

The Microsoft Fabric API for GraphQL™ provides a data access layer that enables you to query multiple data sources quickly and efficiently using a widely adopted and familiar API technology. This API abstracts the specifics of backend data sources, allowing you to focus on your application’s logic and deliver all the data a client needs in a single call.
Microsoft Fabric’s Mirroring enables you to seamlessly integrate your existing Azure Cosmos DB data with the rest of your data in Microsoft Fabric, eliminating the need for ETL. You can replicate your Azure Cosmos DB data continuously into OneLake in near real-time without affecting the performance of your transactional workloads. Click here for more information. This blog post shows you how to integrate these two technologies and build near real-time analytical applications.
Use Cases Between GraphQL and Azure Cosmos DB in Microsoft Fabric
Integrating the Microsoft Fabric API for GraphQL™ with mirrored Azure Cosmos DB data empowers developers to build robust real-time analytical applications. GraphQL enables efficient querying by allowing developers to retrieve only the required data from multiple sources, including mirrored data in OneLake, while abstracting backend complexities. This streamlined approach is perfect for applications demanding up-to-date insights, such as live dashboards, analytics platforms, and interactive user interfaces. By mirroring Azure Cosmos DB data into Microsoft Fabric, the system ensures near real-time synchronization, keeping data current without affecting transactional workload performance. This synergy lets developers concentrate on creating responsive, scalable applications that deliver actionable insights and seamless user experiences.
How to mirror your Azure Cosmos DB data into Microsoft Fabric
To mirror a database, it should already be provisioned in Azure, and continuous backup on the account is a prerequisite. Each database can be mirrored individually. And you can mirror the same database multiple times within the same workspace.
To start mirroring your Azure Cosmos DB database into Microsoft Fabric, navigate to the Fabric portal, open an existing workspace or create a new one, select Create, locate the Data Warehouse section, and then select Mirrored Azure Cosmos DB (preview). For more details, click here.
How to query your mirrored data with GraphQL
Your Azure Cosmos DB data is mirrored in the open-source delta format and automatically made available to all analytical engines on Fabric through a SQL Analytics Endpoint.
To connect your mirrored Azure Cosmos DB data to the Microsoft Fabric API for GraphQL™, you have two main options. The first is to use the SQL Analytics Endpoint provided by Microsoft Fabric for the mirrored database. This endpoint allows you to execute SQL queries against your mirrored data in OneLake. By integrating this endpoint with your GraphQL queries and mutations, you can directly interact with the mirrored data using familiar SQL syntax within your GraphQL APIs, enabling efficient data retrieval and manipulation.
The second option involves attaching the mirrored database to a Fabric Warehouse. By doing this, you integrate your Azure Cosmos DB data into the data warehousing environment of Microsoft Fabric. Your GraphQL queries and mutations can then interact with the warehouse data, providing a seamless way to access and analyze large volumes of data in near real-time.
Both methods enable you to efficiently connect and query your mirrored Cosmos DB data through GraphQL. This allows you to choose the approach that best fits your application’s architecture and performance requirements, facilitating the development of responsive and scalable applications.
For more information on how to query mirrored Cosmos DB data in Fabric, please visit Query the SQL analytics endpoint or Warehouse in Microsoft Fabric.
Nested Data
A common issue with mirrored data in Fabric is that JSON data gets replicated as strings. This is less than ideal, since applications expect properly formatted JSON for processing. To address this, you use views and expose the nested data as columns.
For this, we need to use the OPENJSON function and the CROSS APPLY operator in the view definition.
Here’s an example of a view that flattens mirrored JSON data into columns:
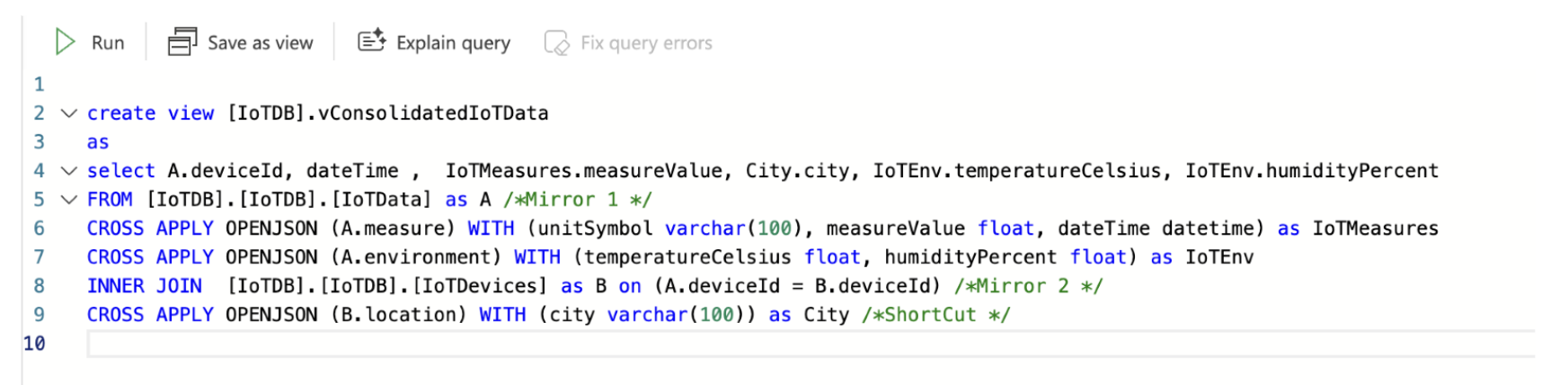
How this is used from within an application
Attaching the SQL Analytics endpoint or Warehouse to an API for GraphQL item, and choosing the vConsolidatedIoTData view in the object picker, we can very quickly craft a GraphQL request that returns the data that was formatted as columns by the view:

This request can now be used directly in your application, and GraphQL will return correctly formatted JSON back to the requesting client application.
API for GraphQL helps you create code for your application quickly and simply, with the Generate code functionality in the editor. Simply click on the Generate code button on your editor, and pick from a list of languages to use in your app.
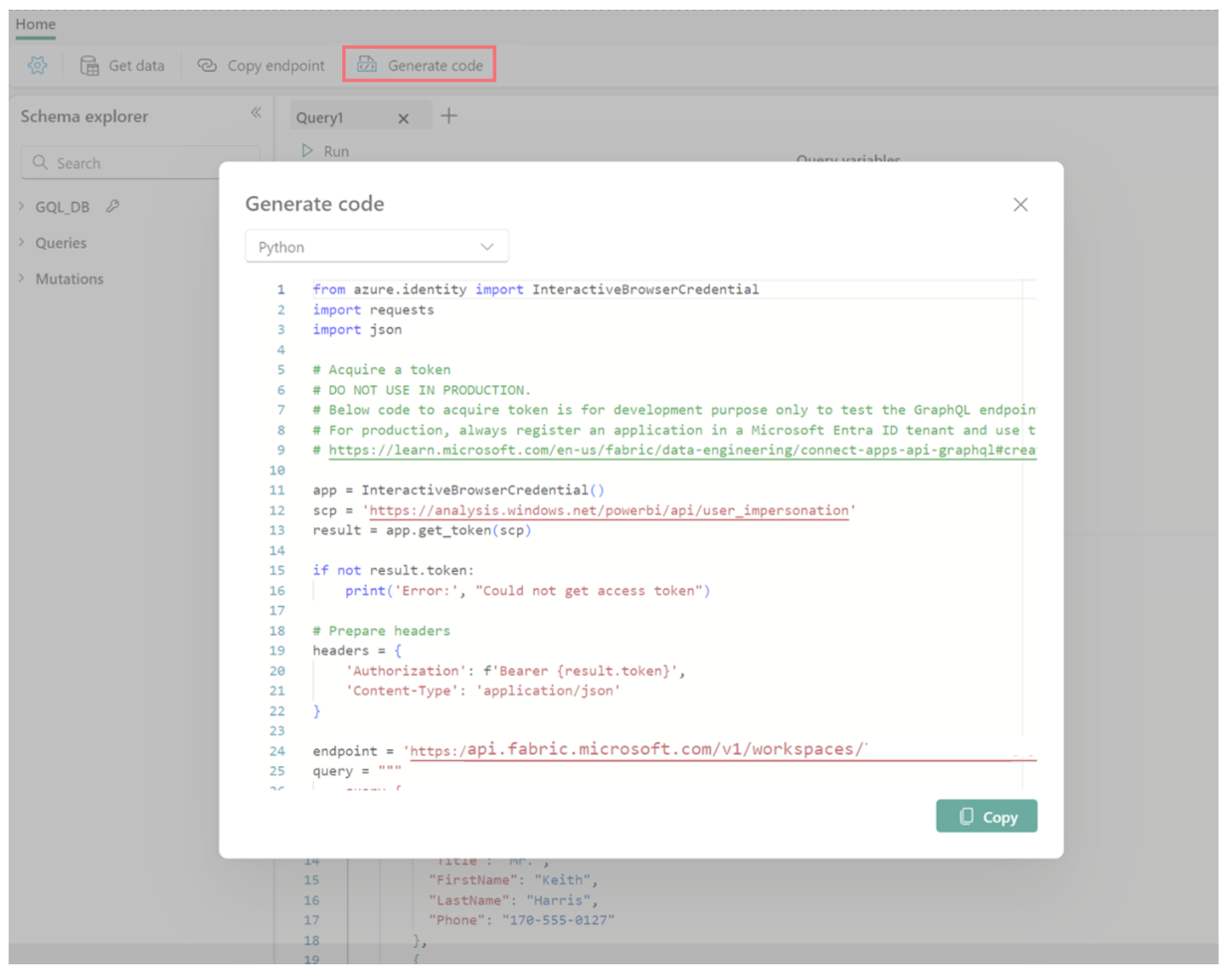
For more information on how to leverage Fabric API for GraphQL in your applications, please visit Connect applications to Fabric API for GraphQL.
Conclusion
In conclusion, integrating Microsoft Fabric API for GraphQL™ with mirrored Azure Cosmos DB data offers a robust solution for building near real-time analytical applications. By harnessing GraphQL’s efficient querying capabilities and the seamless data integration provided by Microsoft Fabric, developers can create responsive and scalable applications with ease. Whether you choose to connect through the SQL Analytics Endpoint or attach the mirrored database to a Fabric Warehouse, this approach enables efficient access to up-to-date data, empowering you to deliver rich insights and exceptional user experiences.
More Resources
Here are some more resources that you may find interesting:
API for GraphQL Overview and Documentation
Mirroring Azure Cosmos DB (Preview)
Leave a review
Tell us about your Azure Cosmos DB experience! Leave a review on PeerSpot and we’ll gift you $50. Get started here.
About Azure Cosmos DB
Azure Cosmos DB is a fully managed and serverless NoSQL and vector database for modern app development, including AI applications. With its SLA-backed speed and availability as well as instant dynamic scalability, it is ideal for real-time NoSQL and MongoDB applications that require high performance and distributed computing over massive volumes of NoSQL and vector data.
Try Azure Cosmos DB for free here. To stay in the loop on Azure Cosmos DB updates, follow us on X, YouTube, and LinkedIn.
0 comments