
In my previous post, I explained how to use Azure Databricks and the Apache Spark collect_list function to perform a two-table relational data migration to NoSQL, using the embedding approach to support a one-to-many relationship. I used Apache Spark because at that time we didn’t have the right native functions in Azure Data Factory (ADF) to support this transformation. Well, now we have it and it is (not surprisingly) called collect. This function will take multiple values and aggregate them into an array. We can use collect to create arrays or long strings:
collect(ProductID) |
[52734, 734625, 742325, 946256, 245462] |
toString ( reduce ( collect (ProductID) , '', #item + ', ' + #acc, #result) ) |
“52734, 734625, 742325, 946256, 245462” |
Or we can use them to create more complex structures:
collect(@(prodId = ProductID,
qty = OrderQty)) |
[
{prodId: 52734,qty: 24},
{prodId: 734625,qty: 13},
{prodId: 742325,qty: 18},
{prodId: 946256,qty: 2},
{prodId: 245462,qty: 71}
] |
This post will show you how to migrate relational data to Azure Cosmos DB using only Azure Data Factory, with no code needed. The use case is exactly the same as in my previous post, I’m adding it here again for quick reference:
One-to-many relationships using the embedding approach
In some One-to-Many scenarios, the recommended approach is to Embed the many side into the one side, thus eliminating the need for joins. A common example is when we have a master/detail pair of tables like Order Header and Order Detail.
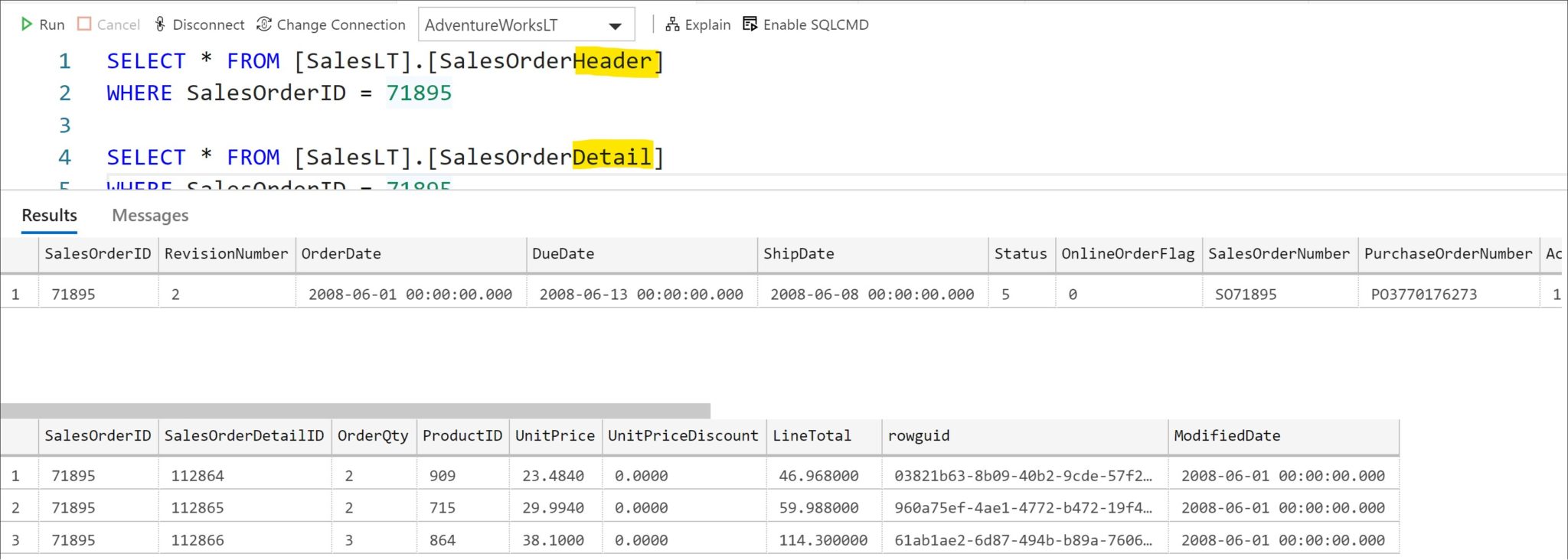
Here we have one record for the Order Header and three corresponding records for the Order Detail. In a relational world, we are required to join these two tables (by SalesOrderID) to get a complete picture of sales data. When using the embedded approach to migrate this data to an Azure Cosmos DB (Core SQL API), the data will look like a single document with data for the order, and an array of elements representing data for the detail..
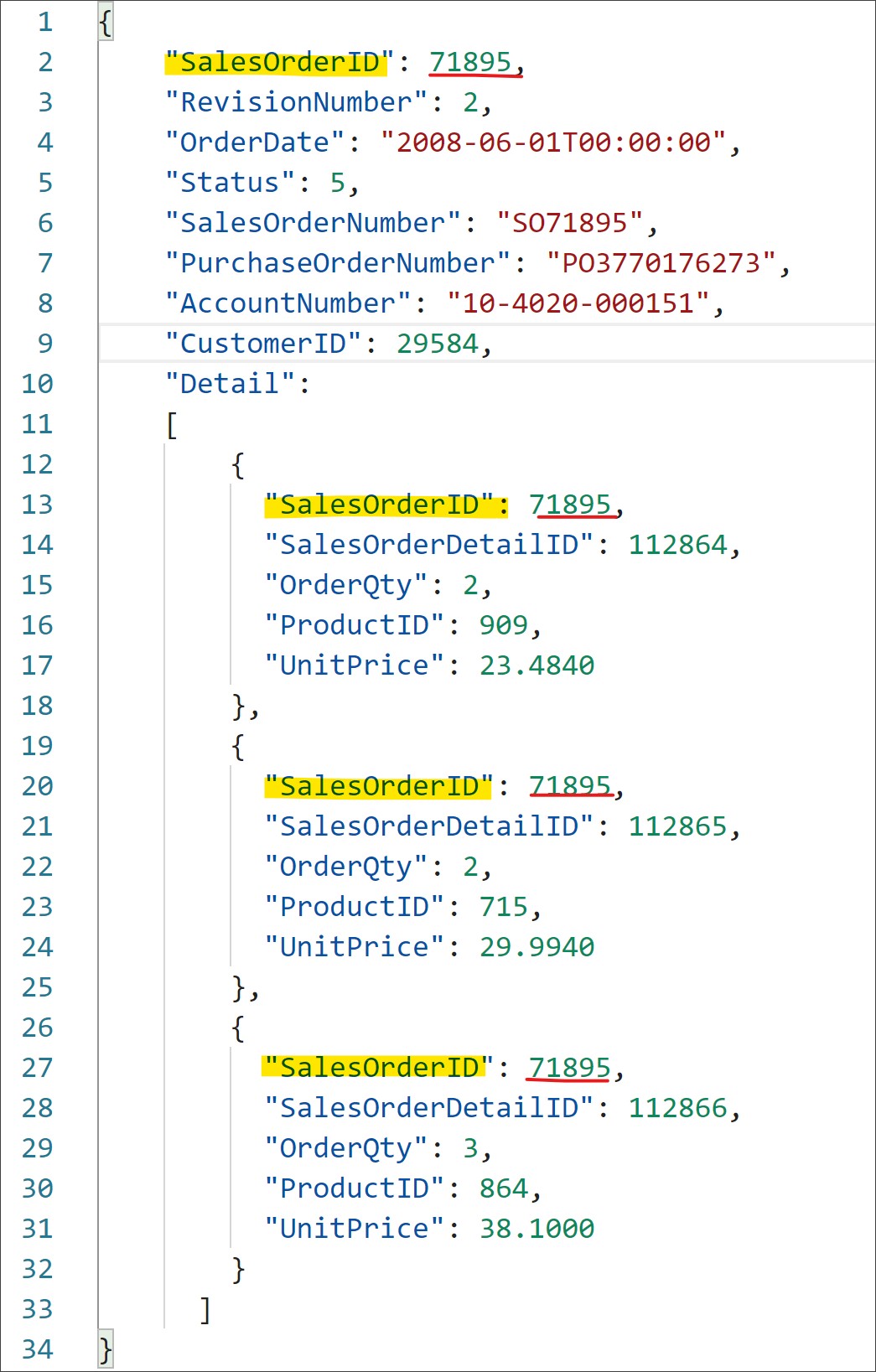
Notice that I left the SalesOrderID element on the embedded documents just for reference. The final implementation will remove these elements as they are not necessary anymore.
The solution: migrating relational data
The solution has a single Azure Data Factory pipeline with a single Mapping Data Flow activity that reads the relational data, transforms (embed) the data, and finally loads the data to migrate relational data into Azure Cosmos DB. The final data flow should look like this:

The DecimalToDouble transformation is required because Azure Cosmos DB can’t store Decimals with set precision. To create the required Mapping Data Flow:
- First we add two Data Sources: Sales Order Header and Sales Order Detail. Optionally, we could set a hash partition by SalesOrderID on both datasets in the Optimize options.
- Then, we add an Aggregate transform on the Sales Order Detail source grouping by SalesOrderID. We will add one single Aggregate column called Details. This will include all columns we want to “embed”. Make sure to wrap the structure into a
collectfunction. The expression for the Details field should be:collect(@(SalesOrderDetailID=SalesOrderDetailID, OrderQty=OrderQty, ProductID=ProductID, UnitPrice=toDouble(UnitPrice), UnitPriceDiscount=toDouble(UnitPriceDiscount), LineTotal=toDouble(LineTotal), rowguid=rowguid, ModifiedDate=ModifiedDate) )We use
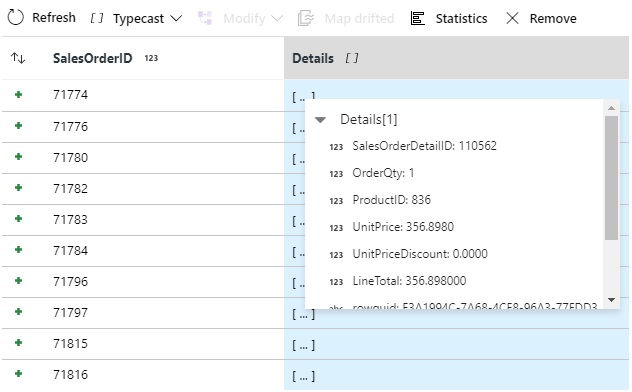
toDoublehere to make sure we don’t send decimals to Azure Cosmos DB. The Data Preview on the new Aggregate step should look like this:
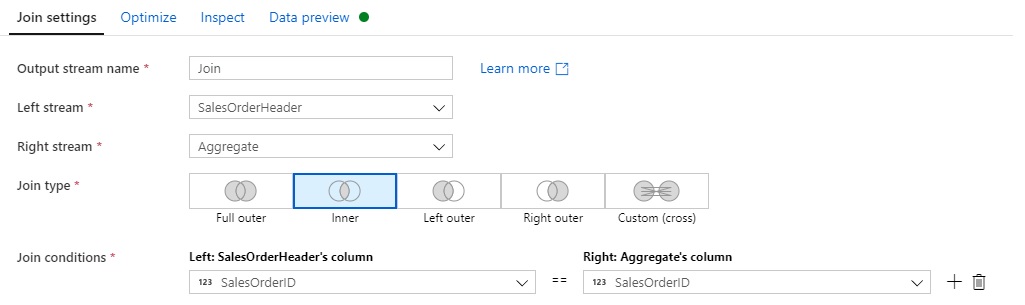
- Now we can Join the output of the Aggregate transformation with the original SalesOrderHeader source. We use an inner join by SalesOrderID. The output of step has all the columns we need to store in Azure Cosmos DB, and at the right level of granularity (SalesOrderID)

- Then add a Derived Column transformation to cast all remaining Decimal columns to double. These are the four Decimal columns coming from SalesOrderHeader:

- The final step is a Sink operation directly into our Azure Cosmos DB collection to load the transformed data. Make sure to Allow Schema Drift and to Remove Duplicated Input columns.
- Once loaded into the collection, documents will look like this from Azure Cosmos DB Data Explorer


Implementation Notes
Using Azure Data Factory Mapping Data Flows no-code approach makes it really easy to migrate relational data to Azure Cosmos DB. You can use this same approach to create even more complex multi-level hierarchies or create arrays of values when needed. Read more about how to use Collect with Azure Cosmos DB.
Get started with Azure Cosmos DB
- Create a new account using Azure Portal, ARM template or Azure CLI and connect to it using your favorite tools.
- Stay up-to-date on the latest #AzureCosmosDB news and features by following us on Twitter @AzureCosmosDB. We are really excited to see what you will build with Azure Cosmos DB!
About Azure Cosmos DB
Azure Cosmos DB is a fully managed NoSQL database for modern app development, with SLA-backed speed and availability, automatic and instant scalability, and open source APIs for MongoDB, Cassandra, and other NoSQL engines.
Hi @Tonio!
Thanks for a very interesting post.
What are the good use cases to apply this approach?
Thanks,
Elkhan Yusubov