

About the authors: Akash & Alp
We are working with many customers who for a variety of reasons such as not having to deal with patching the O/S, upgrades, scalability, etc. are looking to move their Cassandra IaaS workloads to Azure and one of the destinations is Azure Cosmos DB Cassandra API. We wanted to explore and dive deeper into performance details when we execute a historical data migration from Cassandra IaaS into Azure Cosmos DB Cassandra API. By historical data migration, we are referring to the one-time data movement as opposed to the incremental data updates which will typically come from the application-level modifications. Specifically, we wanted to explore the linear scalability of Azure Cosmos DB in terms of INSERT throughput from the lens of this historical data migration. Linear scalability is defined as increasing a compute resource by X% and observing at least a corresponding X% improvement in load performance. To validate this, we ran a series of experiments, and benchmarked the results. In these experiments, we loaded a set of documents under varying scales of Azure Cosmos DB and Azure Databricks with the objective to observe load performance scale and improvements with increasing Azure Cosmos DB capacity.
To evaluate our scalability theory, we deployed the architecture consisting of the following components:
See Appendix for deployment details of each of the above solutions
- Cassandra was deployed on Azure as an IaaS instance. We loaded a dataset of 4.08M records into a keyspace/table.
- Azure Databricks is a Spark based data integration platform and was leveraged to read from IaaS Cassandra and write to Cosmos DB Cassandra API.
- Azure Cosmos DB with the Cassandra API is where the Cassandra IaaS data will be migrated.
Setup
A couple of factors to keep in mind as we go over the findings of the benchmark:
- The Cassandra IaaS, Databricks and Azure Cosmos DB Cassandra instances are co-located in the same Azure region. This avoids latencies due to cross-region network traffic.
- Cosmos DB uses RUs (Request Units) to scale the database. Please refer to the link describing RUs to understand cost per request breakdown.
- The Cassandra instance was in a single region i.e. no geo-replication was involved.
- Data size per row was ~1.3kb and generated using Cassandra-stress tool, which is publicly available. Total data size was approximately 5gb.
- Data is evenly distributed using a composite primary key generated using random distribution. A well sharded partition key will help avoid hot partition problems. This article goes further into partitioning in Azure Cosmos DB service.
- This benchmark focuses primarily on the write path.
- Environment details like machine types and worker nodes can be found in the Appendix
Benchmark Results
The following is a summary benchmark of moving the initial dataset from Cassandra/IaaS to Azure Cosmos DB Cassandra API. Please see details on each run, and the findings after the summary section below:
| Run
|
Source Data in Cassandra | Parameters | Duration (mins) | Throttled Requests % |
| #1 | 4.08M rows | Cosmos:
24,000 RUs Azure Databricks: spark.cassandra.output.concurrent.writes -> 25, spark.cassandra.concurrent.reads -> 512, spark.cassandra.output.batch.grouping.buffer.size -> 512
|
52.36 mins | 81.5% |
| #2 | 4.08M rows | Cosmos:
40,000 RUs Azure Databricks: spark.cassandra.output.concurrent.writes -> 25, spark.cassandra.concurrent.reads -> 512, spark.cassandra.output.batch.grouping.buffer.size -> 512
|
23.07 mins | 62% |
| #3 | 4.08M rows | Cosmos:
60,000 RUs Azure Databricks: spark.cassandra.output.concurrent.writes -> 25, spark.cassandra.concurrent.reads -> 512, spark.cassandra.output.batch.grouping.buffer.size -> 512
|
14.62 mins | 19.8% |
| #4 | 4.08M rows | Cosmos:
80,000 RUs Azure Databricks: spark.cassandra.output.concurrent.writes -> 25, spark.cassandra.concurrent.reads -> 512, spark.cassandra.output.batch.grouping.buffer.size -> 512
|
11.53 mins | 0% |
| #5 | 4.08M rows | Cosmos: 80,000 RUs
Azure Databricks: spark.cassandra.output.concurrent.writes -> 20, spark.cassandra.concurrent.reads -> 512, spark.cassandra.output.batch.grouping.buffer.size -> 512
|
5.72 mins | 0% |
Green text above indicates what was changed from the previous run
Run#1
In our first run, based on estimates of how we plan to use the data set, we arrived upon an initial RU value of 24,000. Azure Cosmos DB capacity calculator can also be used to simplify this determination. We captured a baseline time of 52.36 mins to INSERT 4.08M rows. Following the first run, we adjusted the environment depending on the bottleneck(s) we found. For instance, if we found we were getting 429 errors (which translates to throttling on Azure Cosmos DB), we would increase the request units (i.e. throughput) of Azure Cosmos DB or adjust spark job parallelism. Our approach was to make only one change at a time and re-execute the run to capture the findings. In our final run, for the same dataset we were able to migrate the same 4.08M rows in 5.72 mins.
Adjustments After Run #1
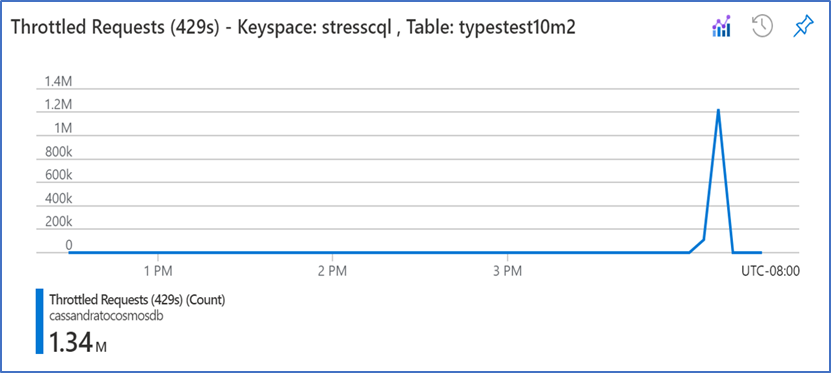
After executing Run #1, we checked the monitoring metrics for Azure Cosmos DB and we found there were many 429 throttled requests messages returned – see diagram below. Given we had a little over 4 million documents at the source, and we were seeing over 3 million 429 errors through the run duration, we knew we had to increase the RUs. Given around 81% of requests got throttled, we knew we had to increase the RUs (i.e., Cosmos DB throughput) to a larger size. The number of throttled requests vs the total requests on Azure Cosmos DB can be viewed from the Metrics or Metrics (Classic) blades within the Cosmos DB instance.

In addition to checking the various architecture components for bottlenecks, we also checked the source Cassandra IaaS VM to see if there were contentions. However, the machine was not under any strain. Although not captured in a screenshot similar to the Cassandra IaaS VM, we also reviewed the Azure Databricks environment, where CPU utilization was below 10%. Given the Cassandra Iaas VM and Azure Databricks were not under any resource strain, we could really look into increasing the parallel reads (i.e specifically within the Databricks notebook -> spark.cassandra.concurrent.reads -> 512) by adjusting the scala read settings. The approach of attempting to parallelize the read could also be a good strategy to improve performance by magnitudes order, once the 429 throttling is addressed.
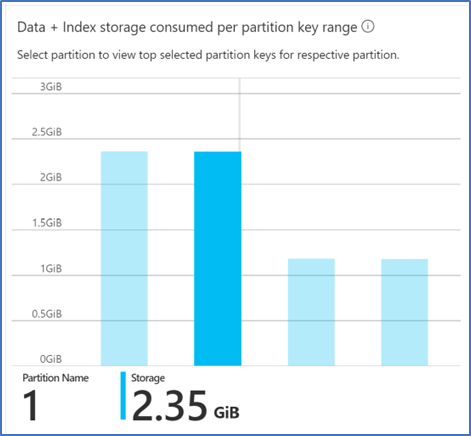
We also checked the partitions to see if they were relatively evenly distributed. Although not this article’s objective, your partition key and objective of evenly distributing data plus throughput are important. As can been in the screenshot below, our data and throughput are evenly distributed across the partitions. Please note – we also checked in detail to see if any of the partitions were hot (over used) and they were not. It is important to be aware that the RUs are distributed among the partitions and so each partition does not get the full RU allocated but only a fraction (specifically each partition will get RUs as follows (partition N / partition count total) * RUs total).
Adjustments After Run #2 and #3
After run # 2 we still saw 429 errors, but at a smaller volume and for shorter duration as compared to run#1. After run #2, we specifically had over 2.5 million 429 errors and so as a percentage it still translated to a large percentage of 62%. So, we decided to further increase throughput to 60,000 RUs in Run #3. As you can see on the diagram below, the number of 429 errors along with the duration (represented on the X-axis) was significantly lower than run #1. Specifically, for run # 3, we had 1.2 million 429 errors at peak, plus a much shorter duration (19.8% of requests were throttled)
Run #3
Since we were still getting 429 errors, we decided to bump up the RUs on Azure Cosmos DB to 80,000 and moved on to run # 4.
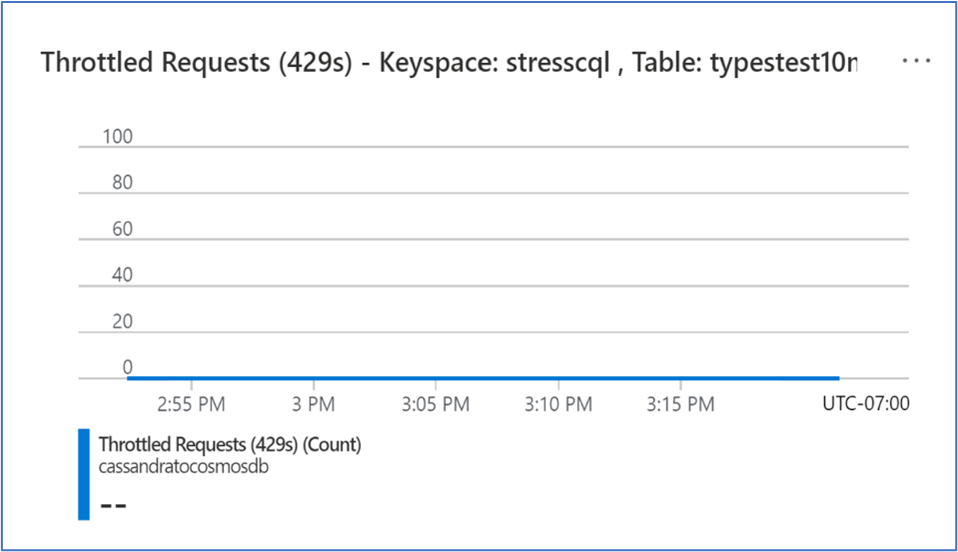
Adjustments – Run #4
After adjusting the RUs to 80,000, we no longer received any 429 errors and found the right capacity for this workload from an initial data migration perspective. Please see diagram below with no 429 errors at 80,000 RUs.
We then decided to optimize the migration scenario further and execute one more run to try and configure some of the settings on the Azure Databricks notebook. See details of Run #5 below.
Final Run Adjustments – Run #5
Our Azure Databricks was still used < 10% in terms of CPU utilization. So, in the final run, we decided to modify the notebook parameters and thought we could tweak the concurrent write setting. Our thinking was to walk down the architecture and optimize the next component. Since the 80,000 Rus capacity was enough to prevent Azure Cosmos DB throttling, we switched focus in this run on Azure Databricks optimization, and decided to address the contention on the write side than the read side. With NoSQL databases this is often true given that each INSERT () has a significant cost because of the replication of the data along with the index creation. Given Cosmos DB maintains 4 replicas of data locally within a region, an INSERT operation leads ultimately to 4 writes. Given this, we thought we would reduce the concurrent writes slightly to 20 and we found that our performance further improved to 5.72 mins. Reducing the writes to 20 means queuing a smaller number of write tasks and reduces the chances of spark jobs restarting if the Cassandra server is not able to keep up. While the 80,000 RUs were just barely enough to prevent throttling, reducing the concurrent writes per spark executor in addition gave us a further increase in performance. An alternative could’ve been to increase the concurrent writes and simultaneously increase the Azure Cosmos DB throughput above 80,000 RUs. The key takeaway is for the same resource costs, more tweaking and modifications will ultimately lead to huge performance gains.
So, to summarize, for a given dataset on an initial/one-time load, we were able to reduce the load time from 52 mins down to 5.72 mins – which translates to an order of magnitude better performance and more than linear scalability as we started from 24,000 RUs to 80,000 RUs.
Other Considerations – Cost
Azure Cosmos DB has 2 cost components:
- Azure Cosmos DB compute which is in the form of Request Units (RUs) (typically the largest cost portion)
- Storage Cost (typically the lowest cost portion)
At a high level:
100 RUs * 730 Hours per Month * $0.008 RU/s per hour
80,000 RUs * 24 hours (assuming you ran your initial load for the entire day) * 0.008 100 RU/s per hour
$153.60 USD per day
After the initial load is complete, you can reduce your 80,000 RUs to a minimum of 10% of the maximum throughput ever provisioned or 8,000 RUs. This is possible given Azure Cosmos DB is a truly elastic NoSql database, which can be scaled up or down to meet the needs of the workload. The scaling functionality can be done either manually as described above, or by using the Autoscale built-in capability. So, for on-going operations, 8000 RUs would be the minimum allowable setting:
8,000 RUs * 24 hours/day * 0.008 100 RU/s per hour =
$15.36 USD per day
Please note, we incrementally increased RUs through the experiments, and didn’t immediately set the Azure Cosmos DB at a high RU because we knew we had the ability to reduce the size to a minimum of 10% of the RU. For instance, if we had provisioned 1,000,000 RUs initially, then we could at most reduce it to 100,000 RUs for on-going operations. Something to be aware of while onboarding your workloads and configuring the throughput for Azure Cosmos DB is to plan for regular usage and the ability to scale up 10X to meet your peak needs such as data loads or migrations.
Conclusion / Lessons Learned
- Azure Cosmos DB Cassandra API was able to scale at a better than linear rate with each unit of increased capacity. In summary, we tripled the RUs and saw load performance improve more than 9 times:
| Run Summary | Load Duration |
| 24,000 RUs to 80,000 RUs ~3 times increase in capacity | 52 mins decrease to 5.7 minutes – 9 times better performance |
- Performance can be improved further while keeping costs consistent, by increasing the read rate on Azure Databricks environment. In essence, modifying the scala script to parallelize even further could lead to further performance improvements.
- We were able to migrate around 4M rows, which is about 5 GB of data within 6 minutes. This was achieved within reasonable cost as highlighted above.
- The goal was to find an optimal tradeoff between costs on Cosmos DB i.e., RUs and the speed of the migration, given a sample dataset.
0 comments