

Vector search with Azure Cosmos DB
In Part 1 and Part 2 of this series, we explored vector search with Azure Cosmos DB and best practices for scaling it to 1 billion vector datasets while maintaining low query latency. In Part 3, we saw how we can create efficient sharded DiskANN indices for multi-tenant apps.
In Part 4, we’ll look at the effect that streaming ingestion, a stream of inserts, deletes, and replaces of vectors in the database, has on the quality of the vector index. This is unlike the often reported single-shot ingestion where data is ingested once in bulk and recall is measured at the end when the index is built. Ideally, a vector index should always provide consistently high recall, including after a long stream of updates. Handling streaming scenarios tends to be challenging for many vector indexes, but we’ll see that DiskANN in Azure Cosmos DB is able to handle this with high accuracy and low latency, all while maintaining cost-efficiency.
Why is the streaming scenario so important?
Most real-world scenarios that use vector databases follow patterns of streaming ingestion:
- Data from Generative AI apps are continuously generated from conversation sessions, agentic memories, or interactions that require creating and updating of documents that can be used later on for context and personalization of AI models.
- Index freshness is key for many critical scenarios such as Retrieval Augmented Generation (RAG), where LLMs need to reason over the latest changes and session data. It is also crucial for anomaly detection, such as in financial services, where timely updates help detect potential fraudulent transactions.
Therefore, it’s important for a database to handle new and updated vectors, without reducing search recall that can degrade application quality and performance. That’s why we examine search recall for streaming scenarios, rather than for one-shot static data. This constructs a more comprehensive view of vector database performance and reflects the data patterns encountered by AI apps in production.
Maintaining high search recall when deleting vector data is a difficult problem to solve, because it would require finding and modifying vectors with direct link to the deleted vector in graph-structured vector indices. Many popular vector search solutions take one or more of the following approaches as they:
- Do not evaluate impact of updates and deletes on recall. Unfortunately, this can hide the issue from consideration.
- Rebuild the entire index after some number of updates or deletes. This is quite an expensive operation, especially at scale.
- Simply don’t handle data modifications at all, so search recall degrades as indexed data is mutated. This is problematic as your application can suffer from poorer performance and negatively impacts end-user experiences.
However, DiskANN is shown to support incremental updates that maintain recall and query efficiency without index rebuilds. We demonstrated this via runbooks, structured benchmarking experiments, in the BigANN streaming framework, and the research supporting this work was described in FreshDiskANN and In-place DiskANN.
DiskANN indexing in Azure Cosmos DB
Index construction and maintenance with DiskANN in Azure Cosmos DB consists of two asynchronous processes: IndexBuilder, which updates the vector index for inserts, replaces and deletes, and IndexVacuum which processes any stale edges in the graph due to deletes and does holistic defragmentation caused by all updates.
DiskANN is naturally incremental in that index is built by inserting new vectors in the sequential order of user requests. For deletes, we use a recently developed in-place delete algorithm (see paper) as part of the IndexBuilder. We then modified the DiskANN algorithm to work even when the coordinates of the deleted vector are not known (since the vector is deleted as part of user transaction and not accessible to the IndexBuilder). The overall time to construct the index and frequency of maintenance operations depends on the size of vector embedding, number of documents ingested and the amount of spare compute throughput (measured as RU/s for Azure Cosmos DB) available.
Benchmarking streaming scenarios
The BigANN streaming track sets up benchmarks called runbooks for measuring how vector indices handle streaming. A runbook defines a sequence of operations, inserts and deletes over an embedding dataset. They’re crafted to emulate real-world use cases where the dataset undergoes continuous modifications. After each step in the runbook, the vector index is queried for semantic search and then recall is measured using ground truth data that accompanies each step. This allowed us to plot the recall of vector index over time and thus evaluate the resilience of the index to streaming updates. An example slice of the runbook is shown below listing multiple steps with different operations at different times. More details on the runbook semantics and using them are documented here, and the code to replicate the tests in this post is available on GitHub at ‘VectorIndexScenarioSuite’.
32:
operation: "insert"
start: 4652840
end: 4872616
33:
operation: "delete"
start: 1800000
end: 1900000
34:
operation: "search"
35:
operation: "insert"
start: 4872616
end: 5184725
36:
operation: "search" Here we used 3 runbooks based on the Wiki-Cohere and Microsoft Turing-ANNS datasets, two expiration time runbooks, and one clustered runbook.
The expiration time runbooks inserted vectors with different lifespans (the number of steps between a vector’s insertion and deletion) to test how well these are handled by the index. For example, if the runbook has 𝑇𝑚𝑎𝑥 = 100 steps, the lifespan could correspond to 100, 50 and 10 steps. We set their proportion to 1:2:10, so we had roughly equal number of points of each type at any time. At each step, we inserted a 1/𝑇𝑚𝑎𝑥 fraction of the dataset in random order, assign them a random lifespan, and deleted the previous vectors when they expire.
The clustered runbook, we’ve partitioned the dataset into 64 clusters using k-means clustering. The runbook consists of 5 rounds. In each round, we iterated over all clusters and inserted a random proportion of vectors from each cluster into the DiskANN index. Then, we iterated over the clusters again and deleted a random proportion of the active vectors in each cluster from the index. Nearby vectors were always inserted or deleted together, and we measured the average query recall after processing each cluster. This runbook evaluated the index’s quality under extreme changes in the distribution of the active vector set. Note that that it’s much more challenging for a vector index to maintain recall here than in the expiration time runbook.
For each runbook, our test application performed multiple Azure Cosmos DB operations. On the search step, the app issued a fixed set of 5-10k queries. It compared the results with the corresponding ground truth file for that search step and analyzed the recall at that step. The plots below show the recall measurements across the runbooks. To compare the impact of not handling deletes carefully, we also do another run where the indexer handles delete operations by just dropping the vector but does nothing to fix the index. This is often the case with many vector databases, so it offers a visual comparison between DiskANN (with in-place deletes) and other vector indexes (without in-place deletes).
MSTuring 1 million expiration runbook
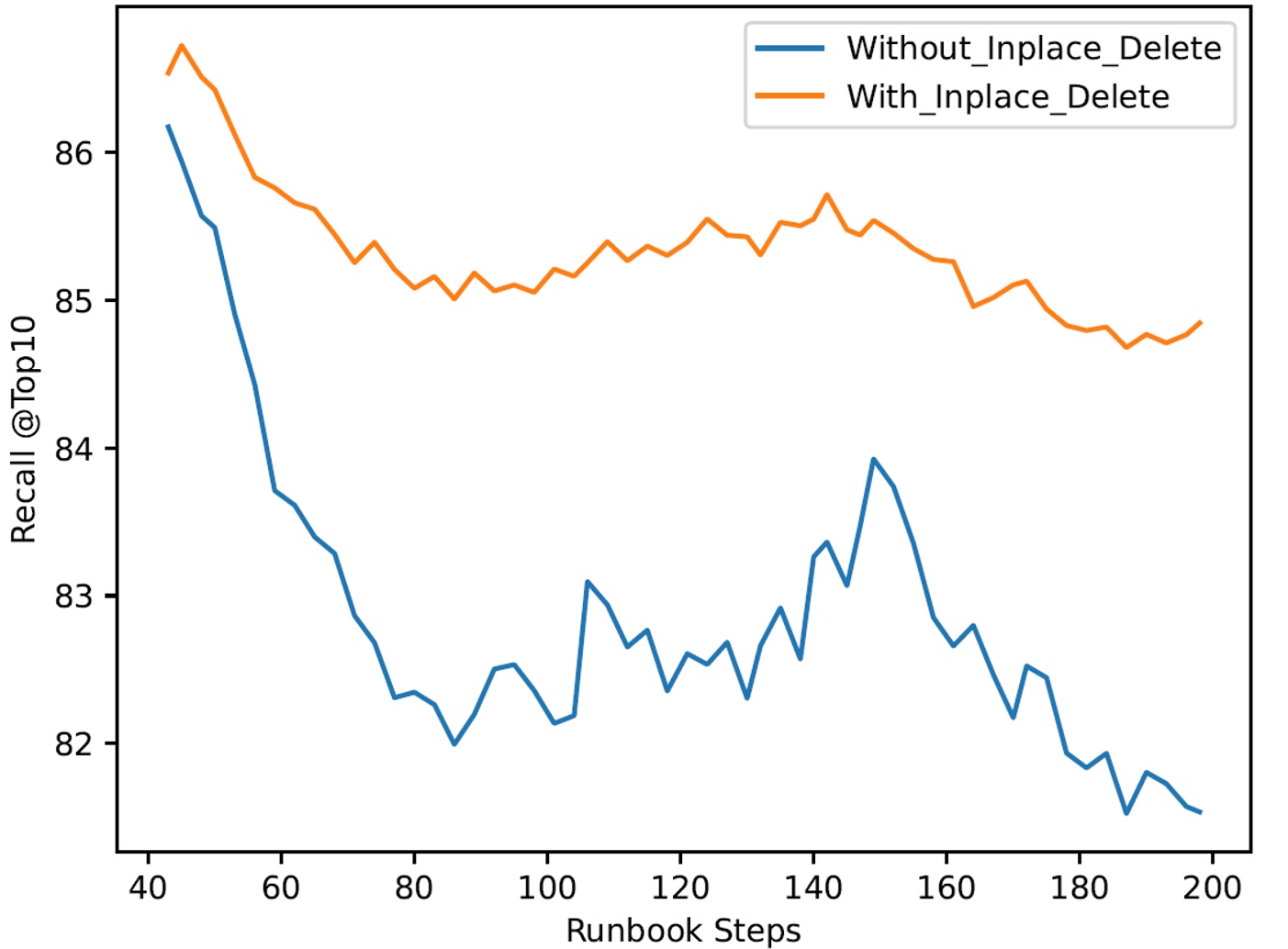
Wiki Cohere 10 million expiration runbook
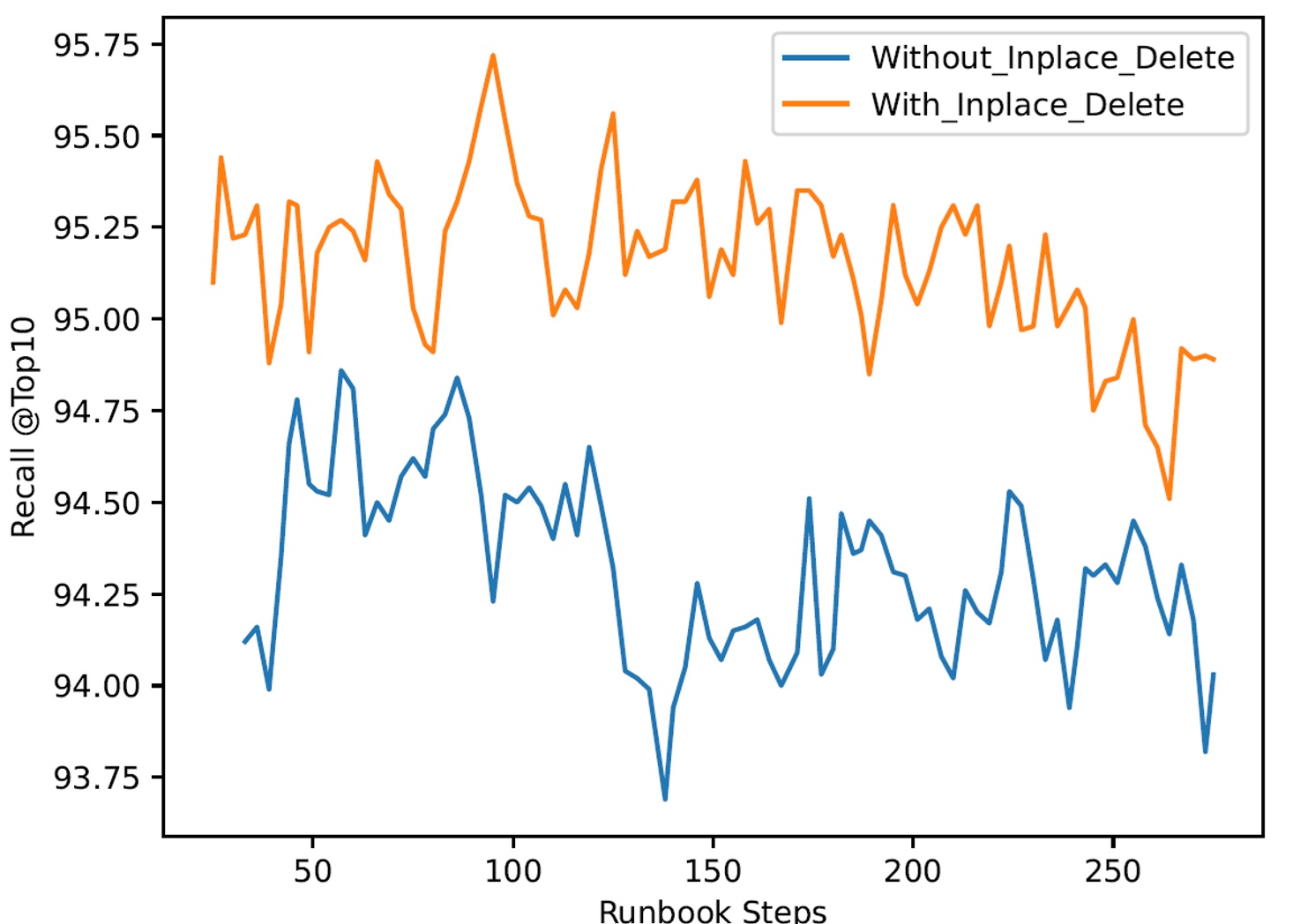
MSTuring 10 million clustered runbook

Summary
- Search recall can degrade significantly if updates and deletes aren’t handled carefully, or the index is not surgically edited after deletes.
- To address this problem, the vector index can be modified locally for each delete so that large operations to fix the index later are not needed. This significantly reduces indexing costs, prevents latency spikes, and avoids diminishing search recall with data mutations.
- Since DiskANN in Azure Cosmos DB handles index modifications efficiently, it’s possible to maintain high search recall with a large number of data mutations and deletions.
Altogether, this means that by using DiskANN in Azure Cosmos DB to power your semantic search scenarios, your AI and search applications can keep running smoothly at high accuracy, while keeping costs low, even in production scenarios where the data is changing!
Next Steps
- Learn more about Vector Search in Azure Cosmos DB for NoSQL.
- Visit our AI Samples GitHub Repo for links to documentation, code samples, solutions accelerators, videos, and more!
- Try out the scenario in this blog with companion code at GitHub.
Leave a review
Tell us about your Azure Cosmos DB experience! Leave a review on PeerSpot and we’ll gift you $50. Get started here.
About Azure Cosmos DB
Azure Cosmos DB is a fully managed and serverless NoSQL and vector database for modern app development, including AI applications. With its SLA-backed speed and availability as well as instant dynamic scalability, it is ideal for real-time NoSQL and MongoDB applications that require high performance and distributed computing over massive volumes of NoSQL and vector data.
To stay in the loop on Azure Cosmos DB updates, follow us on X, YouTube, and LinkedIn.
0 comments