
This blog post demonstrates how you can use Spark 3 OLTP connector for Azure Cosmos DB (now in general availability) with Azure Databricks to ingest and read the data.
What you will learn from this blog post?
- How to add the spark 3 connector library to an Azure Databricks cluster.
- How to use the Catalog API to create a database and a collection in the Azure Cosmos DB account.
- The differences between the partitioning strategies used.
- How to ingest data into the Azure Cosmos DB. (Currently, the Spark 3 OLTP connector for Azure Cosmos DB only supports Azure Cosmos DB Core (SQL) API, so we will demonstrate it with this API)
Scenario
In this example, we read from a dataset stored in an Azure Databricks workspace and store it in an Azure Cosmos DB container using a Spark job. Tip: You can display the datasets in the workspace by executing the below in a notebook: display(dbutils.fs.ls(“/databricks-datasets”)).
In this example, we use a dataset found in the Databricks workspace at dbfs:/databricks-datasets/COVID/coronavirusdataset/SeoulFloating.csv.
Preparing the Azure Databricks cluster
We used a two-node cluster with the Databricks runtime 8.1 (which includes Apache Spark 3.1.1 and Scala 2.12). You can find more information on how to create an Azure Databricks cluster from here.
Once you set up the cluster, next add the spark 3 connector library from the Maven repository. Click on the Libraries and then select the Maven as the Library source.
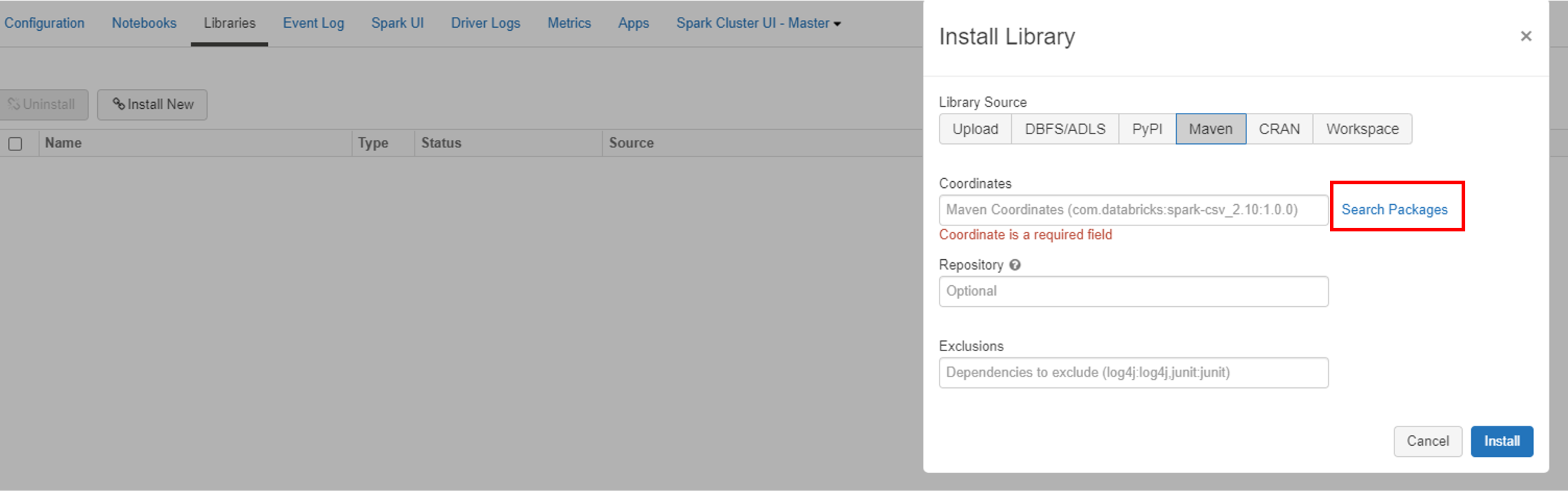
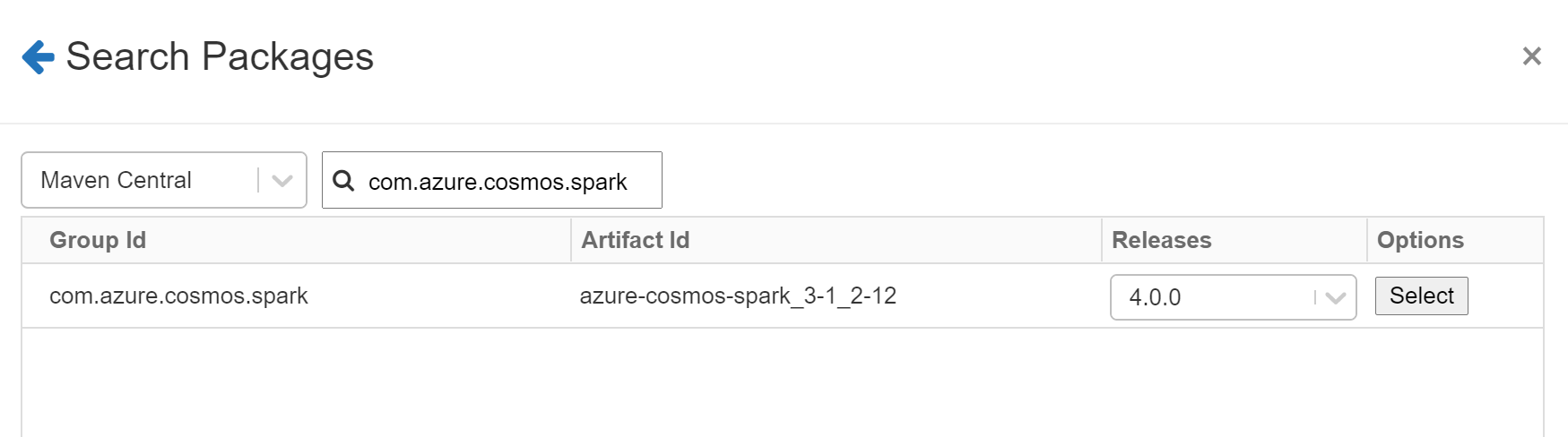
Next, click on the search packages link. Type “com.azure.cosmos.spark” as the search string to search within the Maven Central repository.
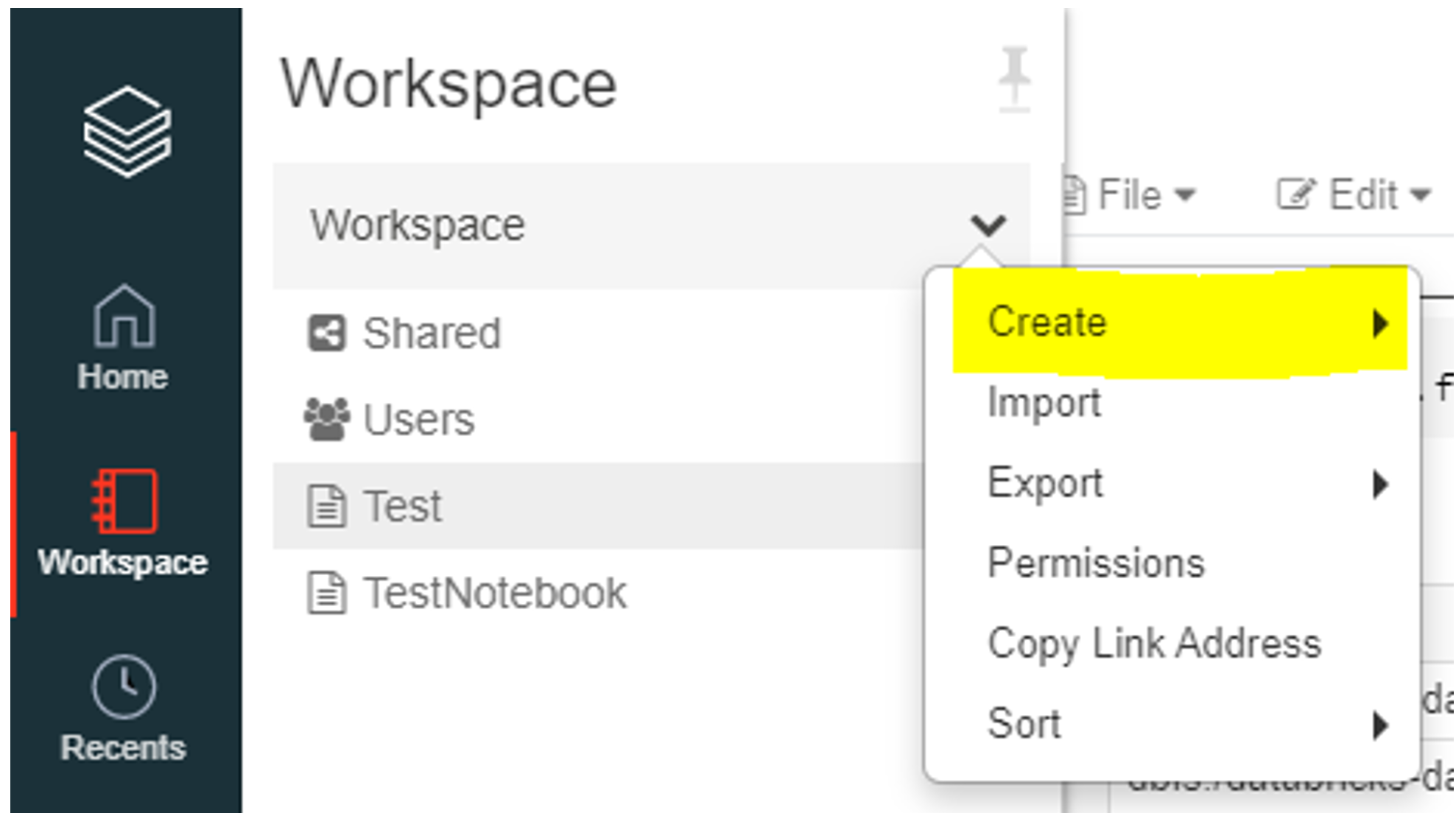
Once the library is added and installed, you will need to create a notebook and start coding using Python.
Read data from the dataset
Next, we will read data from a dataset and store it in a Spark DataFrame. Run the below snippet in the newly created notebook.
df = spark.read.format('csv').options(header='true').load('dbfs:/databricks-datasets/COVID/coronavirusdataset/SeoulFloating.csv')
Schema:
date:string, hour:string, birth_year:string, sex:string, province:string, city:string, fp_num:string
Create the database and collection using the Catalog API
Run the below snippet in the notebook to create the database and the collection in the Azure Cosmos DB account. Please refer here for more information. For the complete
cosmosEndpoint = "https://REPLACEME.documents.azure.com:443/"
cosmosMasterKey = "REPLACEME"
cosmosDatabaseName = "sampleDB"
cosmosContainerName = "sampleContainer"
spark.conf.set("spark.sql.catalog.cosmosCatalog", "com.azure.cosmos.spark.CosmosCatalog")
spark.conf.set("spark.sql.catalog.cosmosCatalog.spark.cosmos.accountEndpoint", cosmosEndpoint)
spark.conf.set("spark.sql.catalog.cosmosCatalog.spark.cosmos.accountKey", cosmosMasterKey)
spark.sql("CREATE DATABASE IF NOT EXISTS cosmosCatalog.{};".format(cosmosDatabaseName))
spark.sql("CREATE TABLE IF NOT EXISTS cosmosCatalog.{}.{} using cosmos.oltp TBLPROPERTIES(partitionKeyPath = '/id', manualThroughput = '1100')".format(cosmosDatabaseName, cosmosContainerName))
Ingesting the data
Here we used the write strategy as “ItemAppend” to ignore conflicts. The concurrency of the write operation will be determined by the available number of Spark executors.
#Set the write configuration
writeCfg = {
"spark.cosmos.accountEndpoint": cosmosEndpoint,
"spark.cosmos.accountKey": cosmosMasterKey,
"spark.cosmos.database": cosmosDatabaseName,
"spark.cosmos.container": cosmosContainerName,
"spark.cosmos.write.strategy": "ItemOverwrite",
}
#ingest the data
df\
.toDF("date","hour","birth_year","sex","province","city","id")\
.write\
.format("cosmos.oltp")\
.options(**writeCfg)\
.mode("APPEND")\
.save()
Reading the data
When reading the data, we can use the partitioning strategy to improve the read efficiency. For example, the partitioning strategy configuration supports four types of strategies: Default, Custom, Restrictive or Aggressive.
Default: will create a number of Spark partitions based on the storage size of a Cosmos DB physical partition
Custom: will create the number of partitions based on the value set for spark.cosmos.partitioning.targetedCount.
Restrictive: will create 1 Spark partition per Cosmos DB physical partition – this would be useful for very selective queries only returning small datasets.
Aggressive: will use 3 times the partition limit used in the Default strategy.
#Set the read configuration
readCfg = {
"spark.cosmos.accountEndpoint": cosmosEndpoint,
"spark.cosmos.accountKey": cosmosMasterKey,
"spark.cosmos.database": cosmosDatabaseName,
"spark.cosmos.container": cosmosContainerName,
"spark.cosmos.partitioning.strategy": "Restrictive",
"spark.cosmos.read.inferSchema.enabled" : "false"
}
#Read the data into a Spark dataframe and print the count
query_df = spark.read.format("cosmos.oltp").options(**readCfg).load()
print(query_df.count())
Wrap Up
In this blog post, you learned how to use the Spark 3 OLTP connector for Azure Cosmos DB Core (SQL) API with Azure Databricks workspace and was able to understand how the Catalog API is being used. You also learned the differences between the partitioning strategies when reading the data from Azure Cosmos DB. This is a simple and straightforward example that was demonstrated that can be extended to various other dimensions such as integrating with Kafka to ingest data into Azure Cosmos DB or use change feed with Spark structured streaming. Visit the Spark Connector docs page for more information.
Source Code
You can find the Python notebook in GitHub: Azure-Samples/spark-3-cosmos-db-connector (github.com)
Resources
- https://docs.microsoft.com/azure/cosmos-db/create-sql-api-spark
- https://docs.microsoft.com/azure/hdinsight/apache-kafka-spark-structured-streaming-cosmosdb
- https://github.com/Azure/azure-cosmosdb-spark/wiki/Stream-Processing-Changes-using-Azure-Cosmos-DB-Change-Feed-and-Apache-Spark
- https://azure-sdk-for-java/migration.md at master · Azure/azure-sdk-for-java · GitHub – Migrating from the Azure Cosmos DB Spark Connector for Spark 2.4 to the new connector for Spark 3
Is there a way to pass custom schema while reading from cosmos? I have container with documents having field value as array of object. when I read this and display the filed value is coming as empty. Any idea on this? when I check schema on this field its identified as string
Eg {“propery1”: [{“key”:”value1″},{“key”:”value2″}] }
also could not work with custom query. Getting exception config not recognizing property- spark.cosmos.read.customQuery.
Thank you for the question. You can use the below snippet for using custom schema.
customSchema = StructType([
StructField(“id”, StringType()),
StructField(“name”, StringType()),
StructField(“type”, StringType()),
StructField(“age”, IntegerType()),
StructField(“isAlive”, BooleanType())
])
df = spark.read.schema(schema).format(“cosmos.oltp”).options(**cfg)\
.load()
Please let me know if you have further questions.