
Azure Cosmos DB Cassandra API is a fully managed cloud service that is compatible with Cassandra Query Language (CQL) v3.11 API. It has no operational overhead and you can benefit from all the underlying Azure Cosmos DB capabilities such as global distribution, automatic scale out partitioning, availability and latency guarantees, encryption at rest, backups etc.
At the time of writing this blog, the Azure Cosmos DB Cassandra API serverless is available in preview mode!
Your existing Cassandra applications can work with the Azure Cosmos DB Cassandra API since it works with CQLv4 compliant drivers (see examples for Java, .Net Core, Node.js, Python etc.) But, you also need to think about integrating with other systems with existing data and bringing that into Azure Cosmos DB. One such system is Apache Kafka, which is a distributed streaming platform. It is used in industries and organizations to solve a wide variety of problems ranging from traditional asynchronous messaging, website activity tracking, log aggregation, real-time fraud detection and much more! It has a rich ecosystem of technologies such as Kafka Streams for stream processing and Kafka Connect for real-time data integration.
Thanks to its scalable design, Apache Kafka often serves as a central component in the overall data architecture with other systems pumping data into it. These could be click stream events, logs, sensor data, orders, database change-events etc. You name it! So, as you can imagine, there is a lot of data in Apache Kafka (topics) but it’s only useful when consumed or ingested into other systems. You could achieve this by writing good old plumbing code using the Kafka Producer/Consumer APIs using a language and client SDK of your choice. But you can do better!
This blog post demonstrates how you can use an open source solution (connector based) to ingest data from Kafka into Azure Cosmos DB Cassandra API. It uses a simple yet practical scenario along with a re-usable setup using Docker Compose to help with iterative development and testing. You will learn about:
- Overview of Kafka Connect along with the details of the integration
- How to configure and use the connector to work with Azure Cosmos DB
- Use the connector to write data to multiple tables from a single Kafka topic
By the end of this blog, you should have a working end to end integration and be able to validate it.
Hello, Kafka Connect!
Kafka Connect is a platform to stream data between Apache Kafka and other systems in a scalable and reliable manner. Besides the fact that it only depends on Kafka, the great thing about it is the fact that it provides a suite of ready-to-use connectors. This means that you do not need to write custom integration code to glue systems together; no code, just configuration! In case an existing connector is not available, you can leverage the powerful Kafka Connect framework to build your own connectors.
There are two broad categories of connectors offered by Kafka Connect:
- Source connector: It is used to to extract data “from” an external system and send it to Apache Kafka.
- Sink connector: It is used to send existing data in Apache Kafka “to” an external system.
In this blog post, we will be using the open source DataStax Apache Kafka connector which is a Sink connector that works on top of Kafka Connect framework to ingest records from a Kafka topic into rows of one or more Cassandra table(s).
Solution architecture
At a high level, the solution is quite simple! But a diagram should be helpful nonetheless.
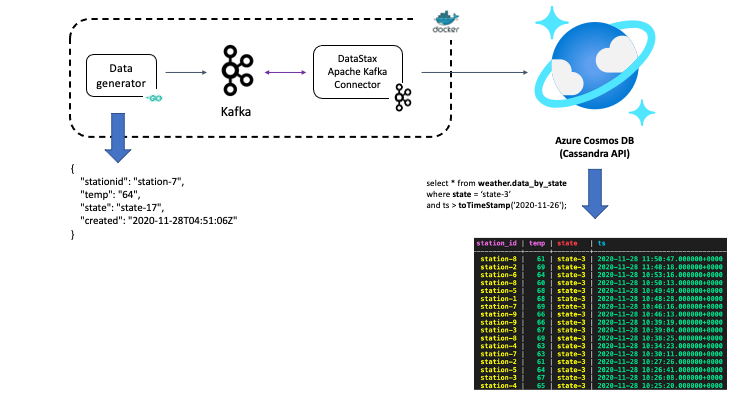
Sample weather data continuously generated into a Kafka topic. This is picked up by the connector and sent to Azure Cosmos DB and can be queried using any Cassandra client driver.
Except Azure Cosmos DB, the rest of the components of the solution run as Docker containers (using Docker Compose). This includes Kafka (and Zookeeper), Kafka Connect worker (the Cassandra connector) along with the sample data generator (Go) application. Having said that, the instructions would work with any Kafka cluster and Kafka Connect workers, provided all the components are configured to access and communicate with each other as required. For example, you could have a Kafka cluster on Azure HD Insight or Confluent Cloud on Azure Marketplace.
Docker Compose services
Here is a breakdown of the components and their service definitions – you can refer to the complete docker-compose file in the GitHub repo.
The debezium images are used to run Kafka and Zookeeper. They just work and are great for iterative development with quick feedback loop, demos etc.
zookeeper: image: debezium/zookeeper:1.2 ports: - 2181:2181 kafka: image: debezium/kafka:1.2 ports: - 9092:9092 links: - zookeeper depends_on: - zookeeper environment: - ZOOKEEPER_CONNECT=zookeeper:2181 - KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092
To run as a Docker container, the DataStax Apache Kafka Connector is baked on top of an existing Docker image – debezium/connect-base. This image includes an installation of Kafka and its Kafka Connect libraries, thus making it really convenient to add custom connectors.
cassandra-connector:
build:
context: ./connector
ports:
- 8083:8083
links:
- kafka
depends_on:
- kafka
environment:
- BOOTSTRAP_SERVERS=kafka:9092
- GROUP_ID=cass
- CONFIG_STORAGE_TOPIC=cass_connect_configs
- OFFSET_STORAGE_TOPIC=cass_connect_offsets
- STATUS_STORAGE_TOPIC=cass_connect_statuses
The Dockerfile is quite compact. It downloads the connectors and unzips it to appropriate directory in the filesystem (plugin path) for the Kafka Connect framework to detect it.
FROM debezium/connect-base:1.2 WORKDIR $KAFKA_HOME/connect RUN curl -L -O https://downloads.datastax.com/kafka/kafka-connect-cassandra-sink.tar.gz RUN tar zxf kafka-connect-cassandra-sink.tar.gz RUN rm kafka-connect-cassandra-sink.tar.gz
Finally, the data-generator service seeds randomly generated (JSON) data into the weather-data Kafka topic. You can refer to the code and Dockerfile in the GitHub repo
data-generator:
build:
context: ./data-generator
ports:
- 8080:8080
links:
- kafka
depends_on:
- kafka
environment:
- KAFKA_BROKER=kafka:9092
- KAFKA_TOPIC=weather-data
Let’s move on to the practical aspects! Make sure you have the following ready before you proceed.
Pre-requisites
- You will need a Microsoft Azure account. Don’t worry, you can get it for free if you don’t have one already!
- Install Docker and Docker Compose
Finally, clone this GitHub repo:
git clone https://github.com/abhirockzz/kafka-cosmosdb-cassandra cd kafka-cosmos-cassandra
The next sections will guide you through:
- Set up an Azure Cosmos DB account, Cassandra keyspace and tables
- Bootstrap the integration pipeline
- Understand the configuration and start a connector instance
- Test the end to end result and run queries on data in Azure Cosmos DB tables
Setup and configure Azure Cosmos DB
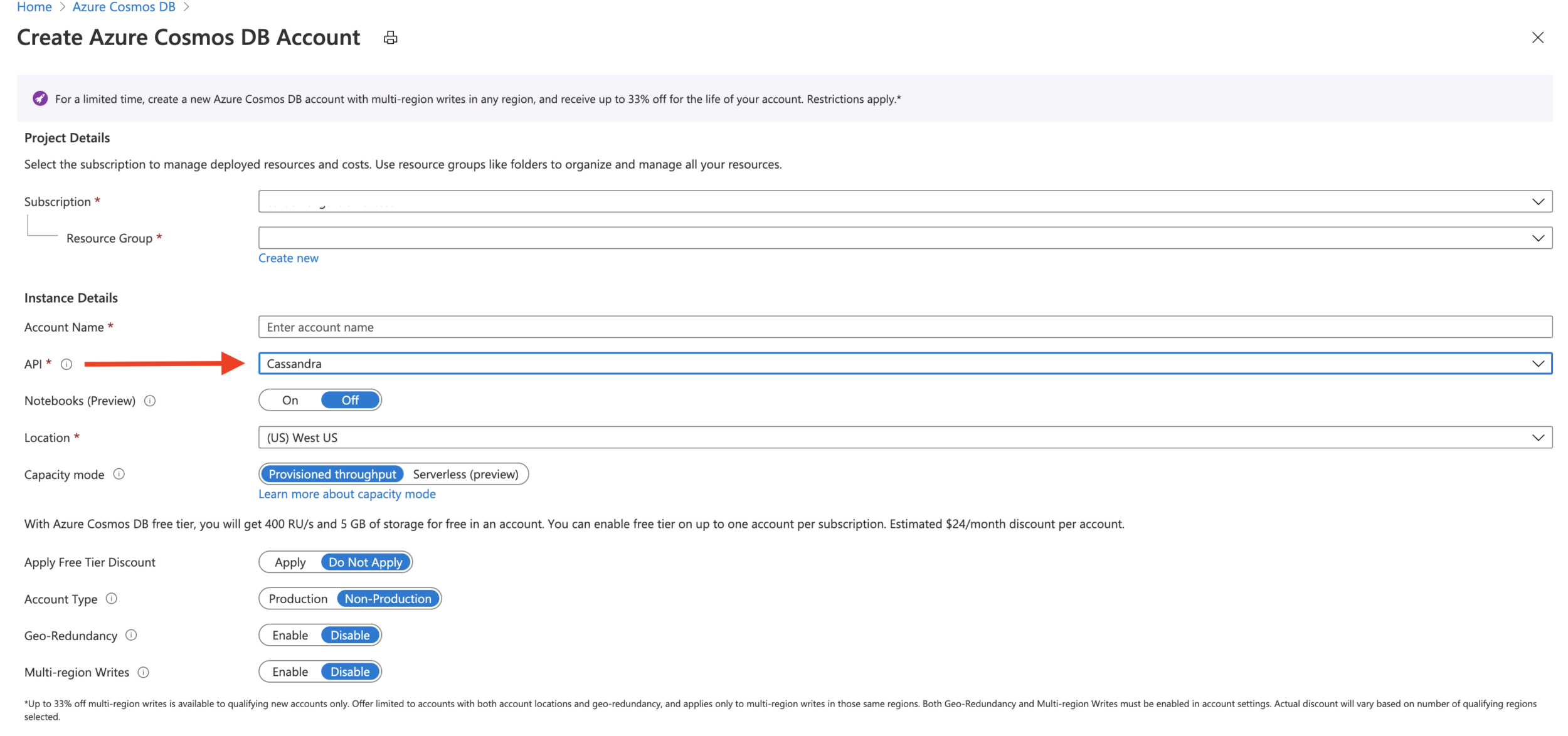
Start by creating an Azure Cosmos DB account with the Cassandra API option selected
Using the Azure portal, create the Cassandra Keyspace and the tables required for the demo application.
CREATE KEYSPACE weather WITH REPLICATION = {'class' : 'NetworkTopologyStrategy', 'datacenter1' : 1};
CREATE TABLE weather.data_by_state (station_id text, temp int, state text, ts timestamp, PRIMARY KEY (state, ts)) WITH CLUSTERING ORDER BY (ts DESC) AND cosmosdb_cell_level_timestamp=true AND cosmosdb_cell_level_timestamp_tombstones=true AND cosmosdb_cell_level_timetolive=true;
CREATE TABLE weather.data_by_station (station_id text, temp int, state text, ts timestamp, PRIMARY KEY (station_id, ts)) WITH CLUSTERING ORDER BY (ts DESC) AND cosmosdb_cell_level_timestamp=true AND cosmosdb_cell_level_timestamp_tombstones=true AND cosmosdb_cell_level_timetolive=true;
That’s it for the database part! It’s time to start up other components.
Start integration pipeline
Since everything is Docker-ized, all you need is a single command to bootstrap services locally – Kafka, Zookeeper, Kafka Connect worker and the sample data generator application.
docker-compose --project-name kafka-cosmos-cassandra up --build
To confirm whether all the containers have started:
docker-compose -p kafka-cosmos-cassandra ps
#output
Name Command State Ports
--------------------------------------------------------------------------------------------------------------------------
kafka-cosmos-cassandra_cassandra- /docker-entrypoint.sh start Up 0.0.0.0:8083->8083/tcp, 8778/tcp,
connector_1 9092/tcp, 9779/tcp
kafka-cosmos-cassandra_datagen_1 /app/orders-gen Up 0.0.0.0:8080->8080/tcp
kafka-cosmos-cassandra_kafka_1 /docker-entrypoint.sh start Up 8778/tcp, 0.0.0.0:9092->9092/tcp,
9779/tcp
kafka-cosmos-cassandra_zookeeper_1 /docker-entrypoint.sh start Up 0.0.0.0:2181->2181/tcp, 2888/tcp,
3888/tcp, 8778/tcp, 9779/tcp
The data generator application will start pumping data into the weather-data topic in Kafka. You can also do quick sanity check to confirm. Peek into the Docker container running the Kafka connect worker:
docker exec -it kafka-cosmos-cassandra_cassandra-connector_1 bash
Once you drop into the container shell, just start the usual Kafka console consumer process and you should see weather data (in JSON format) flowing in.
cd ../bin
./kafka-console-consumer.sh --bootstrap-server kafka:9092 --topic weather-data
#output
{"stationid":"station-7","temp":"64","state":"state-17","created":"2020-11-28T04:51:06Z"}
{"stationid":"station-9","temp":"65","state":"state-1","created":"2020-11-28T04:51:09Z"}
{"stationid":"station-3","temp":"60","state":"state-9","created":"2020-11-28T04:51:12Z"}
{"stationid":"station-8","temp":"60","state":"state-3","created":"2020-11-28T04:51:15Z"}
{"stationid":"station-5","temp":"65","state":"state-7","created":"2020-11-28T04:51:18Z"}
{"stationid":"station-6","temp":"60","state":"state-4","created":"2020-11-28T04:51:21Z"}
....
Cassandra Sink connector setup
Copy the JSON contents below to a file (you can name it cassandra-sink-config.json). You will need to update it as per your setup and the rest of this section will provide guidance around this topic.
{
"name": "kafka-cosmosdb-sink",
"config": {
"connector.class": "com.datastax.oss.kafka.sink.CassandraSinkConnector",
"tasks.max": "1",
"topics": "weather-data",
"contactPoints": "<cosmos db account name>.cassandra.cosmos.azure.com",
"port": 10350,
"loadBalancing.localDc": "<cosmos db region e.g. Southeast Asia>",
"auth.username": "<enter username for cosmosdb account>",
"auth.password": "<enter password for cosmosdb account>",
"ssl.hostnameValidation": true,
"ssl.provider": "JDK",
"ssl.keystore.path": "/etc/alternatives/jre/lib/security/cacerts/",
"ssl.keystore.password": "changeit",
"datastax-java-driver.advanced.connection.init-query-timeout": 5000,
"maxConcurrentRequests": 500,
"maxNumberOfRecordsInBatch": 32,
"queryExecutionTimeout": 30,
"connectionPoolLocalSize": 4,
"topic.weather-data.weather.data_by_state.mapping": "station_id=value.stationid, temp=value.temp, state=value.state, ts=value.created",
"topic.weather-data.weather.data_by_station.mapping": "station_id=value.stationid, temp=value.temp, state=value.state, ts=value.created",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": false,
"offset.flush.interval.ms": 10000
}
}
Here is a summary of the attributes:
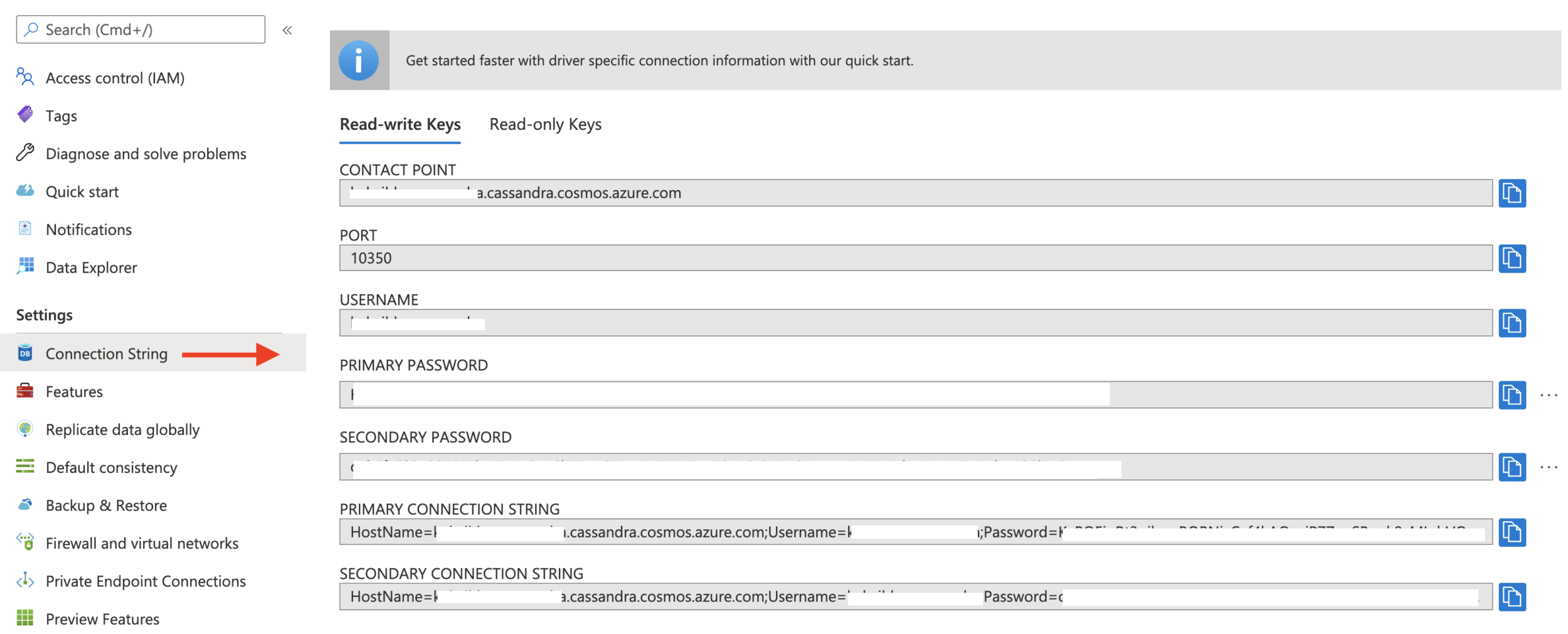
Basic connectivity
- contactPoints: enter the contact point for Cosmos DB Cassandra
- localDc: enter the region for Cosmos DB account e.g. Southeast Asia
- username: enter the username
- password: enter the password
- port: enter the port value (this is
10350, not 9042. leave it as is)
You can access this info the Azure Portal:
SSL configuration
Azure Cosmos DB enforces secure connectivity over SSL and Kafka Connect connector supports SSL as well.
- keystore.path: path to the JDK keystore (inside the container it is /etc/alternatives/jre/lib/security/cacerts/)
- keystore.password: JDK keystore (default) password
- hostnameValidation: We turn on node hostname validation
- provider: JDK is used as the SSL provider
Kafka to Cassandra mapping
To push data from Kafka topics to Cassandra, the connector must be configured by providing mapping between records in Kafka topics and the columns in the Cassandra table(s). One of the nice capabilities of the connector is that it allows you to write to multiple Cassandra tables using data from a single Kafka topic. This is really helpful in scenarios where you need derived representations (tables) of events in your Kafka topic(s).
Take a look at the following mapping attributes:
- “topic.weather-data.weather.data_by_state.mapping”: “station_id=value.stationid, temp=value.temp, state=value.state, ts=value.created”
- “topic.weather-data.weather.data_by_station.mapping”: “station_id=value.stationid, temp=value.temp, state=value.state, ts=value.created”
Let’s break it down:
- The key (e.g.
weather-data.weather.data_by_state.mapping) is nothing but a combination of the Kafka topic name and the Cassandra table (including the keyspace). Note that define mappings for two tables (data_by_stateanddata_by_station) using separate config parameters. - The value is comma-separated entries of the Cassandra column name and the corresponding JSON attribute of the event in the Kafka topic e.g.
station_id=value.stationidrefers tostation_idwhich is a column in the data_by_station table andvalue.stationidrefers tostationidwhich is an attribute in the JSON payload which looks like this:
{
"stationid": "station-7",
"temp": "64",
"state": "state-17",
"created": "2020-11-28T04:51:06Z"
}
Generic parameters
- converter: We use the string converter
org.apache.kafka.connect.storage.StringConverter - converter: since the data in Kafka topics is JSON, we make use of
org.apache.kafka.connect.json.JsonConverter - converter.schemas.enable: This is important – our JSON payload does not have a schema associated with it (for the purposes of the demo app). We need to instruct Kafka Connect to not look for a schema by setting this to false. Not doing so will result in failures.
Passing Java driver level configs
datastax-java-driver.advanced.connection.init-query-timeout: 5000
Although the connector provides sane defaults, you can pass in the Java driver properties as connector configuration parameters. The Java driver uses 500 ms as the default value for the init-query-timeout parameter (which is quite low in my opinion), given the fact that it is used as “timeout to use for internal queries that run as part of the initialization process” (read more here)
I did face some issues due to this and was glad to see that it was tunable! Setting it to 5000 ms worked for me but it can probably be set slightly lower and it would still work just fine e.g. 2000 ms
For more details around the configuration, please refer to the documentation
Install the connector using the Kafka Connect REST endpoint:
curl -X POST -H "Content-Type: application/json" --data @cassandra-sink-config.json http://localhost:8083/connectors # check status curl http://localhost:8080/connectors/kafka-cosmosdb-sink/status
If all goes well, the connector should start weaving its magic. It should authenticate to Azure Cosmos DB and start ingesting data from the Kafka topic (weather-data) into Cassandra tables – weather.data_by_state and weather.data_by_station
You can now query data in the tables. Head over to the Azure portal, bring up the Hosted CQL Shell for your Azure Cosmos DB account.
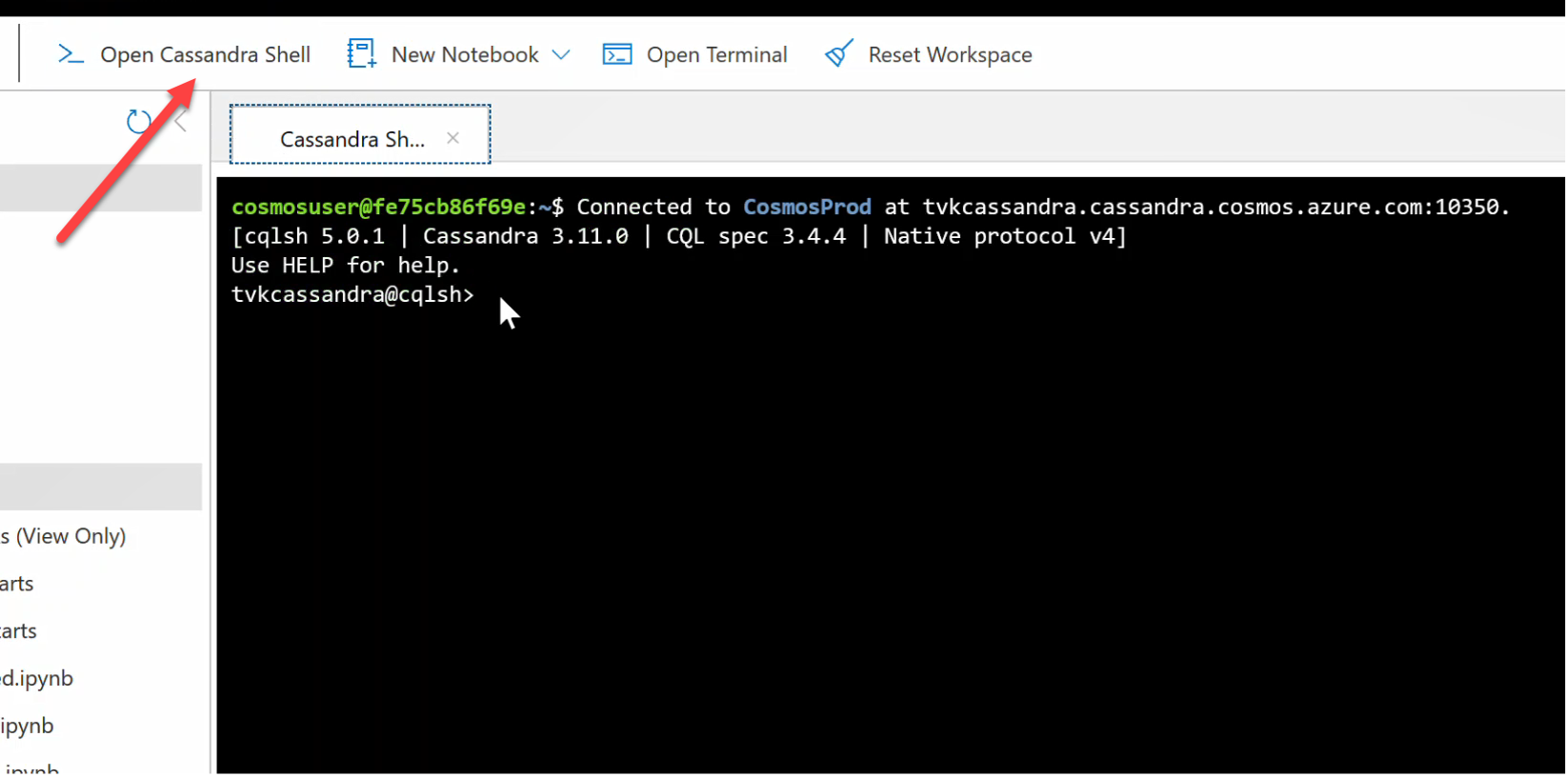
Query Azure Cosmos DB
Check the data_by_state and data_by_station tables. Here are some sample queries to get you started:
select * from weather.data_by_state where state = 'state-1';
select * from weather.data_by_state where state IN ('state-1', 'state-2');
select * from weather.data_by_state where state = 'state-3' and ts > toTimeStamp('2020-11-26');
select * from weather.data_by_station where station_id = 'station-1';
select * from weather.data_by_station where station_id IN ('station-1', 'station-2');
select * from weather.data_by_station where station_id IN ('station-2', 'station-3') and ts > toTimeStamp('2020-11-26');
[Important: delete resources]
To stop the containers, you can:
docker-compose -p kafka-cosmos-cassandra down -v
You can either delete the keyspace/table or the Azure Cosmos DB account.
Wrap up
To summarise, you learnt how to use Kafka Connect for real-time data integration between Apache Kafka and Azure Cosmos DB. Since the sample adopts a Docker container based approach, you can easily customise this as per your own unique requirements, rinse and repeat!
The use case and data-flow demonstrated in this article was relatively simple, but the rich Kafka Connect ecosystem of connectors allows you to integrate disparate systems and stitch together complex data pipelines without having to write custom integration code. For example, to migrate/integrate with another RDBMS (via Kafka), you could potentially use the Kafka Connect JDBC Source connector to pull database records into Kafka, transform or enrich them in a streaming fashion using Kafka Streams, re-write them back to a Kafka topic and then bring that data into Azure Cosmos DB using the approach outlined in this article. The are lots of possibilities and the solution will depend on the use case and requirements.
You would obviously need to setup, configure and operate these connectors. At the very core, Kafka Connect cluster instances are just JVM processes and inherently stateless (all the state handling is offloaded to Kafka). Hence, you’ve a lot of flexibility in terms of your overall architecture as well as orchestration: for example, running them in Kubernetes for fault-tolerance and scalability!
Additional resources
If you want to explore further, I would recommend referring to the resources below:
0 comments