

Overview
Azure Cosmos DB Kafka connector had been updated recently and several new features were delivered as part of the v1.6.0 release based on the feedback and requirements of several customers implementing it as part of their application modernization journey. In this blog post – I will share details about those improvements and introduce you to the new connector features and use cases they are targeted to solve.
Azure Cosmos DB Kafka Sink and Source connector were released in 2021 and are available for both open-source Kafka deployments as well as part of Confluent Cloud to help simplify data streaming and even-driven application modernization between Kafka and Azure Cosmos DB. Check out the recent Cosmos Live TV video episode on Confluent Kafka Connector and Azure Cosmos DB integration examples and use cases.
Real World Use Cases driving performance improvements
While deploying Azure Cosmos DB Kafka connector in some real-world scenarios requiring high throughput events ingestion into Azure Cosmos DB configured with Global Replication across multiple regions, we discovered several areas of improvement:
- Need to optimize high volume and throughput of events ingestion/sink
- Need to improve the handling of significant spikes or bursts of events which often can be unpredictable in real-world scenarios
- Need to improve failure handling/recoverability and client-side retries in certain scenarios
- Need more control over Azure Cosmos DB connection options to allow different control options for fine-grained Kafka connector client-side resource controls.
Luckily most of those features and controls were already available in the latest Azure Cosmos DB JAVA SDK and we were able to natively integrate them in the Azure Cosmos DB Kafka Connector as part of this latest update. Below you can find details about those improvements.
Retry Policy improvements for SINK connector
First, we improved native Azure Cosmos DB 429/throttle error handling on the Kafka Connector client side across all workers which is now retried automatically and indefinitely. In addition to this, you can now control maxRetryCount for any other transient write errors as part of the Kafka sink connector using the following Sink parameter.
| Name | Type | Description |
| connect.cosmos.sink.maxRetryCount | int | Max retry attempts on transient write failures. By default, it is 10 times. NOTE: This is different from max throttling retry attempts, which are infinite |
This significantly improved Azure Cosmos DB Kafka sink connector stability and error handling across workers during high volume bursts when write concurrency may exceed Azure Cosmos DB’s provisioned throughput while also providing a new explicit way to control retry for any other intermittent write issues which may leave Connector in a partially failed state.
Azure Cosmos DB Kafka Connector Client Connection Pooling Improvements
We also added several performance-oriented options which already existed in Azure Cosmos JAVA v4 SDK to Azure Cosmos DB Kafka Sink connector and they are now available as additional Sink parameters:
- By default Azure Cosmos DB Kafka sink connector process all messages serially by each partition/worker. While this allows for the most granular level of serialization – this is not the most efficient way to write a high volume of events into Azure Cosmos DB which is usually improved with batching. Since natively both underlying Azure Cosmos DB Java SDK and Kafka both support batching as well to help with this we added existing BULK support from JAVA SDK to Azure Cosmos DB Kafka Sink connector which can now be controlled by the following parameter and is now the default option.
This Bulk mode will be used by default Kafka batch size for every partition worker and can significantly improve resource utilization on both client and Cosmos DB for high throughput events ingestion scenarios.
Example – Bulk Load of 2Million Documents ( avg size – 1.4Kb) into Azure Cosmos DB Container with 100,000 RU/s and 32 Kafka Partitions/Connector Tasks.
Test 1:
connect.cosmos.sink.bulk.enabled: false
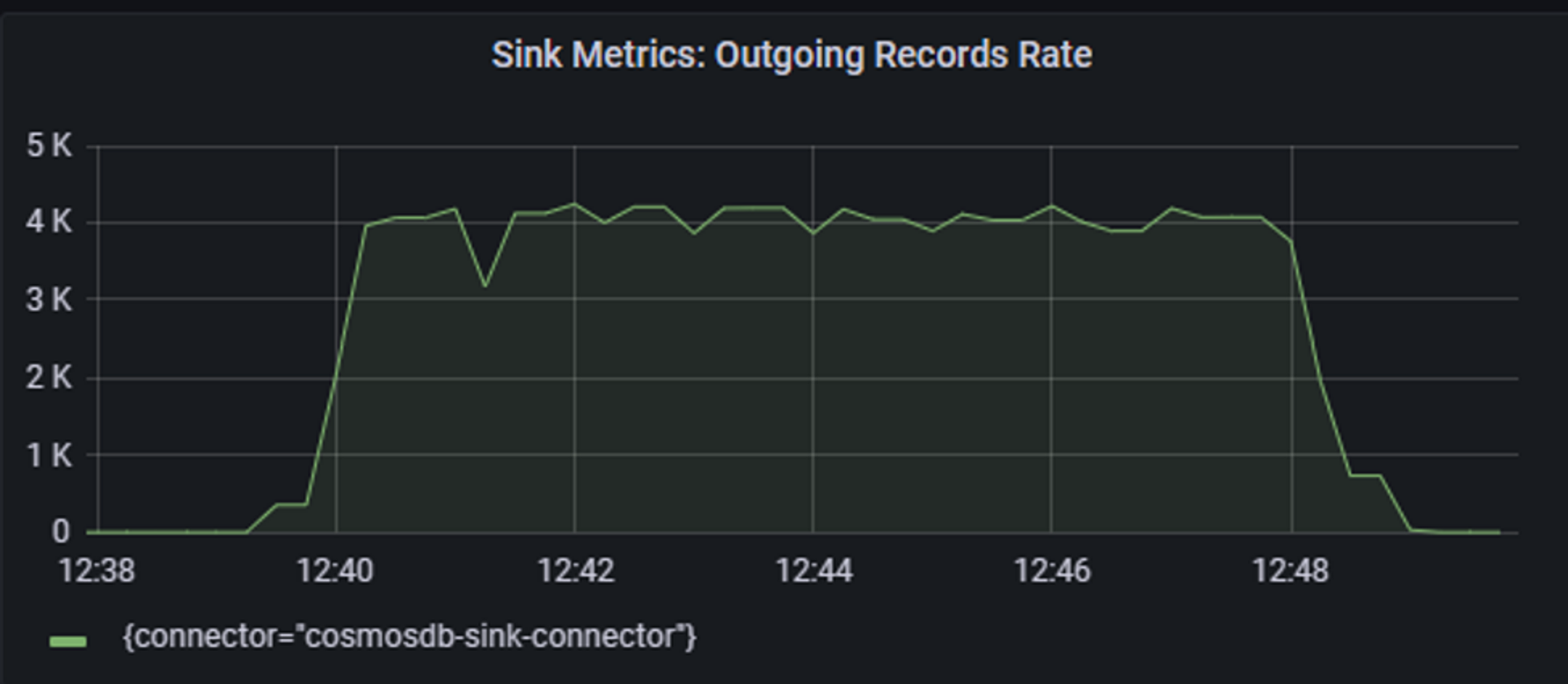
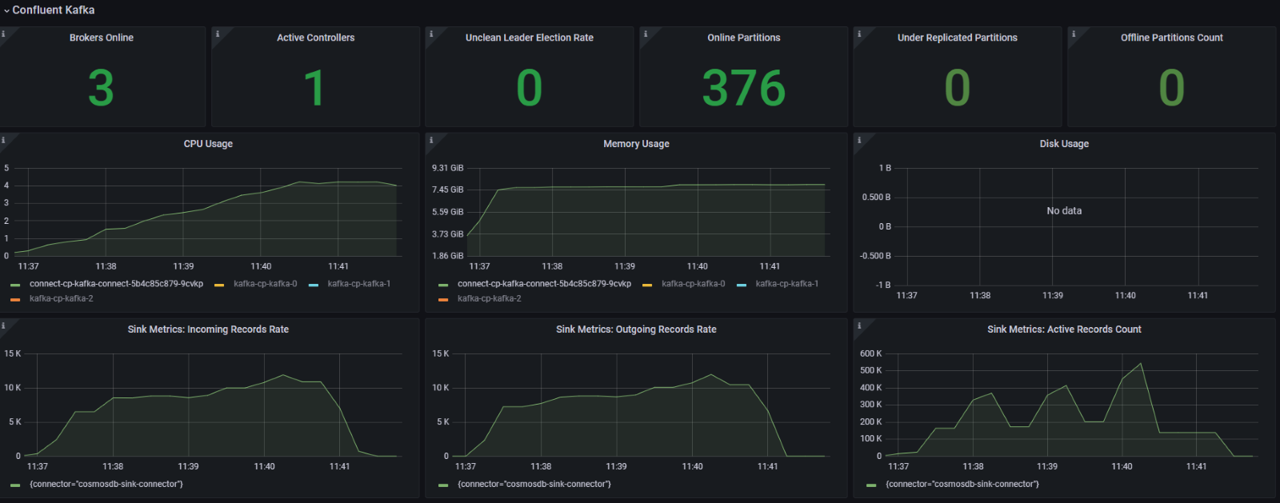
Test 2:
connect.cosmos.sink.bulk.enabled: true

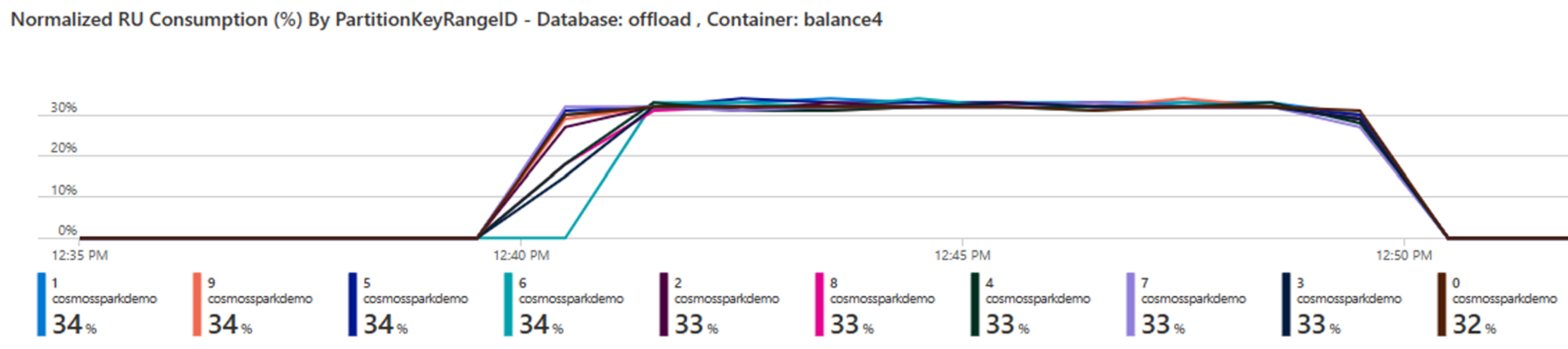
As you can see with bulk mode enabled connector is able to get 3x throughput improvement and saturate Azure Cosmos DB Throughput for the same number of workers.
- In addition to the new Bulk mode, we also added 2 other client slide connection tuning parameters to the Azure Cosmos DB Kafka Sink connector to help optimize Azure Cosmos DB client options (Direct or Gateway).
- By default Azure Cosmos DB JAVA SDK used by Kafka connector uses DIRECT mode. This connection mode is recommended for high throughput and lower latency DB operations as it is bypassing Azure Cosmos DB GATEWAY after initial connection and cluster topology discovery and will establish and use direct thread connections with all the back-end shards from the client connection pool directly. The trade-off for this connection mode is higher client-side CPU/memory usage if you test high throughput workloads which would have to create and manage many connections per partition/worker. If you are running Kafka with a high number of partitions, and connector tasks or using Kafka Connect on a smaller VM, sharing Connector compute with other processes and testing performance – you may run into some client-side bottlenecks and performance degradations which can be solved with the following parameter to allow for client-side connection sharing across different workers in DIRECT mode and reduce client-side threads and processing overhead in cases with large Kafka partition/worker counts.
-
Name Type Description connect.cosmos.connection.sharing.enabled boolean Flag to enable connection sharing between instances of cosmos clients on the same JVM. NOTE: If you have set ‘connect.cosmos.connection.gateway.enabled’ to true, then this configuration will not make any difference.
Test 1:
connect.cosmos.connection.sharing.enabled false
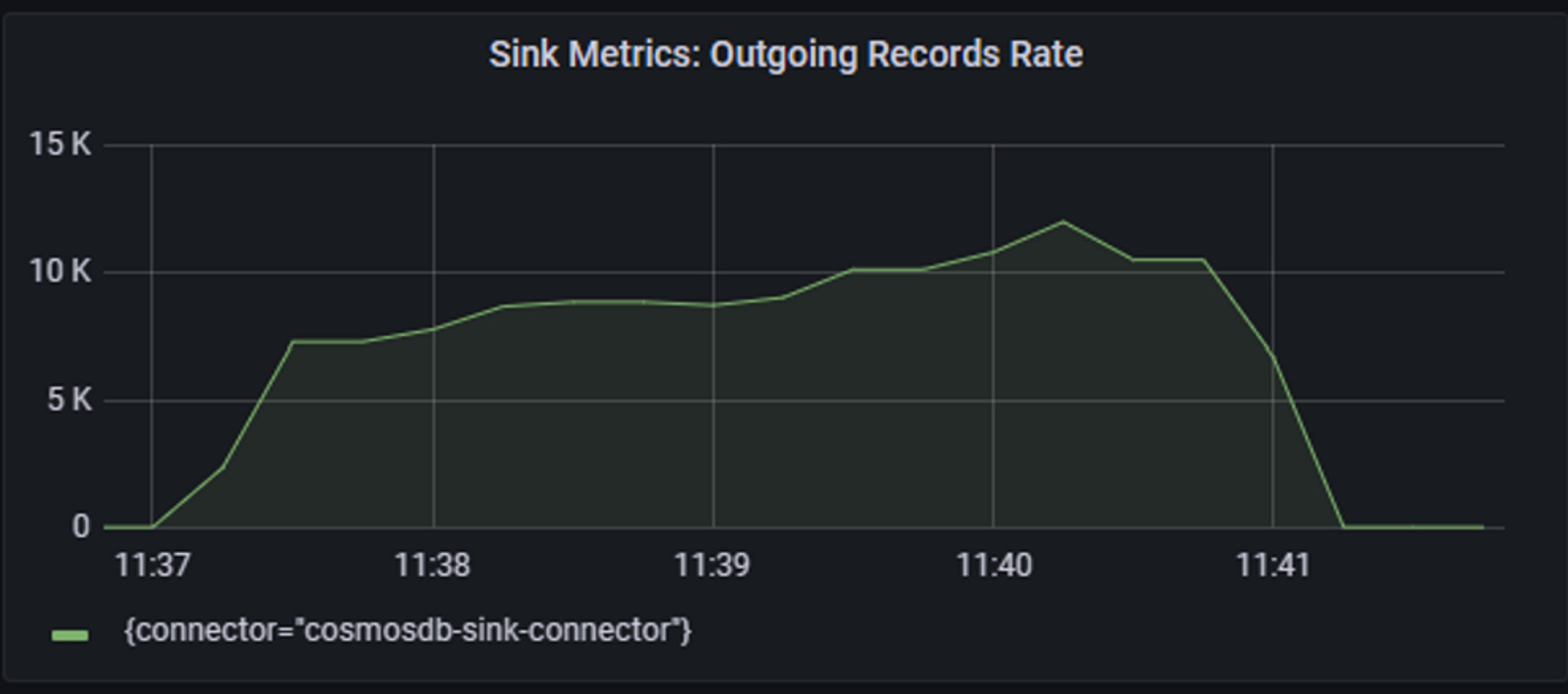
Test 2:
connect.cosmos.connection.sharing.enabled: true
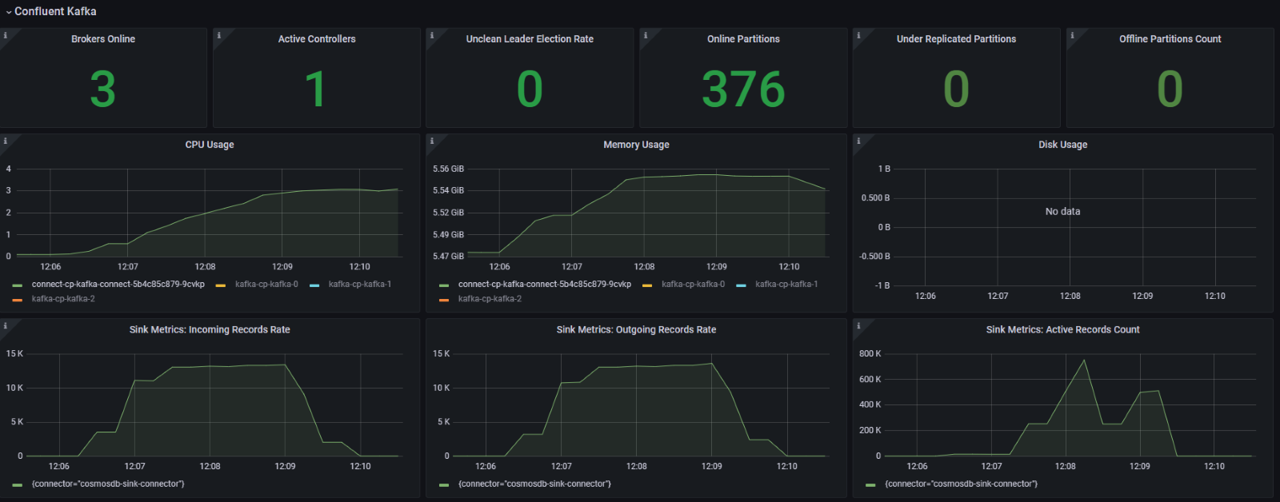
You can observe that in a second test with connection sharing enabled, there is better CPU/memory utilization on Kafka Connector/Client side and this directly resulted in better and more evenly balanced sink throughput utilization.
- An alternative option for Kafka Connect client-side connection overhead tuning in such cases is to use GATEWAY connection mode by setting this parameter where connection management to Azure Cosmos DB back-end nodes/partitions is abstracted and hidden under Cosmos DB Gateway:
Name Type Description connect.cosmos.connection.gateway.enabled boolean Flag to indicate whether to use gateway mode. By default it is false.
Test 3:
connect.cosmos.connection.gateway.enabled true
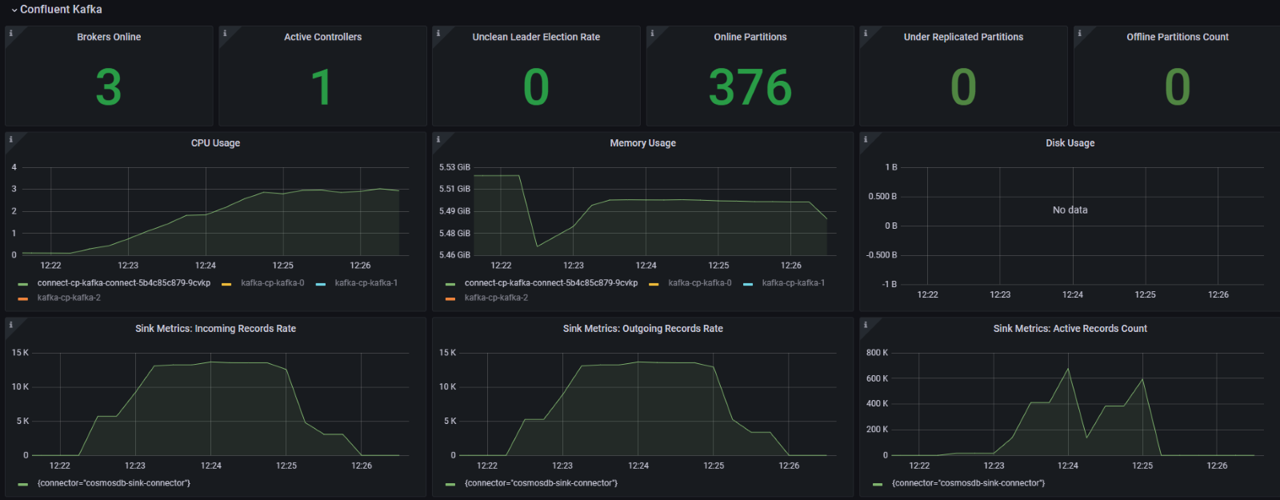
You can see that with Gateway mode enabled – client-side load metrics are similar/lower than direct mode with connection sharing and sink throughput metrics also about the same as the previous test.
This option is also recommended to be used in some security configurations (learn more about Azure Cosmos DB connectivity modes and different Port requirements here) where it is not acceptable to open a significant range of ports required by DIRECT mode and setting this parameter to GATEWAY mode will allow to only communicate on standard SSL 443 port between Kafka Connect and Azure Cosmos DB while hiding all the back-end network connection/ports complexity under Azure Cosmos DB Gateway.
Getting Started with Kafka Connector for Azure Cosmos DB
- Download the source and sink connectors from Confluent
- Download the source and sink connectors from Github
- Find examples of configuring the source connector in a self-managed or fully managed Kafka Connect cluster
- Find examples of configuring the sink connector in a self-managed or fully managed Kafka Connect cluster
- Find examples in Confluent’s blog here to create a fully managed Connect cluster with the Azure Cosmos DB sink connector on Confluent Cloud
Get Started with Azure Cosmos DB
Azure Cosmos DB is a fully managed NoSQL database for modern app development with SLA-backed speed and availability, automatic and instant scalability, and open-source APIs for MongoDB, Cassandra, and other NoSQL engines. Discover features or capabilities at www.AzureCosmosDB.com or get started for free. For up-to-date news on all things, Azure Cosmos DB be sure to follow us on Twitter, YouTube, and our blog.
The content was created by: Sergiy Smyrnov and Marcelo Fonseca
The content was edited by: Theo van Kraay, Kushagra Thapar, Annie Liang
0 comments