
At Microsoft, we are working with a number of car manufacturers on processing telemetry streams. One of the key business scenarios for the incoming real-time car telemetry is to offer real-time driver risk scoring for end user driving guidance applications, fleet administration, and usage-based insurance scenarios. This risk scoring is accomplished by combining telemetry data including speed, braking, and acceleration over a time window to produce an aggregate risk score for the driver.
As we connect more devices to the internet, the amount of data and context we collect from these devices is increasing geometrically. The conventional solution to processing these large scale sets of information is to process it Map-Reduce style with systems like Apache Hadoop. However, for some problems, the latency in using a batch system does not enable you to exploit this incoming data in a timely enough manner to be applicable to certain business use cases.
Overview of the Solution
The real time, and incremental, nature of the problem means that we couldn’t use Hadoop, so instead we opted to use Apache Storm. Azure’s HDInsight provides a very convenient hosted solution of this platform that makes it very easy to deploy and operate.
In our solution, we are using Nitrogen (http://nitrogen.io/ ), a set of open source components that connect devices to Azure, as a frontend message gateway for data collection and to provide identity and authorization services for the cars. These messages are fed into both Table Storage (for long term storage and querying) and Event Hub in Azure, which acts as a buffer that continuously pushes messages into the Storm topology that transforms it into the form that is needed for our Azure ML classifier.
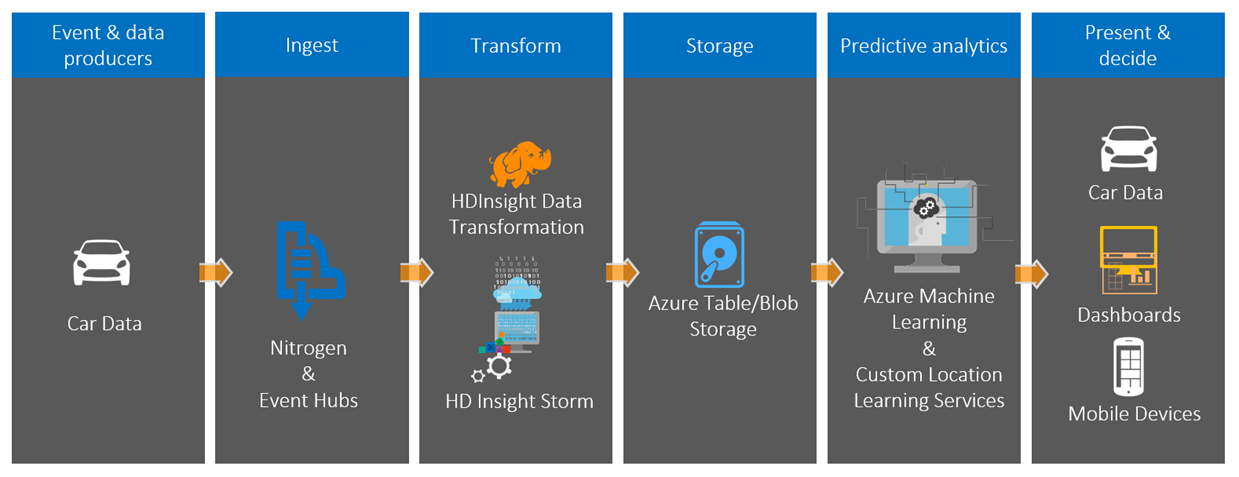
Figure 1: End to End Components of the Data Pipeline
Apache Storm works on data using a stream model. In Storm’s parlance, Spouts emit tuples of data that Bolts then process and optionally emit transformed tuples of data to other downstream Bolts. Figure 1 shows an example topology. Spouts can be consumed by multiple Bolts and Bolts can consume multiple tuple streams.
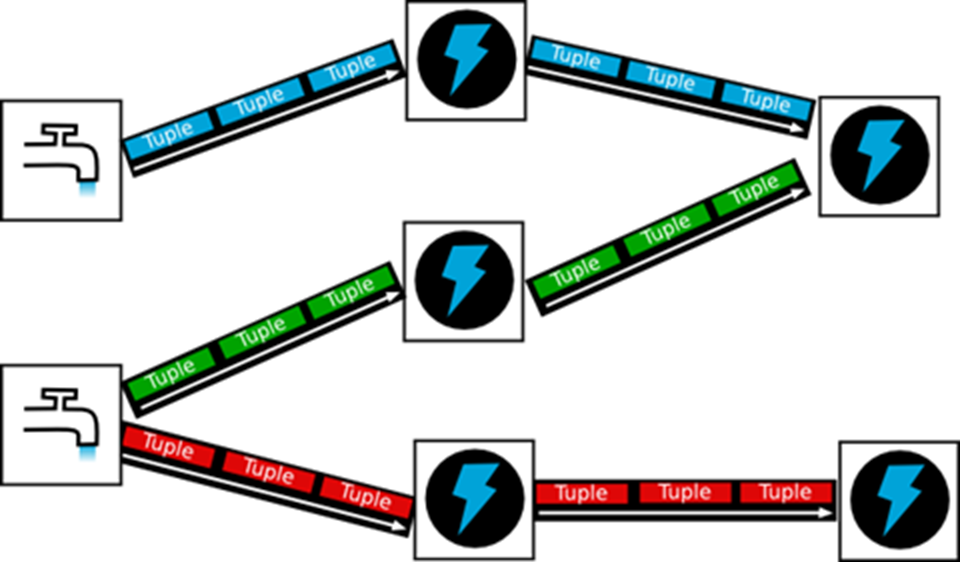
Figure 2: Apache Storm Topology
Our Storm topology performs two tasks: location cleansing and generating derivative data. In any real world telemetry solution, you inevitably end up with erroneous data. In this solution, we are receiving GPS location data from within the car that is occasionally very inaccurate, usually due to degraded GPS satellite reception. We use a set of bolts to detect erroneous data and remove it using MSR-developed algorithms for trip cleansing.
This cleansed location data is passed into a downstream Bolt that uses it to detect and emit sudden braking, fast acceleration, lane changes, swerves, and turn events. These events are fed into a trained Azure ML driver risk classifier that uses them to classify driving risk for a windowed segment. All of this happens in near real time, allowing applications to surface risky driving to the driver for training purposes and/or to fleet administrators immediately.
One of the other benefits of using a stream-based approach is that it is incremental. We process the data as it arrives and don’t have to manage creating batch jobs of it. This is also one of the challenges: you have to scale the size of your HDInsight Storm cluster to match the incoming stream data rate. Azure Event Hub helps us in this respect: it buffers data spikes so we can size our cluster at just above the average rate expected and not at peak rate.
Code Artifacts and Opportunities for Reuse
Spouts and Bolts can be written in a combination of C# and Java. The Event Hub spout is a Java jar file while the rest of our topology is in C#. We’ve open sourced a simple skeleton topology for building your own Storm solution at http://github.com/timfpark/data-pipeline that includes a preconfigured Event Hub to Storm spout and instructions on how to configure it. This provides a solid foundation to start from to build your own set of Spouts and Bolts and a Topology for local development runs and for submitting it to a hosted Storm cluster.
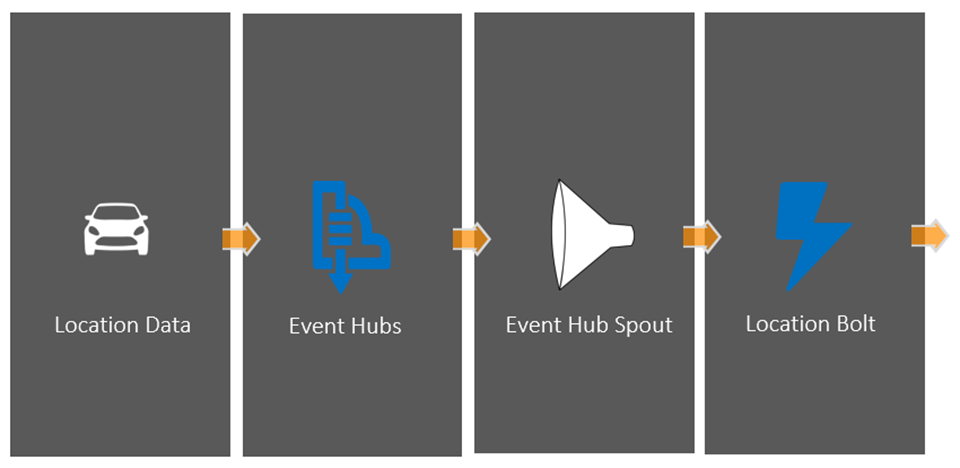
Figure 3: Overview of Sample Storm Pipeline
Additionally, in the course of building the Bolts for our topology, it became clear that the Storm architecture has some idiosyncrasies that make it difficult to decouple the business logic of processing data from the Storm-specific code for managing the appropriate pieces and ensuring reliability semantics. We used Reactive Extensions to decouple the Storm-specific code from the business logic in an elegant fashion. More details are available at http://www.mikelanzetta.com/storm-bolts-using-reactive-extensions.html.