

Introduction
Azure Cosmos DB is Microsoft’s premier fully managed NoSQL database for modern app development. It is ideal for solutions including artificial intelligence, digital commerce, Internet of Things, booking management and other types of use cases. It offers single-digit millisecond response times, automatic and instant scalability along with guaranteed speed at any scale. Azure Cosmos DB’s NoSQL offering stands out with its exceptional performance and robust feature set that can be an alternative to using graph databases.
This blog post outlines the approach and best practices, we, the authors learned while working with a customer who wanted to transition a graph workload to Azure Cosmos DB for NoSQL. Our insights are based on our collaboration with various teams, including software engineering and Line-Of-Business (LOB) application teams, at Walmart.
When should I do this?
Azure Cosmos DB for NoSQL is recommended for building green-field applications. However, if users are committed to refactoring their code, it can also be used in scenarios where users are attempting to squeeze the most performance for their applications. The scenario highlighted here is an application currently using a graph as the back-end database for storing, querying and analyzing data relationships. In this blog post we will illustrate using the Gremlin graph database and provide guidance to re-model the same into Azure Cosmos DB for NoSQL.
The three important qualifying factors wherein this approach is valid include:
- Your use-case leverages point-reads most of the time (> 80%) for querying data.
- Your use-case leverages 1-x traversals most of the time (> 80%) for querying data.
- Your use-case leverages a combination of point-reads and 1-x traversals most of the time (>80%) for querying data.
This approach is not recommended if you are mostly doing a 2x- and 3x- or more level of traversals with complex edge-relationships and/or data size of database is > 5 TBs.
Approach
Ideally, the recommended approach is to simulate the Gremlin API data model and vertex (aka node) to vertex traversals via edges using Azure Cosmos DB for NoSQL. The table below documents the source and destination:
| Currently in Azure Cosmos DB for Gremlin | Proposed in Azure Cosmos DB for NoSQL |
| Vertex (Node) | Item |
| Edge (Relationship) | Item |
| A forward edge (i.e., a forward traversal). E.g., A –> B | Item |
| A reverse edge (i.e., a backward traversal). E.g., B –> A | Item |
In essence the approach is to create 4 items.
Re-modeling – an example
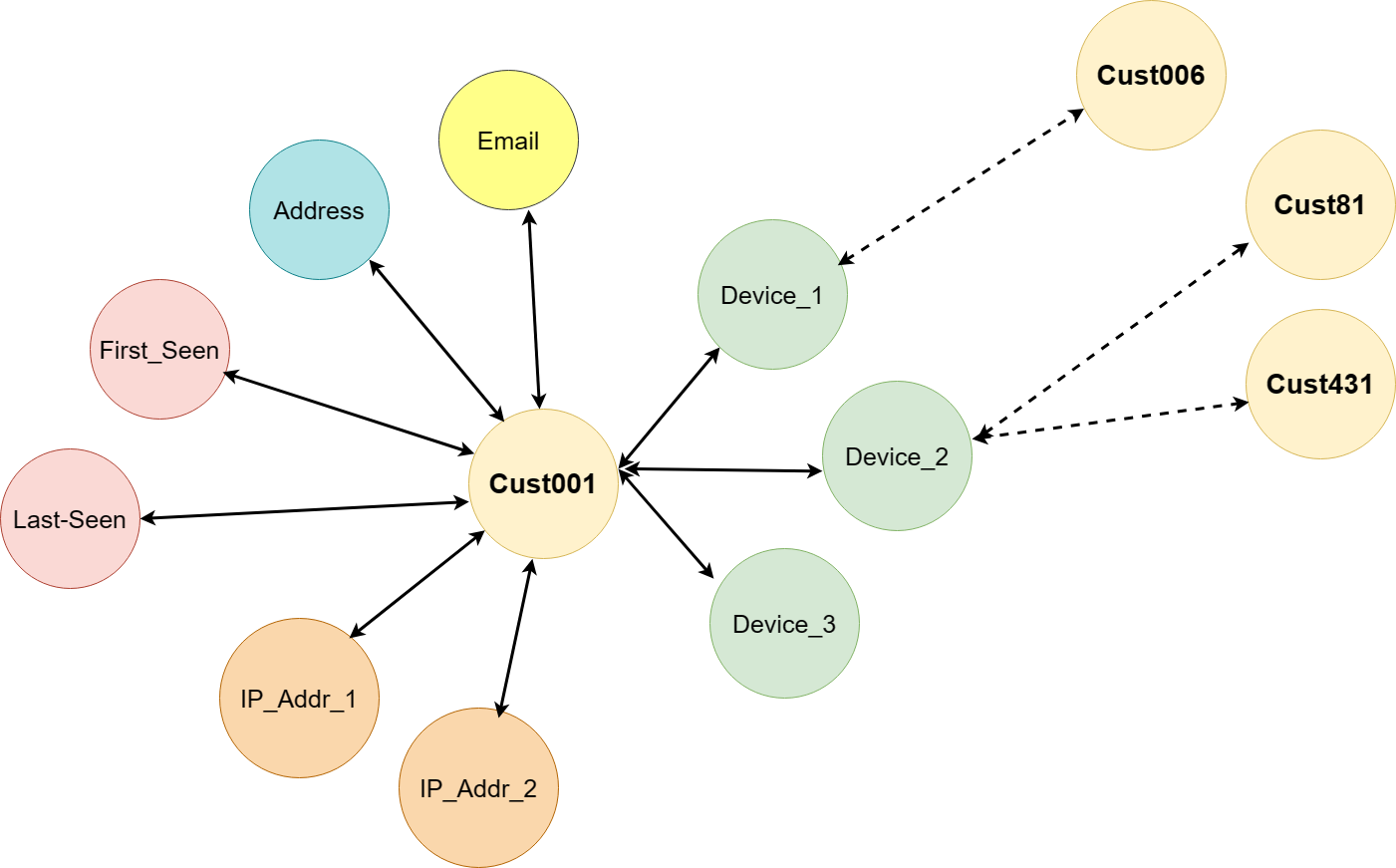
A graph is just a collection of vertices and edges – or, in other words, a set of nodes and the relationships that connect them. Graphs represent entities as nodes and the ways in which those entities relate to the world as relationships. This general-purpose, expressive structure allows us to model all kinds of scenarios. In the example below, for a retail online sales scenario, we are building a graphical representation of a customer data point. Our vertex has id: Cust001, label: customer and properties including email address, address, first seen, last seen, device1, device2 and so on. Device identified by id Device_1 is in turn shared by customer identified by id: Cust006, and device identified by id Device_2 is shared by two other customers, identified by id: Cust81 and Cust431.
This Gremlin API data model vertex could be represented in an Azure Cosmos DB for NoSQL data model in the following JSON representation:
{
"doc_type": "node",
"id": "<<generate guid>>", // generate a GUID
"type": "[Type]",
"key": "[Key]",
"pk": "[Type + Key]", // generate a partition key
"first_seen": "[first_seen]",
"last_seen": "[last_seen]",
"details": {
"a1": "v1",
"a2": "v2",
".com": {
"x": {
"p": "abc",
"g": "def"
},
"com_fs": "",
"com_ls": "",
"mp_fs": "",
"mp_ls": "",
"last_"
},
}
The edge (forward direction) traversal item could be represented as:
{
"doc_type": "edge",
"id": "<<generate guid>>", // [Edge.Node1.key].[Edge.Node2.key].[Edge.Type]
"type": "[Type], // alternatively, "[Edge.Node1.key]"
"key": "[Key]",
"pk": "[Type + Key]",
"first_seen": "[first_seen]",
"last_seen": "[last_seen]",
"details": {
"a1": "v1",
"a2": "v2",
".com": {
"x": {
"p": "abc",
"g": "def"
},
"com_fs": "",
"com_ls": "",
"mp_fs": "",
"mp_ls": ""
"last_"
},
}
A practical example
Gremlin API data mode and queries
Click here for Image Reference
{kind=link}
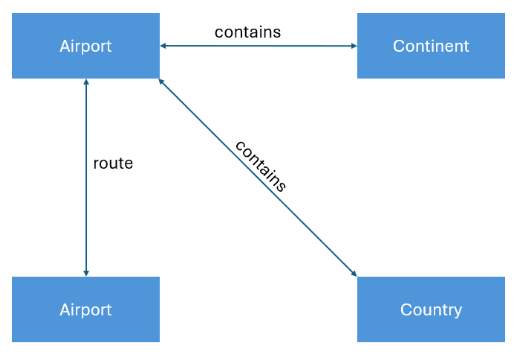
The GitHub sample contains 4 vertex types. The vertices airport, country, and continent are important. The version vertex exists for the purpose of tracking the version of the graph. The following shows the number of vertices for each type.
![]()
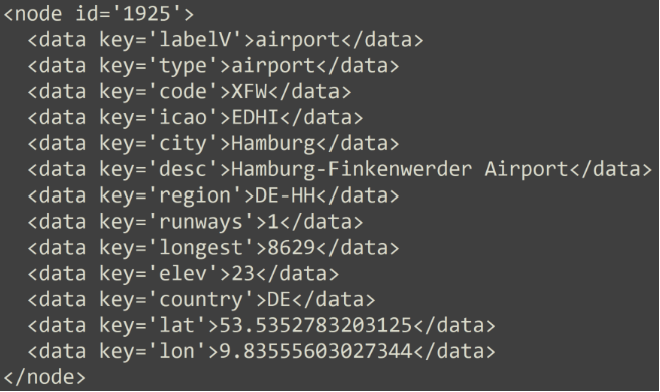
Airport vertex has a few properties associated with it which provide airport related information like number of runways, elevation, geographical location, etc.
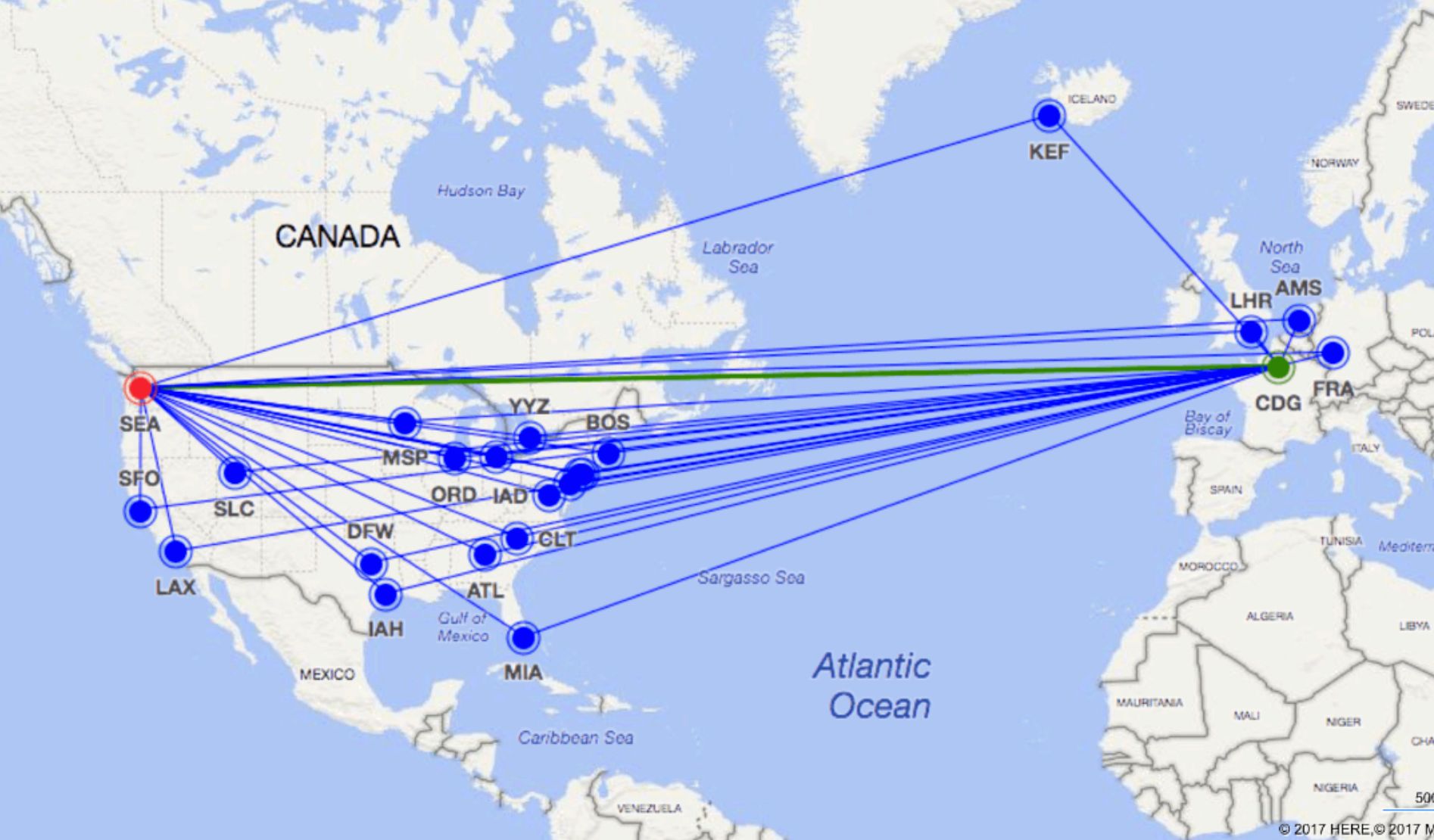
Routes are edges that connect the countries and the airports. They have a distance property to calculate the distance between the two connected airport vertices. The following shows the number of edges for each type.
![]()
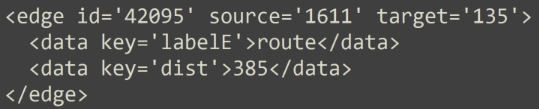
The following shows a sample edge connection between two airports with properties label and distance between the airports.
The image below represents the sample model with all the vertices and edges.
Let us execute a few queries on the model and then simulate the same in NoSQL.
Single Traversal
// List all the airports for the country India g.V().has("country","desc","India").out("contains").values("city")
The output is as exhibited below:
 Approximate Request Unit (RU) consumption = 25 RU/s
Approximate Request Unit (RU) consumption = 25 RU/s
Double Traversal
// Bangalore to San Francisco with 1 hop/layover g.V().has("code","BOM").out().out().has("code","SFO").path().by("code")
The output is as exhibited below:
 Approximate RU consumption = 770 RU/s
Approximate RU consumption = 770 RU/s
// Find the top ten overall in terms of incoming routes g.V().hasLabel('airport').order().by(__.in('route').count(),decr).limit(10).project('ap','routes').by('code').by(__.in('route').count())
![]() Approximate RU consumption = 11,900 RU/s
Approximate RU consumption = 11,900 RU/s
Azure Cosmos DB for NoSQL model and queries
Understanding query access patterns is critical before designing a data model for your use-case in Azure Cosmos DB for NoSQL. Based on your application specific query patterns, it is advisable to create a schema and choose the partition key for your container. This results in a highly optimized and cost-efficient data model in Azure Cosmos DB for NoSQL.
In this case, the schema of the model will include forward and reverse traversal for the vertices and edges. Additionally, the query access pattern will help us in defining the partition key and additional attributes.
A basic Gremlin API data model when translated into a NoSQL data model looks similar to:

How do we map vertex and edge to NoSQL documents effectively?
- The partition key is determined based on the query to be performed and different vertices and edge combinations.
- For an edge, a generic example for a combination of “vertex-type”+”vertex-key”+”edge-type” would help perform traversal from one vertex to another using the edge relationship. You can actually traverse to any depth with this combination.
- For a vertex, a generic example for a combination of “vertex-type”+”vertex-key” is good enough to grab the relevant information.
Note: The partition key combination will vary depending on your use case.
Let us take the air-routes graph data and model it into the Azure Cosmos DB for NoSQL model that would help us execute similar queries.
 (Click to enlarge image)
(Click to enlarge image)
Single Traversal
// List all the airports for the country India select c.destination, c.destinationType from c where c.partitionKey='country_India_contains' and c.doc_type='edge'
Approximate RU: 3-5 RU/s
This query would return all the vertices i.e. the forward linkages from country to airport. Once the vertices are available then the node related details can easily be extracted using the point-read operation.
Double Traversal
// List all the flights between Mumbai to San Francisco with one layover
Since it is double traversal (i.e. like performing multiple out in Gremlin), we would be executing 2 queries, first query to get all the routes from Mumbai and second query to get all the routes flowing into San Francisco (like an in operation).
First Query
select c.destination, c.destinationType from c where c.partitionKey='airport_Mumbai_route' and c.doc_type='edge'
Second Query
select c.destination, c.destinationType from c where c.partitionKey='airport_San Francisco_route' and c.doc_type='edge'
The union of destinations from both the queries would result into all the routes between Mumbai to and San Francisco.
Approximate RU: 11-15 RU/s for both the queries.
// Find the top ten overall in terms of incoming routes select COUNT(1) as inroutes,c.destination from c where ENDSWITH(c.partitionKey, '_route') and c.doc_type='edge' GROUP BY c.destination
The query would list the destination with the number of incoming routes to the destination airport. The results would not be ordered but this can be done easily within the code.
Approximate RU: 2,935 RU/s.
Seven best practices to follow
The following best practices are recommended:
- Store the vertex properties as a separate item rather than storing it inline. This reduces storage costs and ensures data consistency irrespective of read from either forward or reverse direction.
- For high-volume low-latency scenarios, create all 3 items (edge-details, and 2 traversal items) as part of a single transaction.
- Query on these items using the source partition key (pk) and src which represents source.
- Use the Patch API for updating specific properties within an item. The following operations are supported: Add, Set, Replace, Remove, Increment and Move.
- If you have a high-volume low-latency scenario wherein you need to update specific properties within an item, use Patch API for updating all 3 documents (e.g., in our use case scenario, the edge-details and 2 traversal items) as part of a single transaction.
- RU/s utilization is better in Azure Cosmos DB for NoSQL than the Gremlin API.
- Finally, you can leverage Change Feed to create/update the reverse traversal item. This keeps client code simple. Please note the downside for this approach: new items/updates to items will not be available instantly.
Limitations
- 2x and more levels of traversals will be expensive in terms of cost (RU/s).
- 2x and more levels of traversals will have higher latency.
- Analytical queries and aggregations are not recommended.
- Complex queries which touch multiple edges out and in operation are not recommended.
Conclusion
Using Azure Cosmos DB for NoSQL is recommended for building green-field applications. Use the information in this blog post as guidance to remodel an existing Azure Cosmos DB for Gremlin API into Azure Cosmos DB for NoSQL. It is advisable for you to test your application-specific scenarios, query access patterns, and choose the one which provides you with the best price to performance ratio. Reach out to Microsoft for any specific use case guidance. Let us know your thoughts or drop and specific questions in the comments section below.
Where to learn more.
Explore the following links for further information:
- Azure Cosmos DB Data Modeling
- Sample air-routes Data Model here for you to experiment.
About Azure Cosmos DB
Azure Cosmos DB is a fully managed and serverless distributed database for modern app development, with SLA-backed speed and availability, automatic and instant scalability, and support for open-source PostgreSQL, MongoDB, and Apache Cassandra. Try Azure Cosmos DB for free here. To stay in the loop on Azure Cosmos DB updates, follow us on Twitter, YouTube, and LinkedIn.
0 comments