

AltGraph is the idea of implementing “graph workloads” not with a graph database, but with the more general-purpose Azure Cosmos DB for NoSQL (formerly known as the “SQL API”). Azure Cosmos DB for NoSQL is highly performant and offers the best integration with the rest of Azure. It also offers the lowest learning curve since most of the industry already understands SQL (Structured Query Language), the query language used by this database.
AltGraph was the topic of episode #59 of Azure Cosmos DB Live TV, and has since been expanded to include the v2 IMDb graph.
Perception
Many customers I speak with initially visualize their use-cases as a graph, such as the following diagram. They then reason that since the application is visualized as a graph means that the underlying datastore needs to be implemented as a graph database. It is my assertion that this is not true – the underlying data can be stored and traversed in alternative and possibly much more efficient datastores, such as Azure Cosmos DB for NoSQL. JavaScript libraries can be used to create the graph visualizations.
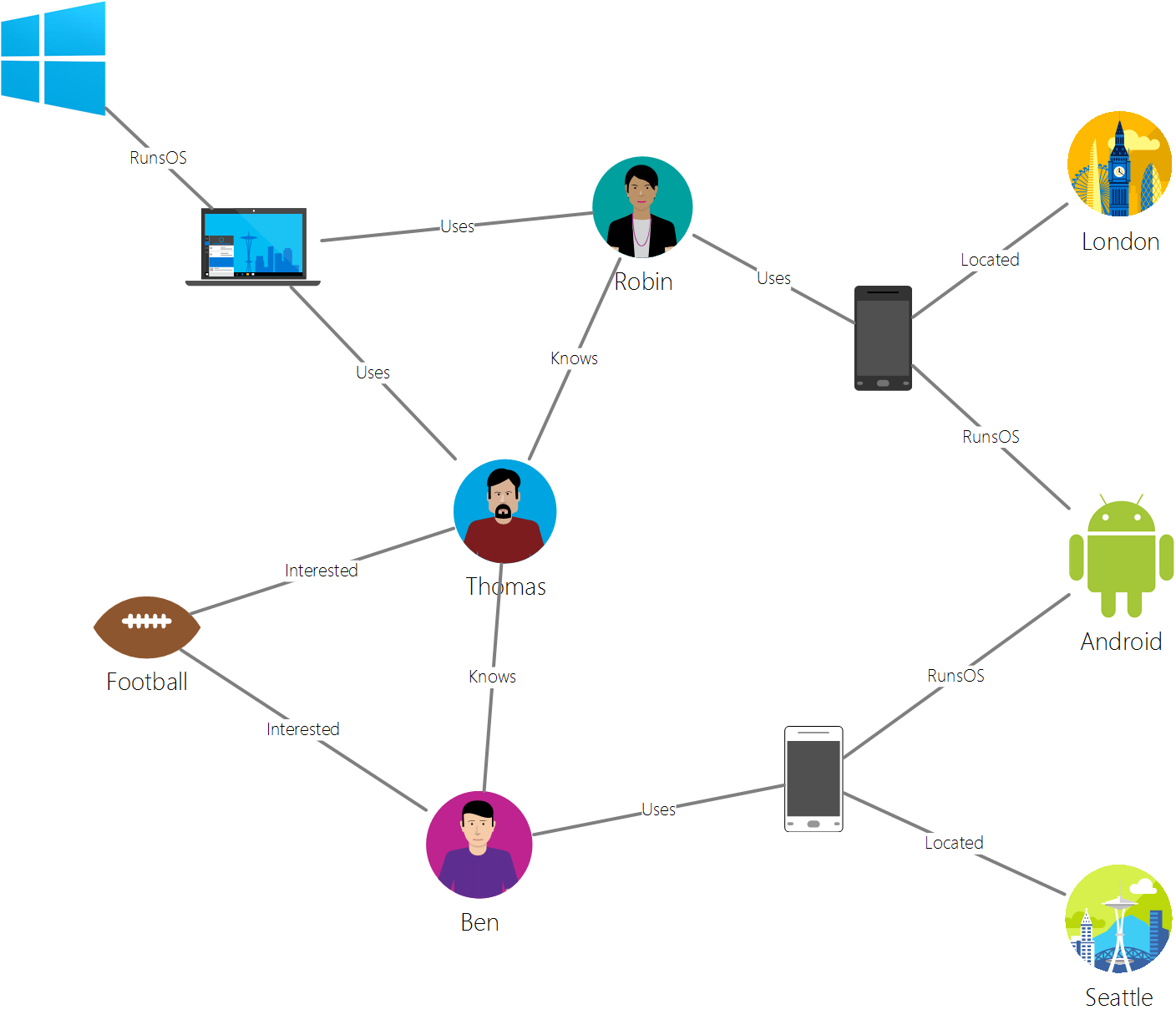
Application Architecture
A graph application is typically built with much more than just a database at the center of the solution. A typical solution integrates several services, and this is where Azure and Azure Cosmos DB shines – the ease of integrations. In the diagram below, the native integrations that Azure Cosmos DB supports are shown in red. These are implemented in a reliable and scalable way by the Azure PaaS services themselves, so you, the customer, don’t have to write “glue code” or explicit ETL to integrate them.
Four of these integrations I’d like to call out here are Azure Functions, Azure Cognitive Search, Azure Synapse Link for Azure Cosmos DB, and Azure Synapse Analytics. With Azure Functions you can observe the Azure Cosmos DB change-stream, and thus have event-driven logic in your application for real-time processing. Azure Cognitive Search supports automatic indexing of Azure Cosmos DB containers. For some applications their queries/searches can be much more fluent and cost-effective by using this search engine. Azure Synapse Link implements the HTAP pattern (Hybrid Transactional Analytic Processing) to automatically copy your documents to a low-cost datastore for processing in a “Big Data” batch environment such as Apache Spark in Azure Synapse Analytics.
Thus, the total Azure and Azure Cosmos DB-based graph application can leverage the “best tool for the job”, as well as reduce costs, with these efficiencies.
Conversely, it is an antipattern to use one database for both real-time and batch/analytic purposes, as the DBMS often won’t scale under the workload, and typically offers sub-optional support for one or more of these access patterns.
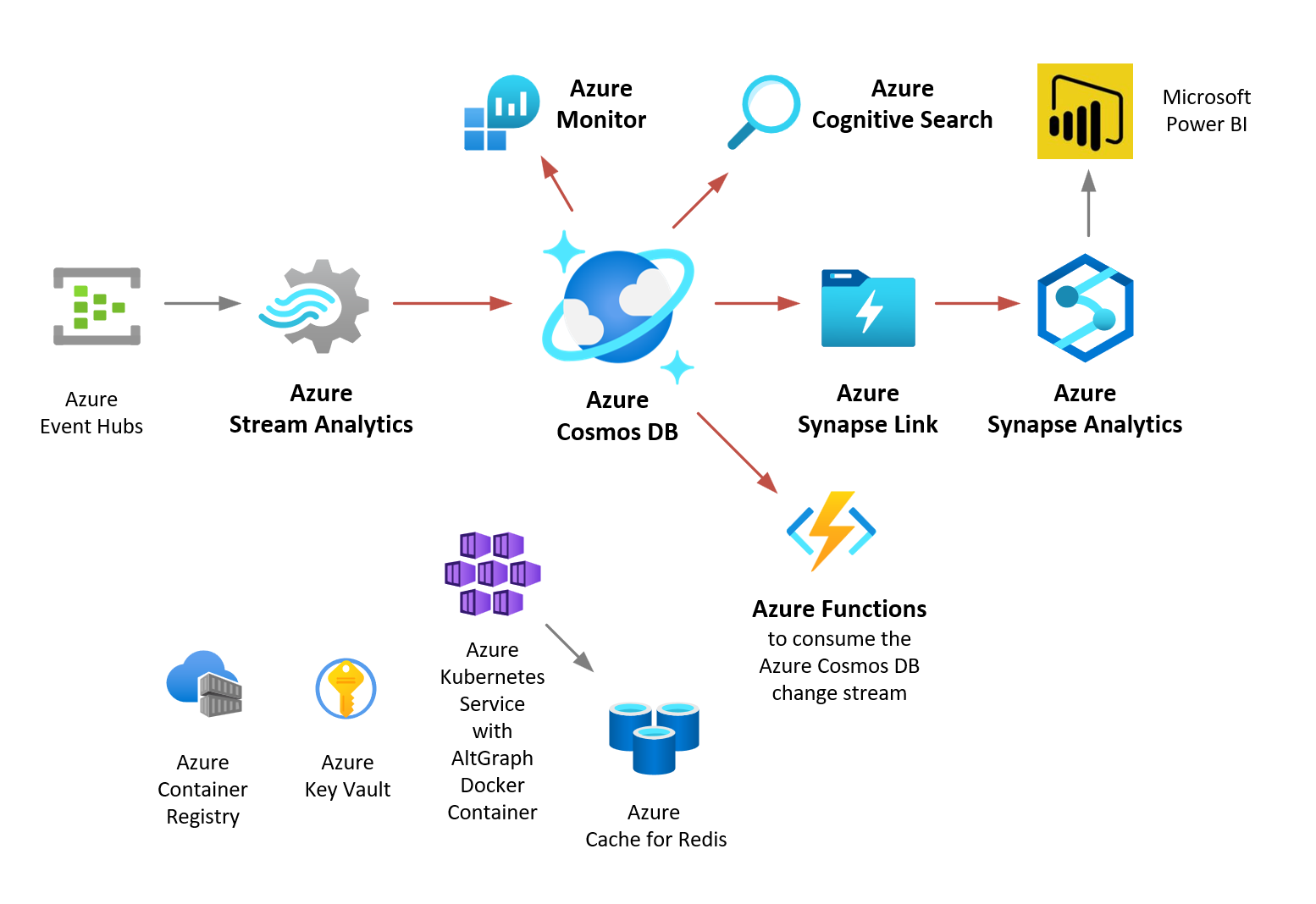
So, what again is AltGraph?
AltGraph isn’t a product, or another Azure PaaS service. Instead, it’s a set of reference applications that demonstrate how to build “graph applications” with Azure Cosmos DB for NoSQL and leverage its’ features to achieve performant, integrated, and low-cost solutions. It currently demonstrates two different graph use-cases, with two different implementations.
The first is a Bill-of-Materials use-case that uses data from the NPM (Node Package Manager) ecosystem. The implementation uses the concept of RDF graph database “triples”, but implemented with Azure Cosmos DB. Roughly 20-million triples can be stored efficiently in a single Azure Cosmos DB logical partition, which makes their queries both fast and low-cost. Optionally, these can be cached using Azure Cache for Redis or the Azure Cosmos DB integrated cache. Additionally, in-memory graph traversal logic can be utilized that is 1000x faster than DBMS disk IO.
A “Triple” is a data structure that links a subject, an object, and a predicate. For example, in the relationship “Chris works at Microsoft” the subject is Chris, the object is Microsoft, and the predicate is “works at”. Triples can be visualized like this:

In the AltGraph reference implementation, the Triple documents look like the following. They have additional attributes to enable fast vertex document point-reads in Azure Cosmos DB. The optional subjectTags and objectTags allow the application to efficiently “peek” into the adjacent vertex documents, for their primary attributes, without actually reading those documents.

The second reference application is a rich Social Network graph that uses IMDb (Internet Movie Database) data. This large dataset is very relatable and can be used to explore the “Six Degrees of Kevin Bacon” graph challenge. The implementation of this reference app uses the JGraphT Java library which offers very fast in-memory processing as well as a comprehensive set of graph traversal algorithms such as Dijkstra Shortest Path, Centrality, and Page Rank. Over 1-million movie and actor vertices are stored in the memory of the JVM, as well as 3.9 million edges in just 1.5GB of memory. Larger in-memory graphs are possible. Using a combination of in-memory graph traversals, and point-reads to Azure Cosmos DB, can result in a very performant and cost-effective solution.
This reference application screenshot shows “Two degrees of Kevin Bacon” and uses D3.js for interactive JavaScript visualizations. The graph traversal took only 3 milliseconds to execute and consumed zero Azure Cosmos DB request units (RUs).
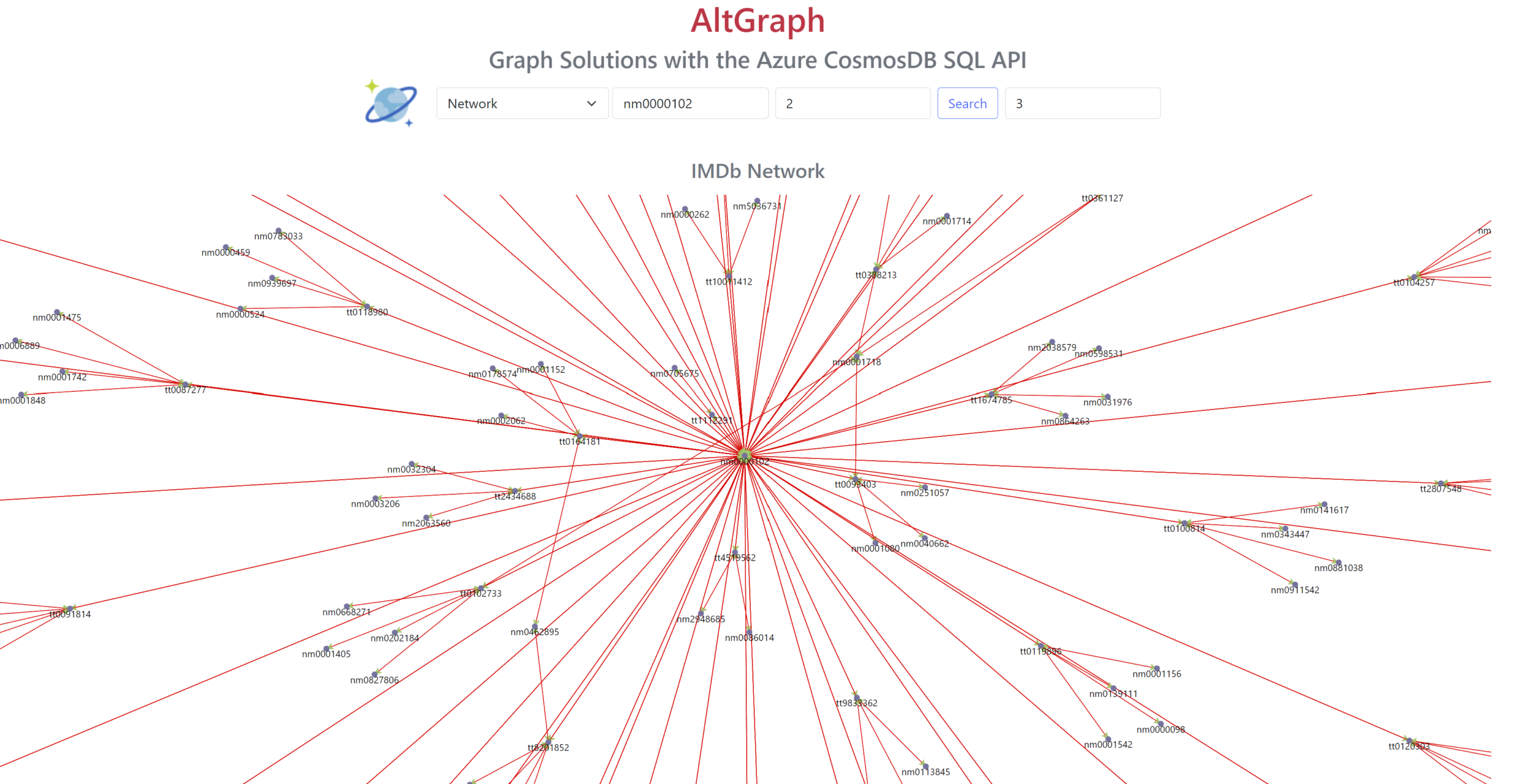
Are other implementations of “AltGraph” possible? Yes! I’m sure that each customer will create their own implementations, perhaps inspired by the examples in this GitHub repository. The Microsoft team is here to support you in those efforts and ensure that you are successful.
Get started:
- Learn about Azure Cosmos DB and get started free
- Find technical documentation about Azure Cognitive Search and Azure Cache for Redis
- Learn about JGraphT
- Visit the AltGraph GitHub repository
About Azure Cosmos DB
Azure Cosmos DB is a fast, distributed NoSQL and relational database built for high-performance applications of any size or scale. It’s a fully-managed database with support for open-source PostgreSQL, MongoDB, and Apache Cassandra, automatic and instant scalability, and SLA-backed availability and speed. Take advantage of free dev/test offers to start building today.
0 comments