

This blog is co-authored by Rodrigo Souza.
We are excited to announce that mirroring Azure Cosmos DB databases in Microsoft Fabric is now available to all customers. You can seamlessly bring your databases into Microsoft OneLake, enabling no-ETL, near real-time insights on your data.
Many organizations want to transform their businesses by reacting quicker to any changes in their business environment or market conditions in real time. Bringing their data together, which is distributed across cloud and on-premises, can often be complex and difficult to manage. They need complex processes to analyze this data without impacting mission-critical workloads. As a result, this increases overall latency to access the data, leading to frequent delays in generating critical business insights, often by hours.
Mirroring empowers you to bring data from various sources such as Azure Cosmos DB, Azure SQL Database, Snowflake into Microsoft OneLake, without the need for complex ETL pipelines. When combined with the rest of your organization’s data in OneLake, this helps unify your data estate, removing data silos. We plan to expand mirroring to more data sources soon.
Accessing your Cosmos DB data in near real-time allows you to build advanced analytics, BI, and AI solutions using Microsoft Fabric, to drive quicker decision-making and enhanced experiences for your customers.
What to expect from mirroring
Mirroring seamlessly replicates your Azure Cosmos DB database into Microsoft OneLake using an open-source delta format. Mirroring will replicate your source database into OneLake at setup and then it will incrementally replicate any inserts, updates, and deletes made in your Cosmos DB database in real-time to OneLake. These changes will be available in Fabric within a few minutes of landing in your database.
To use mirroring, you must enable the continuous backup feature on your Azure Cosmos DB account. Once you set up mirroring, the replication is automatic and incremental, without any impact on the performance of your transactional workloads or requests units (RUs).
Mirroring automatically adds columns in Fabric tables for new properties and handles compatible data type changes to manage any schema evolution.
Currently, this capability is available for the NoSQL API.
What customers are saying about Mirroring
In November last year, we announced private preview of mirroring. We received great feedback from preview customers.
“At Unite Digital, our primary data storage solution is Cosmos DB. To facilitate reporting, we conduct daily ETL processes that transfer data from Cosmos DB to Fabric. The introduction of Cosmos DB Mirroring for Fabric presents an opportunity to streamline this process significantly, providing near real-time data availability for reporting purposes within Microsoft Fabric. This integration has proven to be straightforward to implement and has functioned flawlessly.
The capability to offer near real-time reporting in a domain where the norm is a 24–48-hour turnaround time for reports serves as a distinct competitive edge. We have plans to phase out our traditional ETL processes in favor of transitioning entirely to Cosmos DB Mirroring for Fabric upon its general availability.”
Shahid Syed, Director of Technology and Security Compliance, Unite Digital
“Cosmos DB mirroring into the common data store, that is Fabric will allow us to cross-query against other SQL databases that also get mirrored. This ability will change how quickly we are able to innovate in our ever-changing data world. Very excited to see further development and innovation on Fabric and its related data-verse!”
Jacob Corey, VP of Data Solutions, Netrush, LLC
“We are really excited about the capabilities that Cosmos DB Mirroring brings to Microsoft Fabric. In our preview testing we found that DB Mirroring not only simplified data ingestion of JSON and API data sources but was 5 to 10x quicker than our current 3rd party ETL ingestion approach. It will also be much more cost effective for large datasets. We can’t wait to show our Interloop customers the benefits of this new capability. “
Jordan Berry, CTO & Co-Founder of Interloop
Fabric experiences on mirrored data
You can now view replication status, stop, and start the replication from the mirrored database.
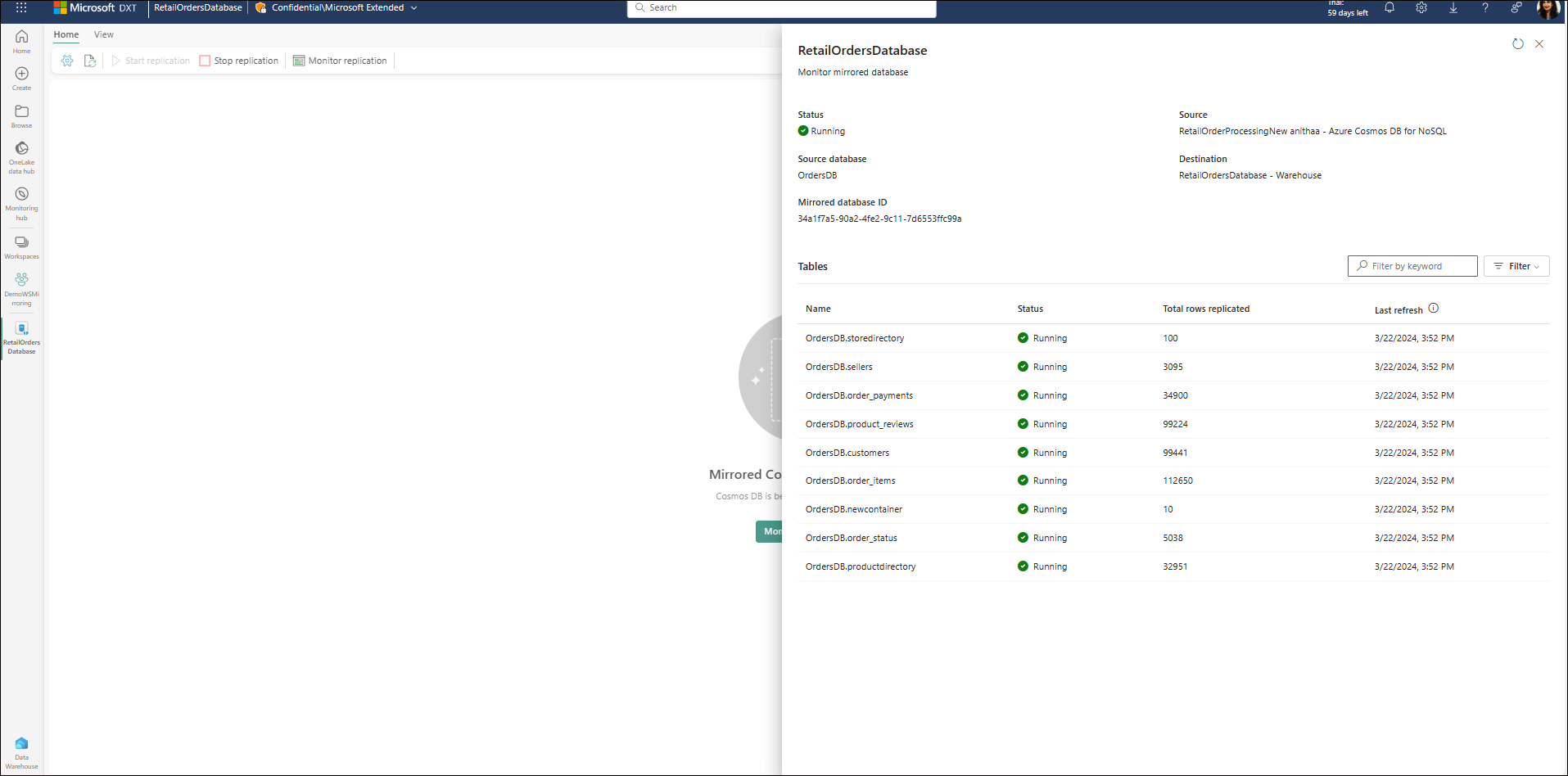
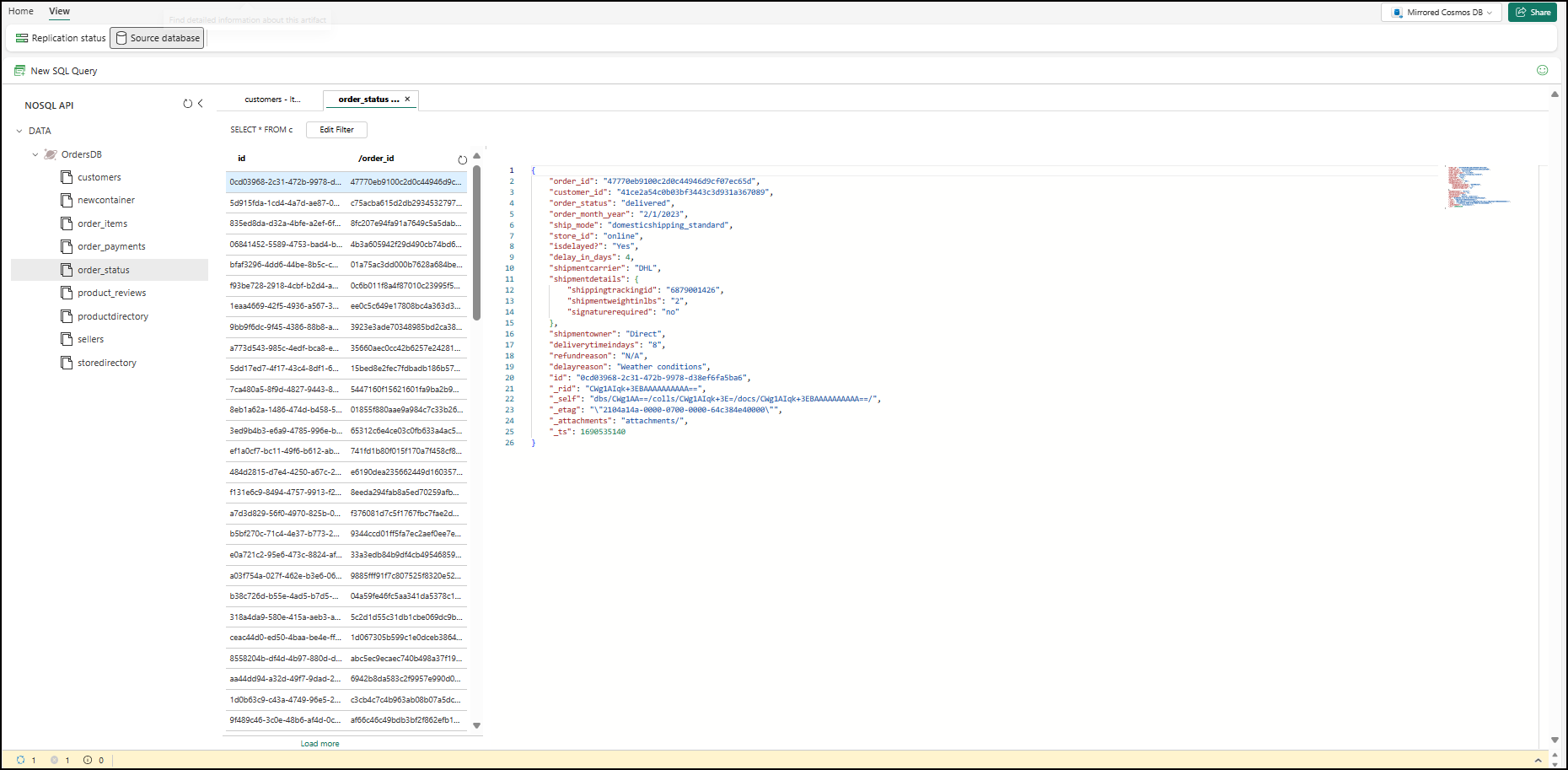
Access your source database in read-only mode, using Azure Cosmos DB data explorer integrated into Fabric. You can view all your collections in the source database, and query them in Fabric, as you would from Azure portal. Fabric prohibits writing to the source database using data explorer.
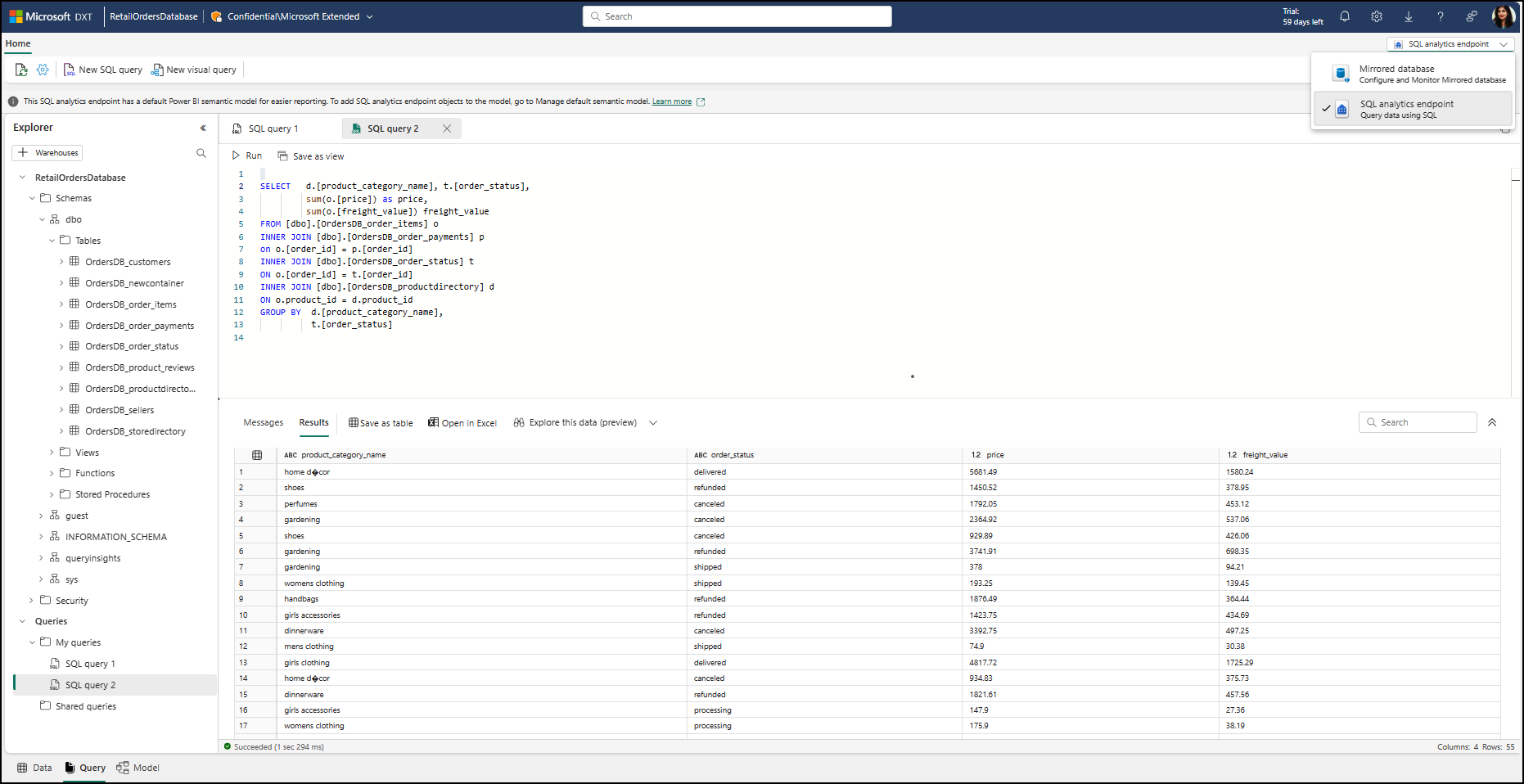
Join and analyze data across Azure Cosmos DB containers from SQL analytics endpoint, that is automatically created for your mirrored database. This query is run on Fabric, on the data replicated into OneLake.
In addition, you can access data in a mirrored database without further data movement for following experiences:
- Build BI reports with a single click and use built-in copilot enhancements in Fabric.
- Seamlessly join data across different mirrored databases, Lakehouses and Warehouses. You can do star-schema joins and transformations for medallion architecture.
- Add shortcuts to mirrored database in Lakehouse and analyze this in Fabric notebooks using Spark.
- Explore mirrored data directly from Azure Databricks, Azure HDInsight services.
- Access OneLake files directly using Azure Storage Explorer or OneLake File Explorer.
Pricing
Fabric will offer mirroring free of charge for the compute used for replicating your data and the storage used in OneLake. Fabric will not allocate the compute used for replicating your data from your Fabric capacity.
If you query the mirrored data in SQL endpoint, Lakehouse, Power BI, notebooks etc., standard charges apply. For more information, see Fabric pricing.
Continuous backup is a prerequisite for mirroring Azure Cosmos DB database.
- You don’t accrue any extra cost if you already enabled continuous backup before mirroring.
- If you enable continuous backup specifically for mirroring, you will incur the price associated with the backup feature. For more information, see Azure Cosmos DB pricing.
- If you use data explorer to view the source Cosmos DB data in Fabric, you will accrue costs based on Request Units (RU) usage.
Existing Azure Synapse Link customers
For no-ETL replication, mirroring does not rely on the analytical store as its source.
Mirroring also uses a different storage format compared to Synapse Link, using open-source Delta format. Some of the limitations of analytical store around schema constraints, handling nested data don’t apply to mirroring. Fabric also offers built-in improvements to enhance query performance when using OneLake.
You can enable or continue to use Azure Synapse Link on the same databases/collections as mirroring.
During its preview phase, mirroring only supports non-production workloads. If you are using Synapse Link for production workloads, please continue to use this.
Getting started
To start using the feature, you must enable tenant admin switch. Otherwise, the feature will not be available for your Fabric workspace. For more information, please visit “Enable Mirroring”
To learn more about mirroring, please visit our documentation. You can read more on mirroring on our Fabric blog.
For any questions or feedback, please reach out to our team at fabriccosmosdbmirror@microsoft.com.
About Azure Cosmos DB
Azure Cosmos DB is a fully managed and serverless distributed database for modern app development, with SLA-backed speed and availability, automatic and instant scalability, and support for open-source PostgreSQL, MongoDB, and Apache Cassandra. Try Azure Cosmos DB for free here. To stay in the loop on Azure Cosmos DB updates, follow us on Twitter, YouTube, and LinkedIn.
0 comments