

This article is guest authored by Youssef Moussaoui, member of the technical staff, Microsoft Copilot.
As part of the team developing Microsoft Copilot, we’re constantly looking for ways to improve the application and keep our millions of users engaged. With this in mind, we recently evaluated the structure of our backend and began looking for a database that would set the foundation for Copilot’s future.
Copilot today processes billions of messages from millions of active users, so we needed a database solution that not only delivered a fast, engaging experience, but also provided worldwide coverage to support our global user base. In addition, the solution needed to minimize operational complexity for our team. After considering all our options, we came to the conclusion that Azure Cosmos DB was the clear choice, and it allowed us to standardize around Azure technology.
Now that we’re running on Azure Cosmos DB, I’d like to share what made the transition smooth for us. In this post, I’ll explain our favorite features, our partitioning strategy, and our indexing policy:
- Favorite features: The Azure Cosmos DB features that have helped our team create the best possible Copilot experience
- Partitioning strategy: How we approached partitioning and why we organized our schema by user ID
- Indexing policy: How we reduced latency by turning off automatic indexing
I recommend you keep these things in mind when building your own AI application powered by Azure Cosmos DB.
Finding the intersection of speed, scale, and low operational burden
At a high level, Copilot uses Azure Cosmos DB to store users’ queries, as well as their entire conversation history, so that Copilot can understand the context surrounding each message. The application works like this: the user inputs a message, Azure Cosmos DB stores it, then Copilot fetches that user’s conversation history. Using that information, Copilot constructs an AI prompt that goes through a large language model. Then the model streams back a response to the initial query. When it’s done streaming, Copilot asynchronously persists that response in Azure Cosmos DB.
It takes Azure Cosmos DB only 3.3 milliseconds, on average, to execute each of these database operations. That speed is possible because Azure Cosmos DB uses on-cluster SSD storage, versus remote storage that must go over a network. Being able to deliver a fast user experience across the board was key for us. And while there are many database solutions available that deliver fast performance, Azure Cosmos DB stood out because it offers that speed at enormous scale without the operational burden. We could potentially reach the same level of performance if we opted for a manually sharded database, but that would involve monitoring the capacity, the load, and the memory usage of our nodes as our traffic scales up. We’d also have to occasionally re-partition our data over time to maintain balanced traffic across each of our shards.
 With Azure Cosmos DB, all of that is handled for us. It’s globally distributed and it automatically scales our request units (RU) when and where we need them. We don’t have to put much effort into setting up databases in multiple regions because Azure Cosmos DB does it with a mouse-click, handling the replication for us. Management involves setting RU minimums and maximums for containers. If we were managing our own database system, we’d likely need a full-time database administrator. Azure Cosmos DB has saved time while also improving the reliability of our system.
With Azure Cosmos DB, all of that is handled for us. It’s globally distributed and it automatically scales our request units (RU) when and where we need them. We don’t have to put much effort into setting up databases in multiple regions because Azure Cosmos DB does it with a mouse-click, handling the replication for us. Management involves setting RU minimums and maximums for containers. If we were managing our own database system, we’d likely need a full-time database administrator. Azure Cosmos DB has saved time while also improving the reliability of our system.
Partitioning by user ID keeps Copilot organized
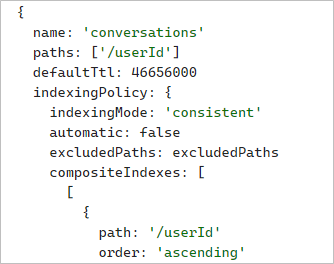 While Azure Cosmos DB is one factor that supports a fast user experience, our schema strategy also contributes to that speed. Almost every container we have is partitioned by user ID. On our main container for storing messages, we’ve created a composite index based on user ID, conversation ID, and timestamp in descending order for efficient querying. Copilot queries for the most recent messages in a user’s conversation, so this composite index must properly support that pattern.
While Azure Cosmos DB is one factor that supports a fast user experience, our schema strategy also contributes to that speed. Almost every container we have is partitioned by user ID. On our main container for storing messages, we’ve created a composite index based on user ID, conversation ID, and timestamp in descending order for efficient querying. Copilot queries for the most recent messages in a user’s conversation, so this composite index must properly support that pattern.
Authentication is the one exception for partitioning by user ID. When a user authenticates, Copilot must look up the user ID, which is partitioned by the value of the authentication token. For example, if it’s an anonymous login, Copilot uses the information in a persistent session cookie as the partition key.
Ultimately, Copilot can have a schema based on user ID because it doesn’t currently need to access data across users. In the future, if we create a collaboration feature, we’d likely create a separate collaborations container that could be shared with a collaboration ID.
Reducing latency with a custom indexing policy
Copilot is a write-heavy application where every message ends up in Azure Cosmos DB. To optimize write-performance for additional performance gains, we created a custom indexing policy. This custom policy excludes the properties and paths we didn’t use in our queries from being indexed. By default, Azure Cosmos DB automatically indexes all property paths in a JSON document. However, with our custom policy, we’re indexing exactly what we need for our query patterns while keeping write latency low.
Overall, Azure Cosmos DB has helped Copilot deliver a next-level experience to users. As we continue to grow and scale, we’re excited to keep delivering amazing new AI features to our users.
***
About the author

Leave a review
Tell us about your Azure Cosmos DB experience! Leave a review on PeerSpot and we’ll gift you $50. Get started here.
About Azure Cosmos DB
Azure Cosmos DB is a fully managed and serverless NoSQL and vector database for modern app development, including AI applications. With its SLA-backed speed and availability, as well as instant dynamic scalability, it is ideal for real-time NoSQL and MongoDB applications that require high performance and distributed computing over massive volumes of NoSQL and vector data.
Try Azure Cosmos DB for free here. For Azure Cosmos DB updates, follow us on X, YouTube, and LinkedIn.
0 comments