
Migrating relational data into Azure Cosmos DB SQL API requires certain modelling considerations that differ from relational databases. We discuss the important SQI API modelling concepts in our guidance on Data modelling in Azure Cosmos DB.
What follows is a sample for migrating data where one-to-few relationships exist (see when to embed data in the above guidance). The sample uses the Azure Cosmos DB Spark Connector. For more guidance on other migration options, please see Options to migrate data into Cosmos DB.
Order and Order Details
Here we are considering a simple order system where each order can have multiple detail lines. In this scenario, the relationship is not unbounded, and there is a limited number of detail lines that may exist for a given order. We can consider this a one-to-few relationship. This is a good candidate for denormalizion. Typically denormalized data models provide better read performance in distributed databases, since we will minimise the need to read across data partitions.
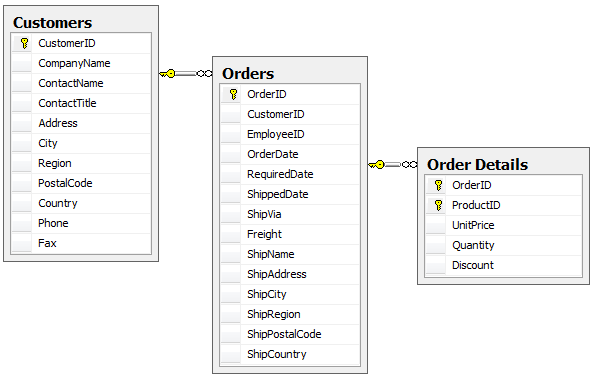
To migrate and merge order details into denormalized documents for each order, we will use Azure Databricks, an Azure managed service for Apache Spark. To configure the Cosmos DB Spark Connector in Databricks, you can follow the guidance in the Databricks documentation for Azure Cosmos DB. When this is done, you are ready to create a new Python Notebook. Start by configuring the source and target database connections in the first cell:
import uuid
import pyspark.sql.functions as F
from pyspark.sql.functions import col
from pyspark.sql.types import StringType,DateType,LongType,IntegerType,TimestampType
#JDBC connect details for SQL Server database
jdbcHostname = "jdbcHostname"
jdbcDatabase = "OrdersDB"
jdbcUsername = "jdbcUsername"
jdbcPassword = "jdbcPassword"
jdbcPort = "1433"
connectionProperties = {
"user" : jdbcUsername,
"password" : jdbcPassword,
"driver" : "com.microsoft.sqlserver.jdbc.SQLServerDriver"
}
jdbcUrl = "jdbc:sqlserver://{0}:{1};database={2};user={3};password={4}".format(jdbcHostname, jdbcPort, jdbcDatabase, jdbcUsername, jdbcPassword)
#Connect details for Target Azure Cosmos DB SQL API account
writeConfig = {
"Endpoint": "Endpoint",
"Masterkey": "Masterkey",
"Database": "OrdersDB",
"Collection": "Orders",
"Upsert": "true"
}
Next, add a new cell. Here, we will query the source Database (in this case SQL Server) for both the order and order detail records, putting the results into Spark Dataframes. We will also create a list containing all the order ids, and a Threadpool for parallel operations:
import json
import ast
import pyspark.sql.functions as F
import uuid
import numpy as np
import pandas as pd
from functools import reduce
from pyspark.sql import SQLContext
from pyspark.sql.types import *
from pyspark.sql import *
from pyspark.sql.functions import exp
from pyspark.sql.functions import col
from pyspark.sql.functions import lit
from pyspark.sql.functions import array
from pyspark.sql.types import *
from multiprocessing.pool import ThreadPool
#get all orders
orders = sqlContext.read.jdbc(url=jdbcUrl, table="orders", properties=connectionProperties)
#get all order details
orderdetails = sqlContext.read.jdbc(url=jdbcUrl, table="orderdetails", properties=connectionProperties)
#get all OrderId values to pass to map function
orderids = orders.select('OrderId').collect()
#create thread pool big enough to process merge of details to orders in parallel
pool = ThreadPool(10)
Below this, create a function for writing Orders into the target SQL API collection. This function will filter all order details for the given order id, convert them into a JSON array, and insert the array into a JSON document that we will write into the target SQL API Collection for that order:
def writeOrder(orderid):
#filter the order on current value passed from map function
order = orders.filter(orders['OrderId'] == orderid[0])
#set id to be a uuid
order = order.withColumn("id", lit(str(uuid.uuid1())))
#add details field to order dataframe
order = order.withColumn("details", lit(''))
#filter order details dataframe to get details we want to merge into the order document
orderdetailsgroup = orderdetails.filter(orderdetails['OrderId'] == orderid[0])
#convert dataframe to pandas
orderpandas = order.toPandas()
#convert the order dataframe to json and remove enclosing brackets
orderjson = orderpandas.to_json(orient='records', force_ascii=False)
orderjson = orderjson[1:-1]
#convert orderjson to a dictionaory so we can set the details element with order details later
orderjsondata = json.loads(orderjson)
#convert orderdetailsgroup dataframe to json, but only if details were returned from the earlier filter
if (orderdetailsgroup.count() !=0):
#convert orderdetailsgroup to pandas dataframe to work better with json
orderdetailsgroup = orderdetailsgroup.toPandas()
#convert orderdetailsgroup to json string
jsonstring = orderdetailsgroup.to_json(orient='records', force_ascii=False)
#convert jsonstring to dictionary to ensure correct encoding and no corrupt records
jsonstring = json.loads(jsonstring)
#set details json element in orderjsondata to jsonstring which contains orderdetailsgroup - this merges order details into the order
orderjsondata['details'] = jsonstring
#convert dictionary to json
orderjsondata = json.dumps(orderjsondata)
#read the json into spark dataframe
df = spark.read.json(sc.parallelize([orderjsondata]))
#write the dataframe (this will be a single order record with merged many-to-one order details) to cosmos db using spark the connector
#https://docs.microsoft.com/en-us/azure/cosmos-db/spark-connector
df.write.format("com.microsoft.azure.cosmosdb.spark").mode("append").options(**writeConfig).save()
Finally, we will call the above using a map function on the thread pool, to execute in parallel, passing in the list of order ids we created earlier:
#map order details to orders in parallel using the above function pool.map(writeOrder, orderids)
You should end up with records like the below for each order written to Cosmos DB, containing a JSON array of order details:
{
"OrderId": 4,
"CustomerID": 123,
"EmployeeID": 1574669833243,
"OrderDate": 1574669833243,
"RequiredDate": 1574669833243,
"ShippedDate": 1574669833243,
"details": [
{
"UnitPrice": 7.99,
"Discount": 4,
"Quantity": 1,
"ProductId": 227,
"OrderId": 4
},
{
"UnitPrice": 7.99,
"Discount": 8,
"Quantity": 1,
"ProductId": 308266,
"OrderId": 4
}
],
"id": "6ff9ca92-19cf-11ea-967a-00163e4c20f5",
"_rid": "VdgtAK23OMAFAAAAAAAAAA==",
"_self": "dbs/VdgtAA==/colls/VdgtAK23OMA=/docs/VdgtAK23OMAFAAAAAAAAAA==/",
"_etag": "\"270035d4-0000-1100-0000-5ded16b60000\"",
"_attachments": "attachments/",
"_ts": 1575818934
}
You can either run the Notebook as a one-off migration, or if the data needs to be moved regularly, you can schedule the Notebook in Databricks. If the migration is part of a complex data movement pipeline, you can include the Notebook as part of a pipeline in Azure Data Factory.
Get started
Create a new account using the Azure Portal, ARM template or Azure CLI and connect to it using your favourite tools. Stay up-to-date on the latest Azure #CosmosDB news and features by following us on Twitter @AzureCosmosDB. We are really excited to see what you will build with Azure Cosmos DB!
About Azure Cosmos DB
Azure Cosmos DB is a globally distributed, multi-model database service that enables you to read and write data from any Azure region. It offers turnkey global distribution, guarantees single-digit millisecond latency at the 99th percentile, 99.999 percent high availability, with elastic scaling of throughput and storage.
0 comments