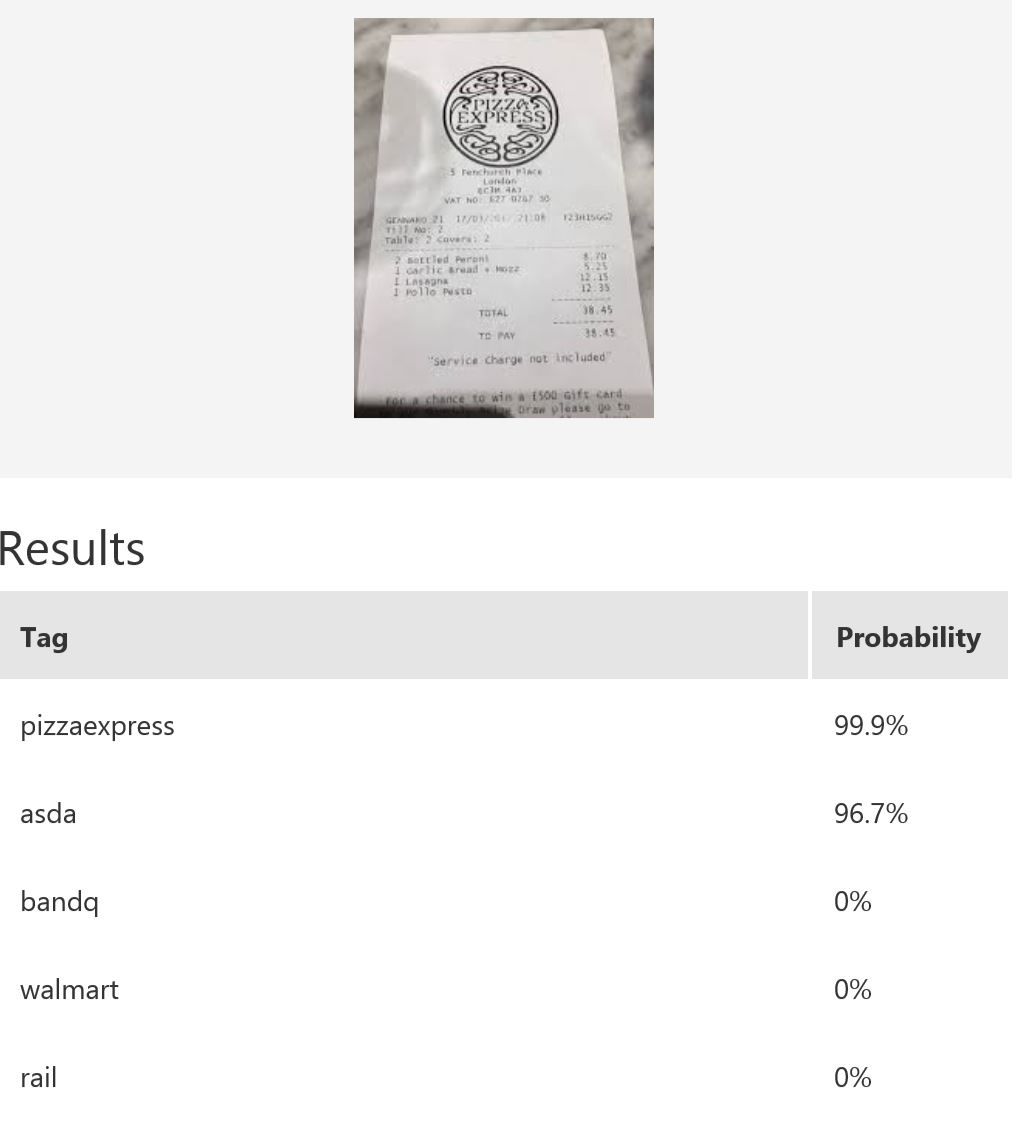
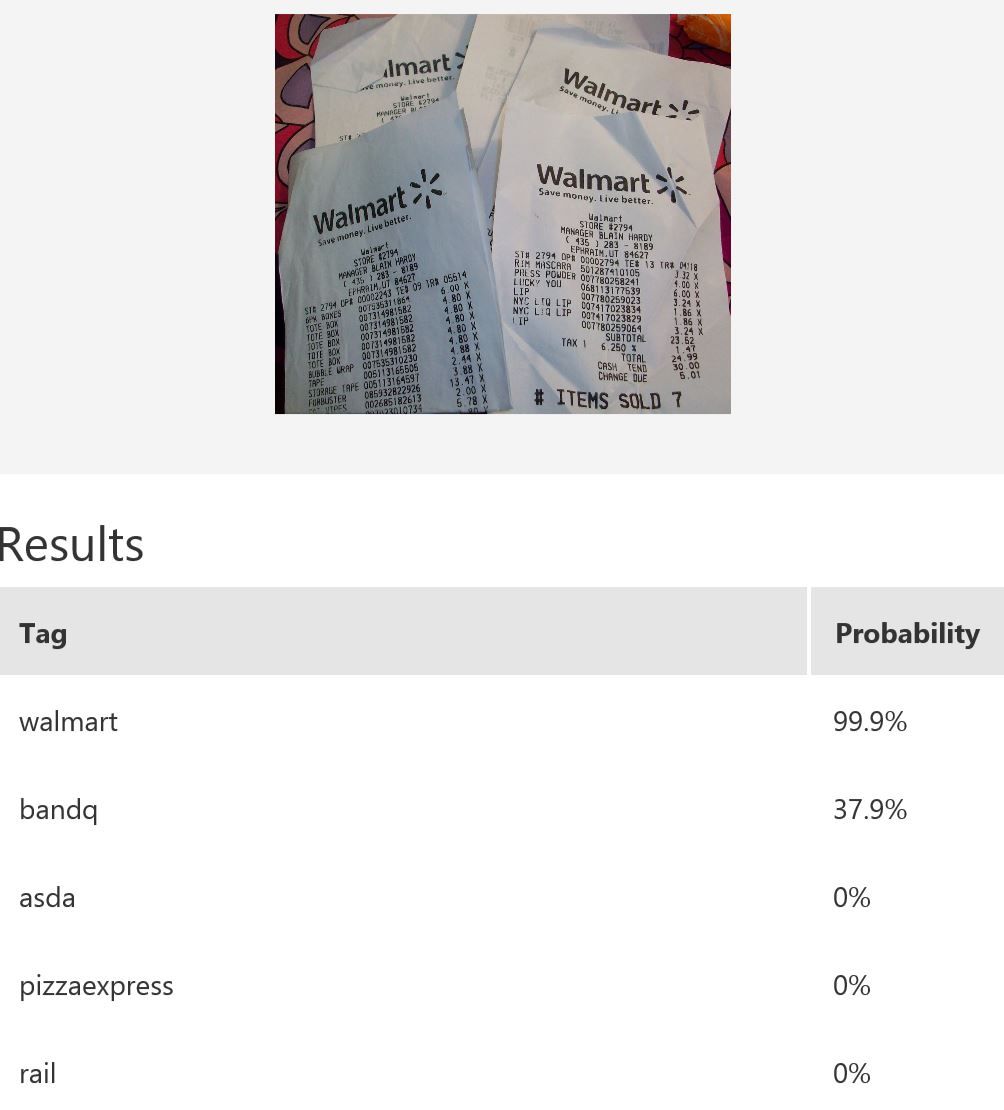
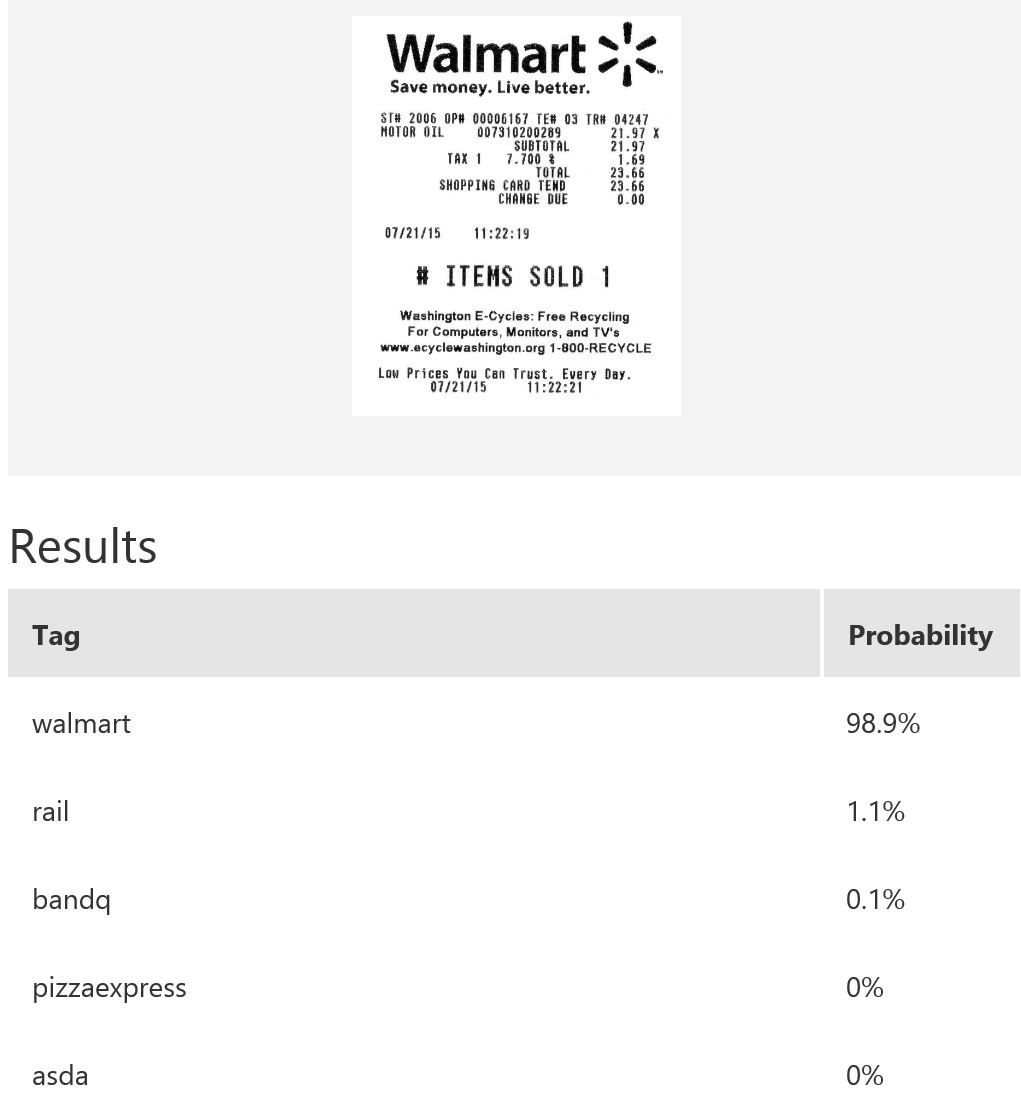
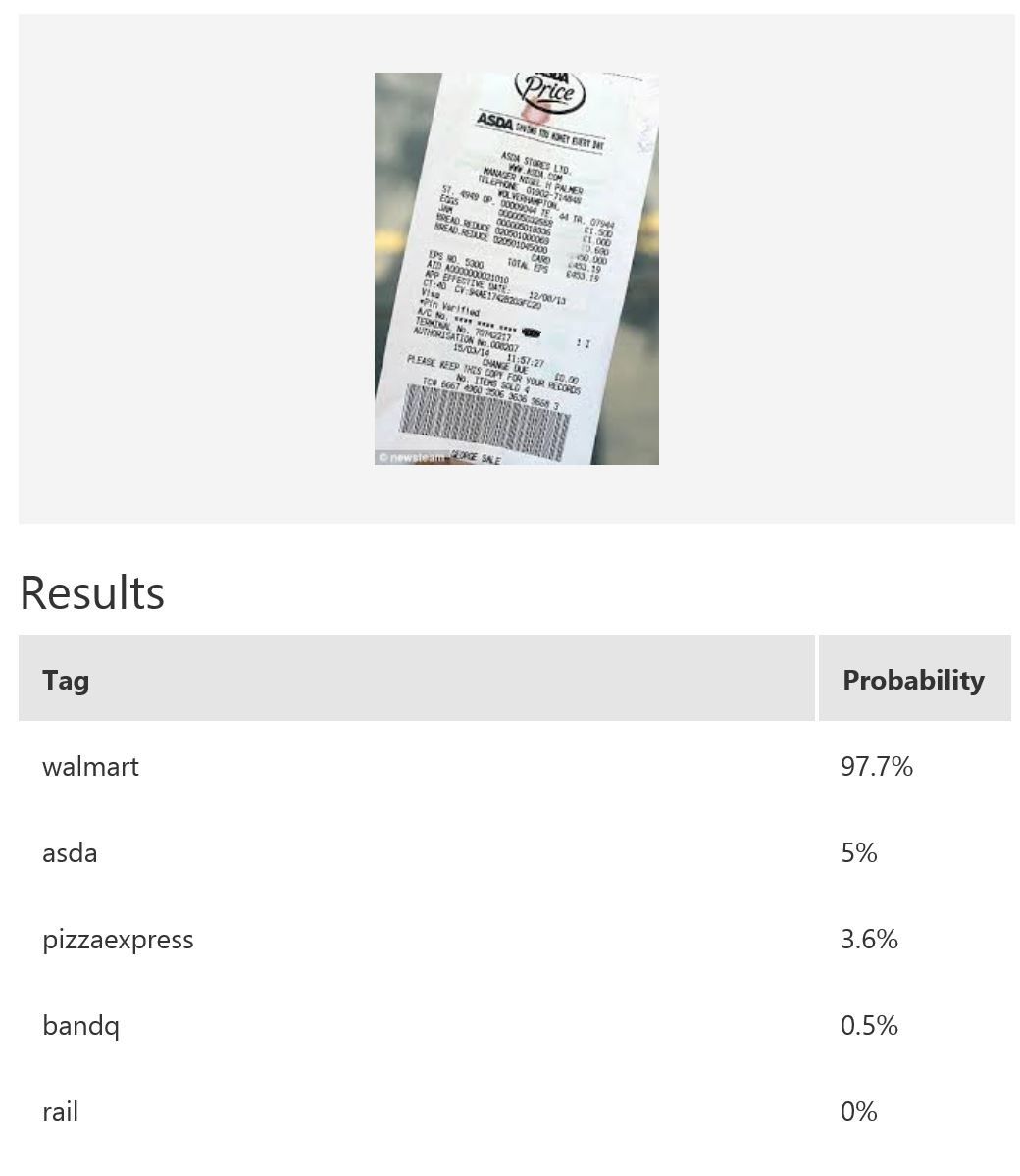
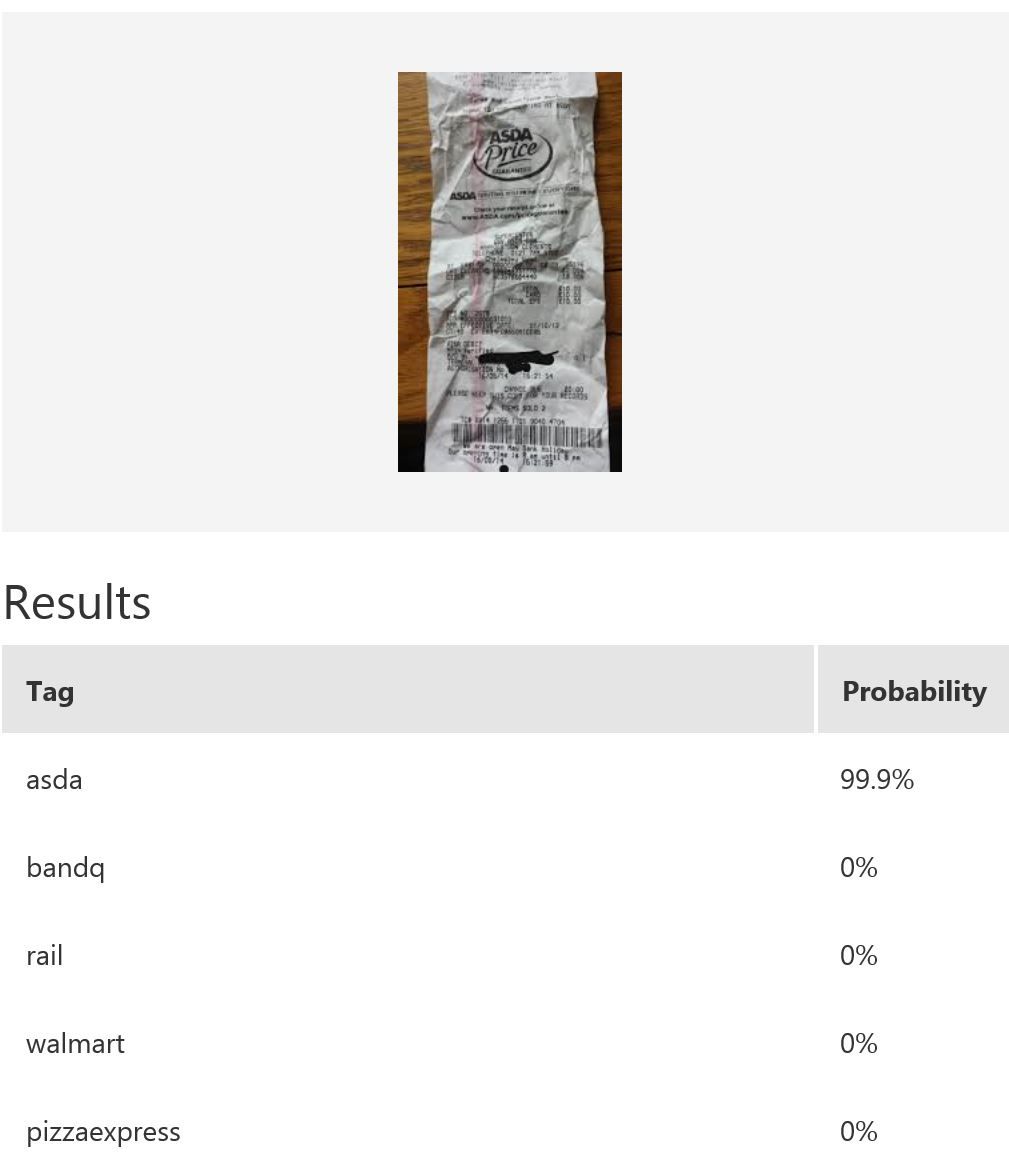
In this example, we use Microsoft Cognitive Services’ Custom Vision Service to build a custom model for recognising retailers based on the look of a receipt and/or a logo. Custom Vision allows you to easily customize your own computer vision models to fit your unique use case. It requires a few dozen samples of labeled images for each class. We trained a model using the entire receipt images in our example. It is possible to only provide a specific region during training; for instance, if most of the time the logo will be at the top of the receipt, then we can use only that part for model-building. When it comes to prediction, either just the top region or the whole receipt can be fed into the predictor. The figure below shows the overall performance and some experimentation results with various classes and the respective number of samples uploaded to Custom Vision — namely, rail (33), bandq (14), pizzaexpress (18), walmart (34) and asda (26).

| Example results | |||
|---|---|---|---|
| 1. | 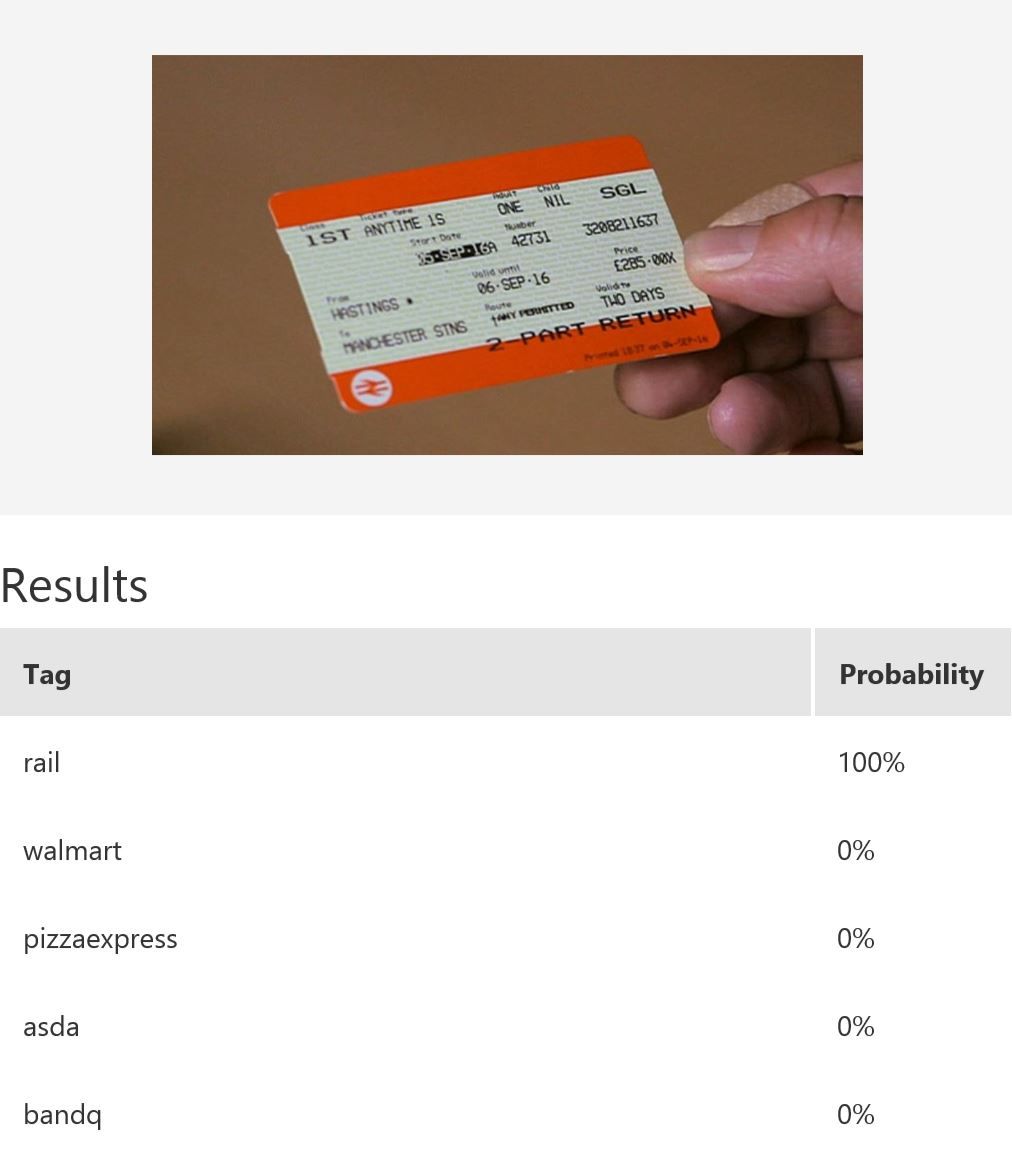 |
 |
 |
| 2. | 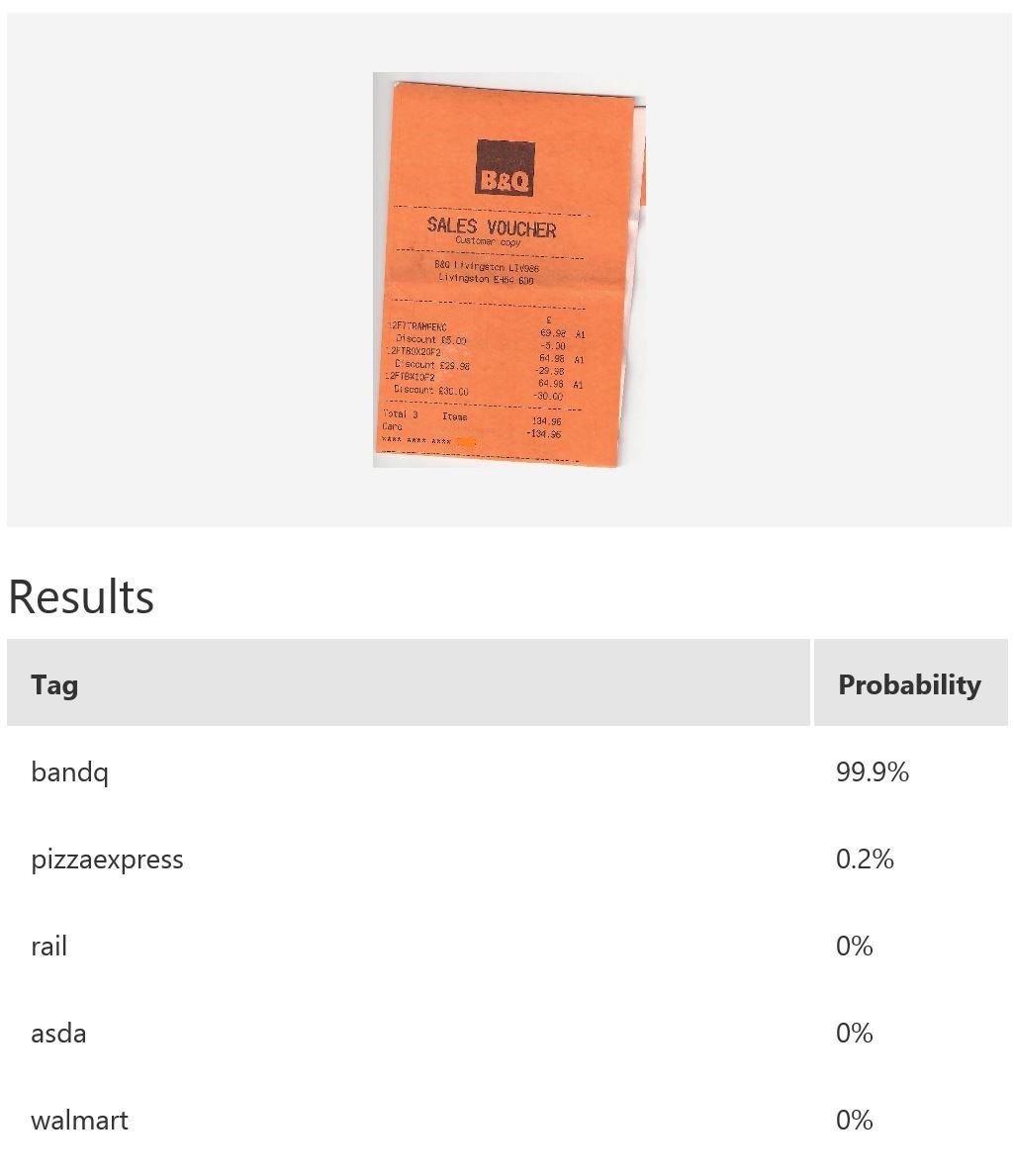 |
 |
 |
| 3. | 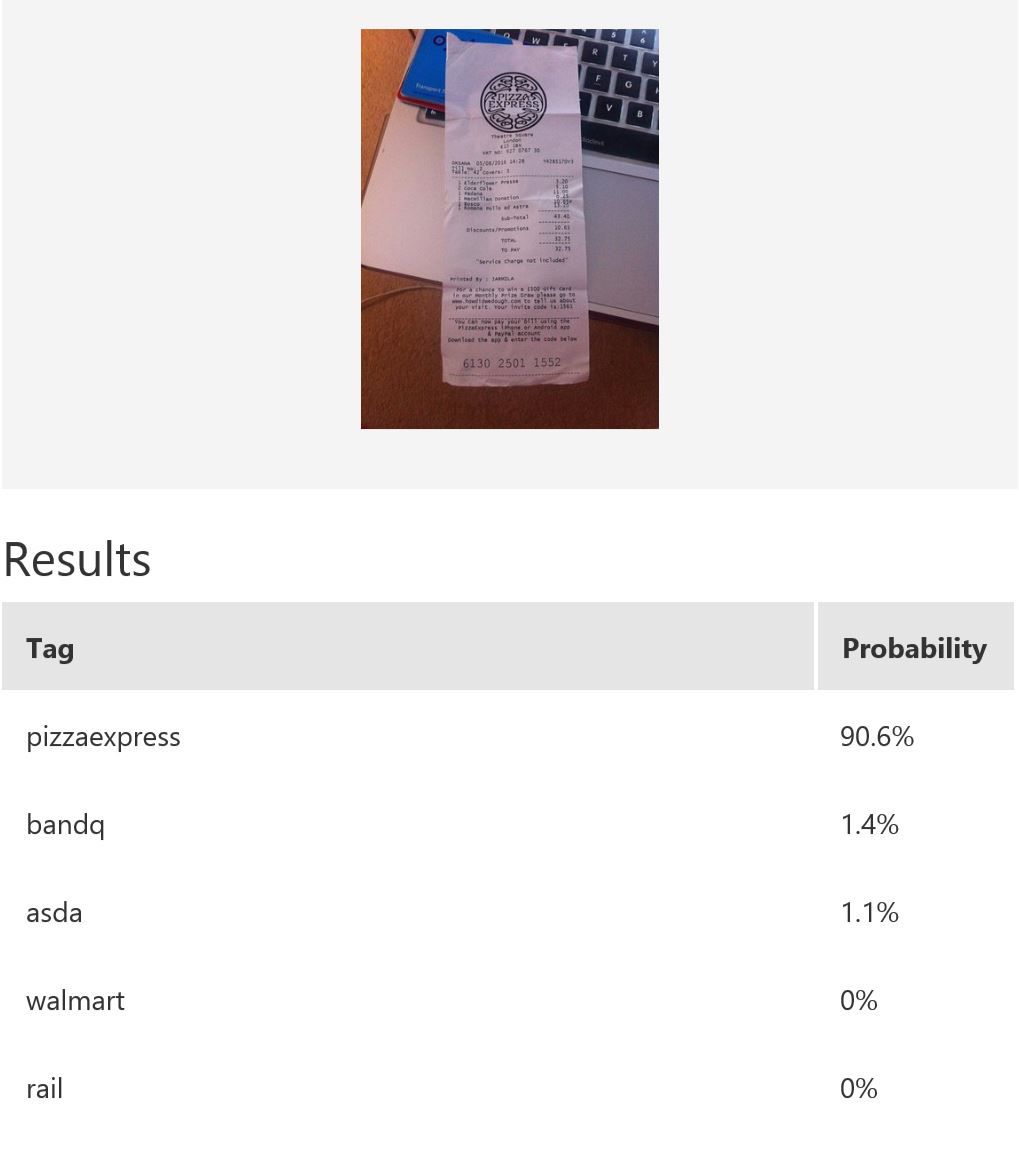 |
 |
 |
| 4. |  |
 |
 |
| 5. | 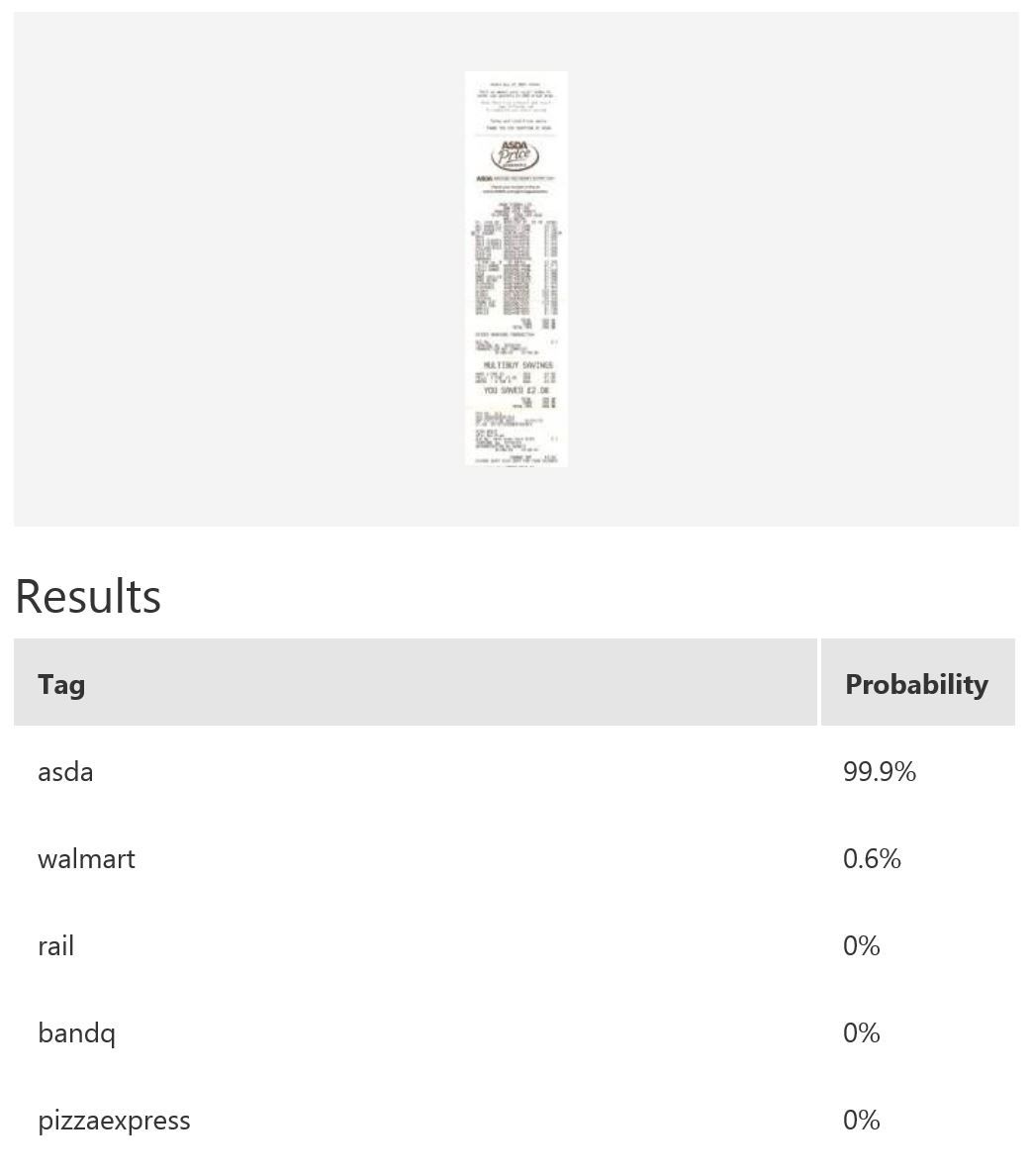 |
 |
 |
| 6. | 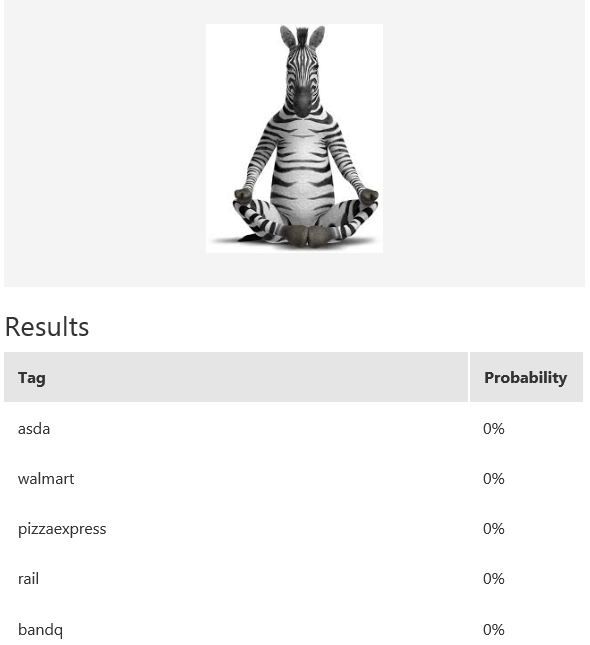 |
 |
 |
| 7. | 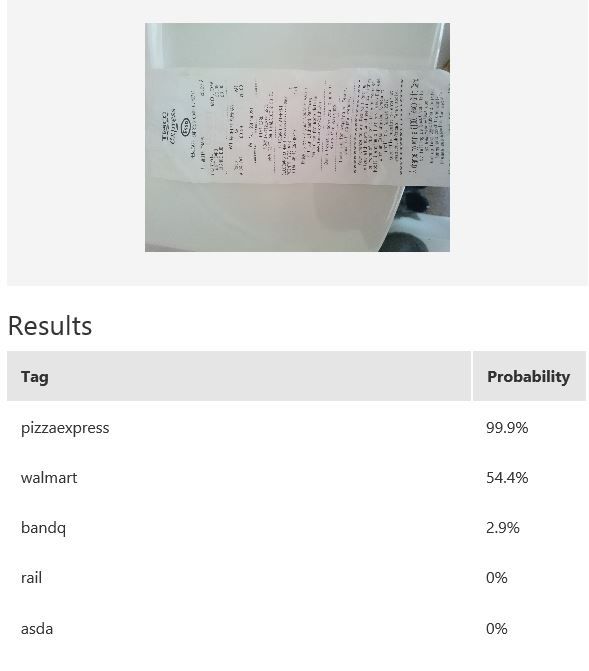 |
 |
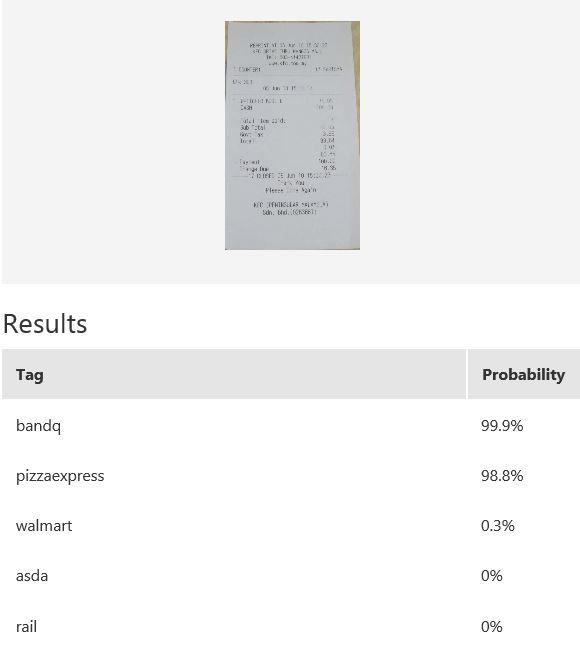 |
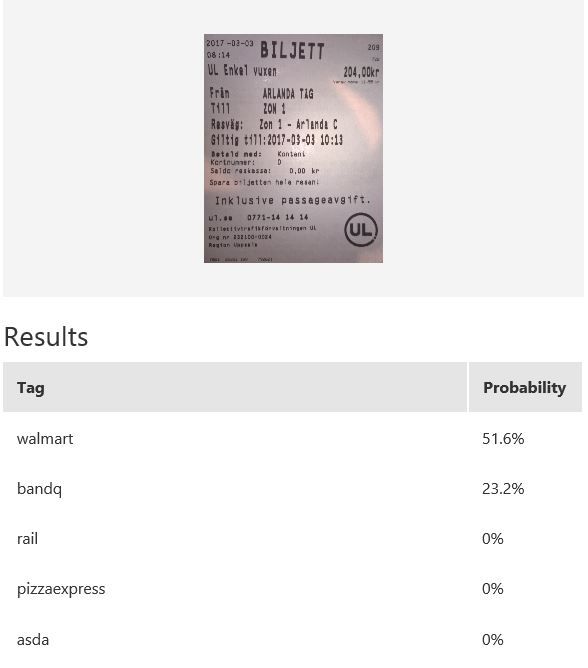
The table above shows some example exemplar results. This model classifies well most of the time for receipts from known retailers. It is able to distinguish a receipt from a non-receipt (see row 6) such as a zebra. Note the confident probability scores shown. In row 2 and 4, there is a test image with multiple bandq receipts and a test image with multiple walmart test receipts. In this example, multiple Walmart receipts appear in the same image and are correctly classified as walmart, whilst a group of B&Q receipts in the same image are not correctly classified. This sample is just to show how the model will behave in corner cases like this. In practice, restrictions can be put in place to help, such as limiting it to one single receipt at a time. Row 7 shows receipts from retailers of which the model has no knowledge. Unfortunately, the classifier is confused when a receipt which does not belong to any of the known classes is tested.
To address the issue above, try adding a class called others, which will be a collection of receipts that have no logos, as well as any receipts that are not from the intended 5 classes. How to decide between these two options will depend on application-specific requirements.
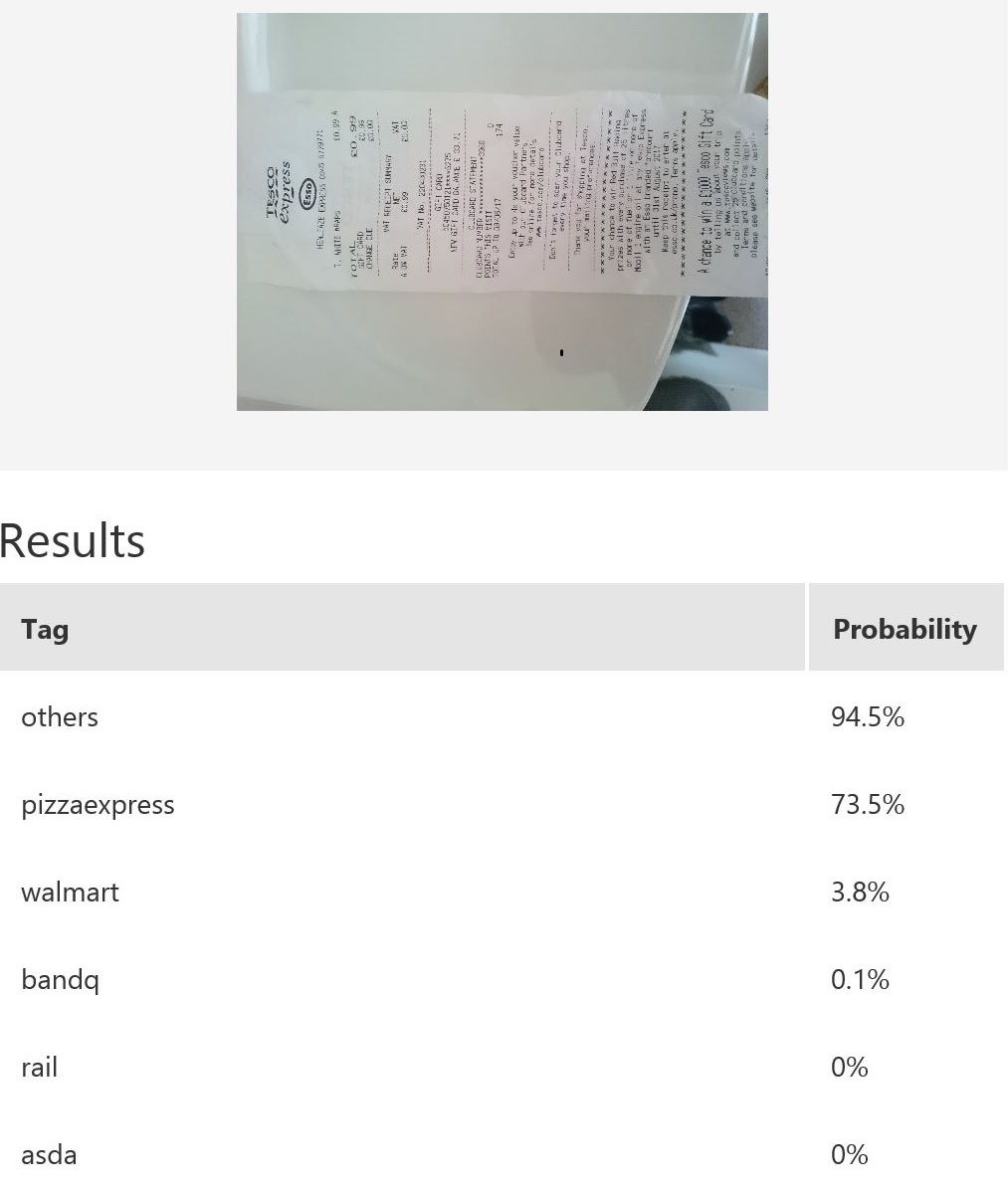
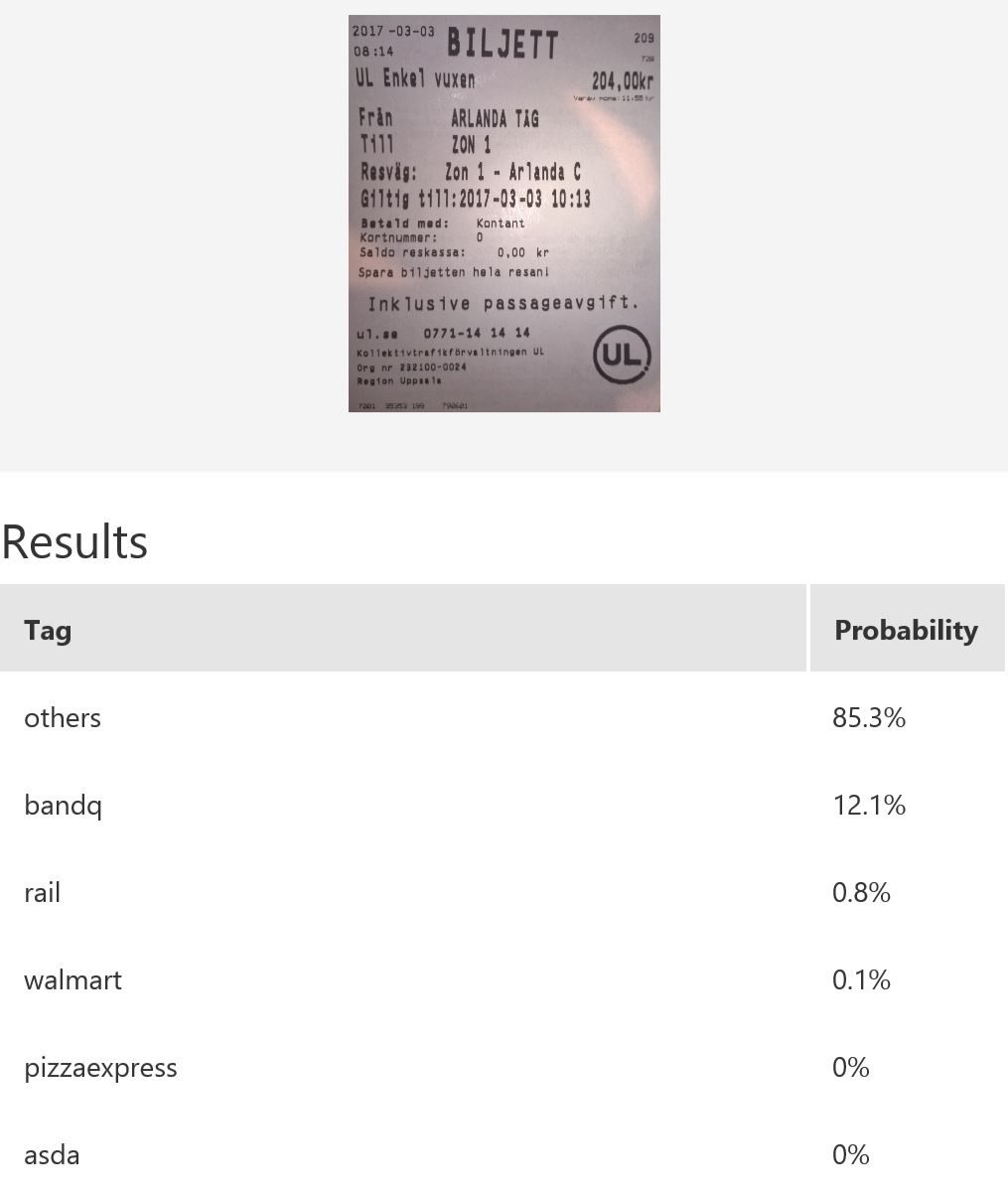
The figures below shows the performance of a different model which has the class others incorporated.
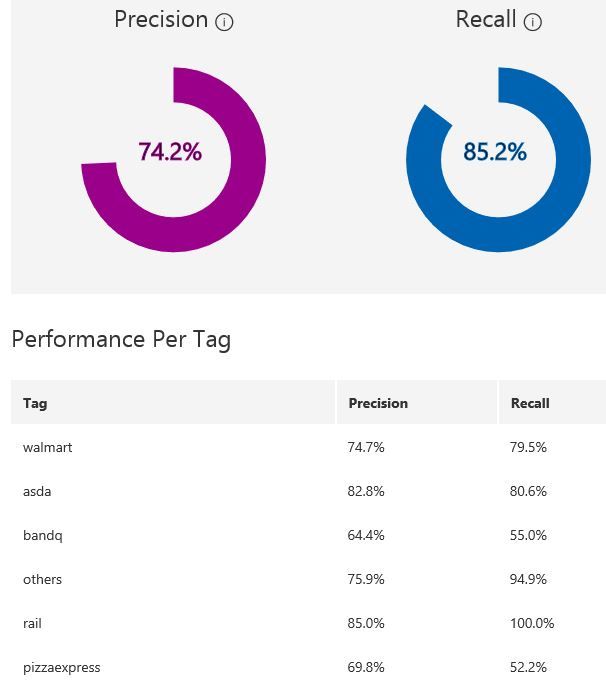
In this example, 76 samples were uploaded to Custom Vision for the model building.
| Example results | ||
|---|---|---|
 |
 |
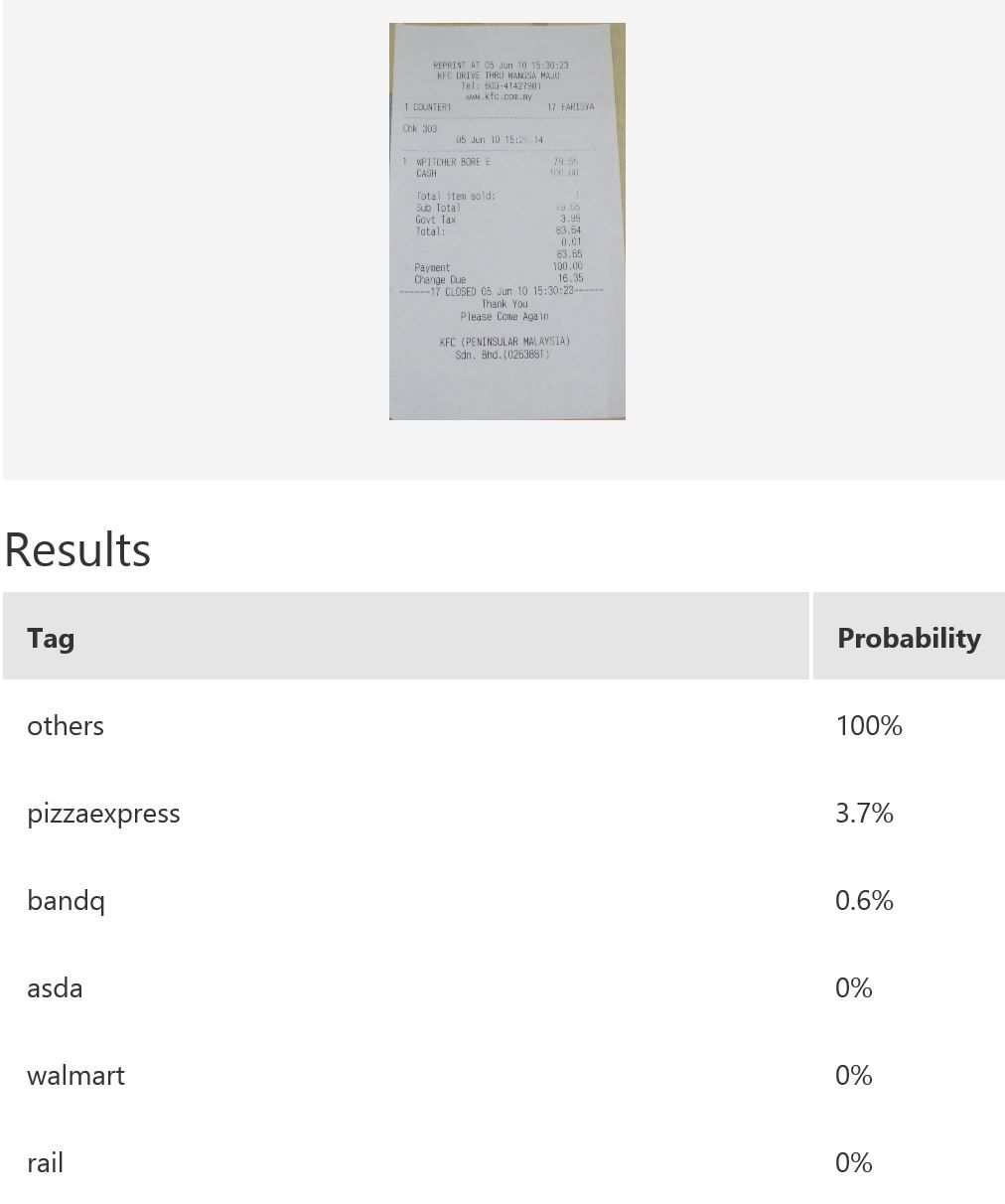 |
Note that the model’s confidence in ruling out those receipts without logos as one of the 5 classes of receipts with logos. The first and third receipts are confidently classified as others. However, consider the test image in the middle: while it is predicted as others with the highest probability, the score for pizzaexpress is rather high too. This confusion could perhaps be mitigated with increased variety of training samples for the class others.
Text-based Retailer Recognizer
In contrast to the Logo Recognizer, this module recognises the retailer by the text extracted from the receipt. As per the Logo Recognizer, instead of using the whole receipt, it is possible just to use certain portion of text extracted to train a text-based retailer recognizer. This is essentially a text classification problem, similar to the Expense Recognizer.
Selector
In this example, we naively select a result from either the Logo Recognizer or the Text-Based Retailer Recognizer (whichever has the highest probability). There are better ways to select a more confident result, such as weighted or non-weighted, fuzzy method, linear or non-linear combination, intuition-based and so on. While this topic is beyond the scope of this post, it will become increasingly important when more classifiers are applied in an ensemble manner. This lightweight, high-level article touches on some basic methods.
Expense Recognizer
Its purpose is to recognize the type of expense, like accommodation, meal, transport etc. This is based on text occurring within the receipt. It is trained within Azure ML Studio using the typical process of text classification. In this example, the Expense Recognizer is based on Using Microsoft Cognitive Services within Azure ML Studio to Predict Expense Type from Receipts. While this is a simplistic approach, many variations of text processing can be applied. Again, the discussion of what are the best approaches or algorithms is beyond the scope of this post. This approach is similar to that of the Text-based Retailer Recognizer.
Total Amount Extractor
At the time of writing, this extractor is naively extracting numbers that show the format of monetary value, and assume the largest value is the total amount spent. Most of the time it works well with credit card purchases but will encounter issues if it is a cash purchase.
These modules are tied together via Azure Functions, Azure Storage and Azure Queue. The figure below shows the architectural diagram. The article Using Azure Functions to enable processing of Receipt Images with OCR highlights the end-to-end implementation and the benefits of using such architecture.
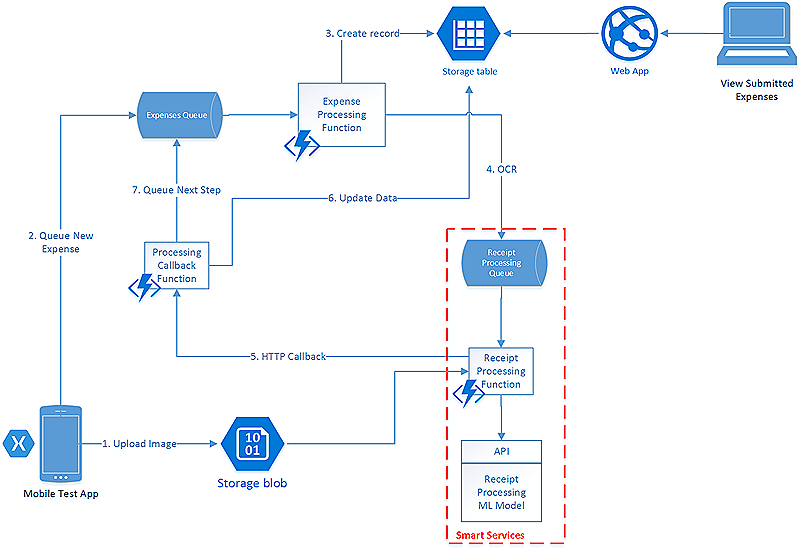
All the modules within Information of Interest Extractor are implemented within Azure ML Studio for easy deployment as a web service, except for the Logo Recognizer, whose the model is built using Custom Vision resulting in a web service. This API is then called from within Azure ML Studio. Implementation of all the modules stated in the Information of Interest Extractor can be used within the Execute Python Script module as part of an Azure ML Studio experiment.
Further Work
Here are some other things we have tried but need further work.
Fast-R-CNN (CNTK implementation)
We found that if we can increase the reliability of OCR, the better quality of text extracted may help to improve the information extraction process. CNTK’s Fast-R-CNN was initially tested in an attempt to create both word- and character-level recognition. Note that there is a Faster-R-CNN with similar function.
A note on Selective Search
At the time of testing (May 2017), we found that first part of the algorithm, Selective Search (SS), is suitable for images of natural scenes with rich colour and of a certain minimum size. However, it struggles to propose new Regions of Interest (ROI) when images mainly consist of black characters on a white-ish background (that is, a lack of colour richness and complex fine patterns in a small region). Meanwhile, there are possible alternatives to Selective Search. The simplest way is naively shifting the bounding box (labelled box) to the top, bottom, left, or right by a small amount. This approach generates multiple regions of interests, before feeding the ROIs into the network.
Conclusion
Here, we show an example technique where receipt processing can be automated using a combination of text extraction and image recognition techniques, together with some challenges. If you have any comments, please share with us in the comments below.