

Appendix
Environment Details
- Cassandra IaaS on Azure (single VM)
- Azure VM SKU DS14-8 v2
- 8 vCPUs
- 112 GB RAM
- Single node cluster
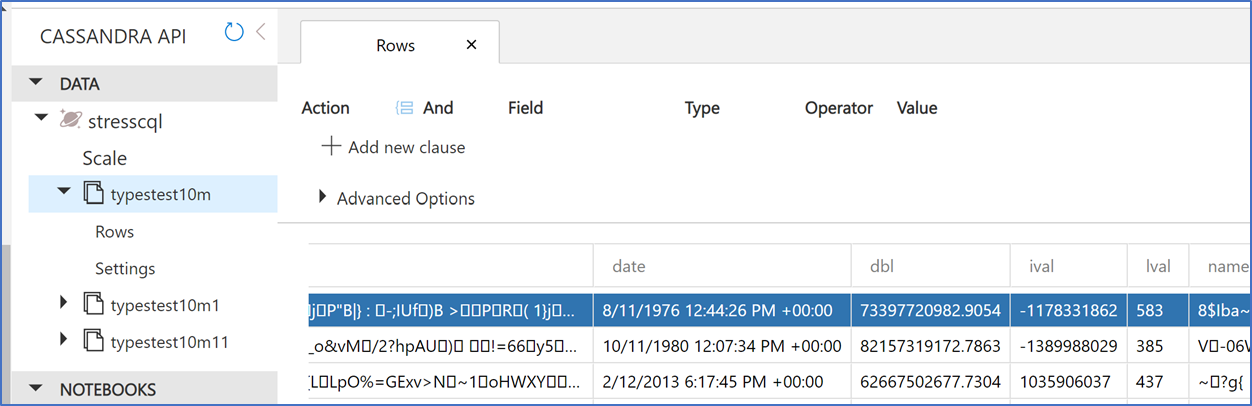
Sample of the data that was migrated to Cosmos DB Cassandra API

Keyspace/table schema:
stresscql.typestest10m
( name text,
choice boolean,
date timestamp,
address inet,
dbl double,
lval bigint,
ival int,
uid timeuuid,
value blob,
col1 text,
col2 text,
col3 text,
col4 text,
col5 text)
- Azure Databricks
- Standard Cluster/Runtime 9.1 LTS (Scala 2.12/Spark 3.1.2)
- Standard DS3_v2
- Minimum 1 to maximum 4 worker 14 GB RAM 4 cores
Azure Databricks provides a baseline scala notebook which just needs to be configured for your environment in order to function. After making the configurations, the baseline scala notebook can read from your Cassandra environment and write to your Cosmos DB. Baseline Azure Databricks configuration file can be found here
Sample of the Azure Databricks notebook and parameters that can be modified:
stresscql, table -> typestest10m, cosmosCassandra: scala.collection.immutable.Map[String,String] = Map(spark.cassandra.output.concurrent.writes -> 25, spark.cassandra.concurrent.reads -> 512, spark.cassandra.connection.ssl.enabled -> true, spark.cassandra.connection.keep_alive_ms -> 600000000, spark.cassandra.output.batch.size.rows -> 1, spark.cassandra.output.batch.grouping.buffer.size -> 512,
note: blue text above indicate configurations we can change
- Azure Cosmos DB
- Single region deployment
- Request Units sizes varied from run #1 24,000 RUs to run #5 with 80,000 RUs
See sample of data from Cassandra that was inserted into Cosmos DB
0 comments