

Introduction
A recommended best practice in Azure Cosmos DB for NoSQL is to avoid overly large item sizes. An Azure Cosmos DB item can represent either a document in a container, a row in a table, or a node or edge in a graph, depending on which API you use. Though the maximum size of an item allowed in Azure Cosmos DB for NoSQL is 2 MB, it is strongly recommended to restrict item sizes to 1 – 5 KB. This blog post covers multiple approaches that you can use to model large objects within your Azure Cosmos DB-backed application.
This post draws from our experiences of collaborating with different Software Engineering and Line-Of-Business (LOB) Application teams at Walmart.
Why should I avoid large items?
Serialization is the process by virtue of which Azure Cosmos DB SDKs convert a Java POJO or .NET object into JSON. The SDKs require more time and high CPU utilization on the client-side to serialize large item sizes (e.g., 500 KB, 700 KB) for sending the JSON across the wire during a CRUD call. In high volume scenarios, this could result in users experiencing higher than normal write latency with a high percentage of create item requests getting HTTP Status code 408 (time out) eventually. Your success with Azure Cosmos DB depends on how well you define and model for access patterns during data modeling.
Short summary of the design patterns covered in this blog post.
| # |
Design Pattern |
User-end experience |
| 1 | Default behavior | You receive “Error 413: Entity too large”. |
| 2 | CQRS: Store large item in Azure Blob Storage with a pointer in Azure Cosmos DB | You should use this for applications needing high durability and low-cost. |
| 3 | Split large item | Requires re-modeling at container level. |
| 4 | Compress large item | Only applicable for scenarios wherein additional compute time for uncompressing is OK. |
Design Patterns
Pattern #1: Default Behavior
The default behavior for Azure Cosmos DB for NoSQL is to reject items which are over the maximum permissible size limit. The limit is 2 MB. In such a situation, you are returned an error message indicating the item size is larger than the permissible limit. It is the responsibility of the developer to handle the exception, and implement the correct behavior, which could be based on one or more of the following design patterns mentioned below.
The error encountered is similar to:
2019-10-01T00:34:11.057681415Z {Error: Message: {"Errors":["Request size is too large"]} 2019-10-01T00:34:14.057755320Z RequestStartTime: 2019-10-01T00:34:13.9695930Z, RequestEndTime: 2019-10-01T00:34:13.99955676Z, Number of regions attempted:1 2019-10-01T00:34:14.057768921Z ResponseTime: 2019-11-01T00:43:13.9995776Z, StoreResult: StorePhysicalAddress: rntbd:<<>>p/, LSN: -1, GlobalCommittedLsn: -1, PartitionKeyRangeId: , IsValid: True, StatusCode: 413, SubStatusCode: 0, RequestCharge: 0, ItemLSN: -1, SessionToken: , UsingLocalLSN: False, TransportException: null, ResourceType: Document, OperationType: Create
This error is flagged off with HTTP Status Code 413. This refers to the fact that the item size in the request exceeded the allowable item size for a request. In such a scenario, it is recommended that you try and know the exact item size that you want to process. You can use the Azure Cosmos DB SDK to determine the size of the item size before sending it. Use JsonConvert.SerializeObject which serializes the specified object to a JSON string. You can then find the size sent over the wire using Encoding.UTF8.GetBytes.
public static int GetTakeCount(IEnumerable<object> docs, int maxSizeKb = 500) { var takeCount = docs.Count(); while(takeCount > 1) { var bytes = Encoding.UTF8.GetBytes(JsonConvert.SerializeObject(docs.Take(takeCount))); if((bytes.Length / 1000) <= maxSizeKb) { // array is small break; } takeCount = Convert.ToInt32(Math.Ceiling((double)takeCount / 2)); } return takeCount; }
Pattern #2: CQRS: Store large item in Azure Blob Storage with a pointer in Azure Cosmos DB
If you have a use-case scenario wherein you need to be able to store a large item (usually in the form of a Binary Large Object (or, Blob)), it is recommended that you store the item in Azure Blob storage. Azure Blob storage is purpose-built storage for providing high durability and low-cost. You can store the meta-data related to the large item along with reference URI links as item properties in Azure Cosmos DB. As a developer, you need to refactor your application code to read and write blobs from the Azure Blob storage container.
Command and Query Responsibility Segregation (CQRS) pattern ensures that you separate write (or, update) and read operations for the Azure Cosmos DB data store using a queue for asynchronous processing. This will ensure high performance, scalability, and security of your user-end application.
Three practical design decisions for this pattern include:
- You need to ensure data object mapping does not get overly complicated. This will affect latency for writes and reads while writing and reading large items from the Azure Blob storage container respectively.
- You need to handle data contention on the client-end wherein two or more write operations performed in parallel could be accessing (updating and subsequently reading) the same set of data. Azure Cosmos DB has support for multiple types of CRUD operation conflict resolution policies including Last Write Wins (LWW) and custom conflict resolution via a merge stored procedure. Read here for further information.
- You need to encapsulate any business logic-related customization in your application code. This should not be part of the Azure Cosmos DB data model.
This pattern is illustrated using the architecture below:
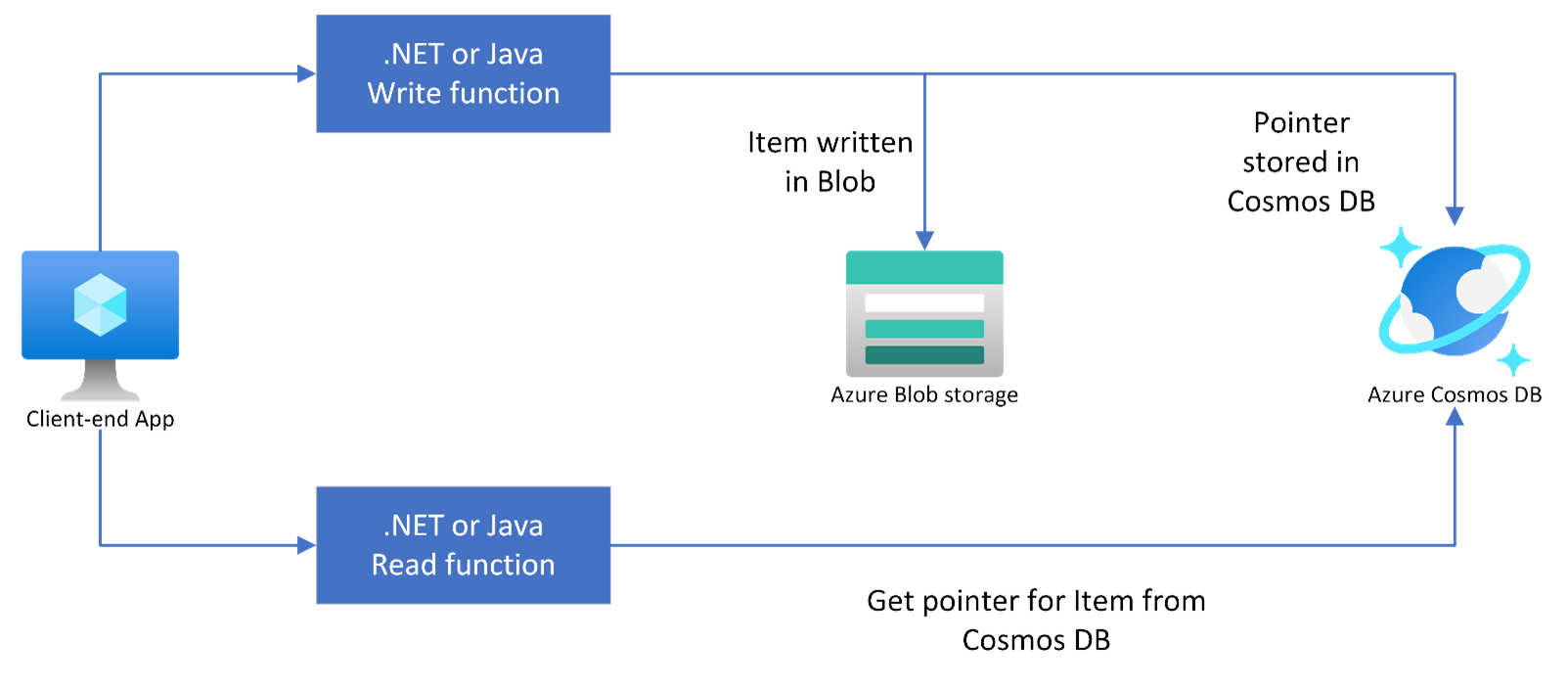
In a real-life scenario, e.g., you are building a Content Indexing egress API with high volume and sudden burst generation of items, you could introduce additional layers for handling scalability into the solution architecture with distinct read and write models serving the data layer in Azure Cosmos DB for NoSQL.
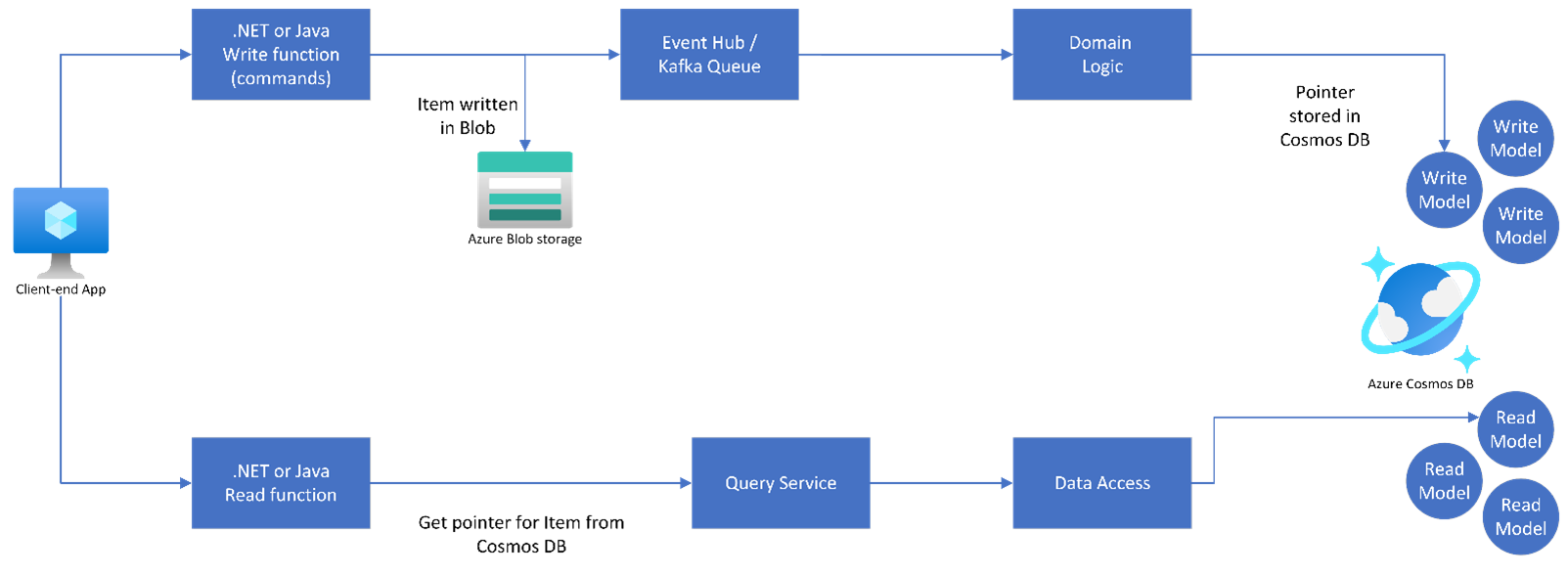
Pattern #3: Split large item
This involves splitting the large item into multiple smaller items based at an item attribute-level analysis. This involves adopting any one of the following strategies:
Strategy #3a: Splitting attributes into required versus non-required based on a specific Query Pattern:
This requires you to understand your key query pattern, and the necessary attributes in the items which are required to perform those operations. E.g., you are an Azure Cosmos DB developer building an application for a chain of online medical stores. You have architected an eCommerce application which uses Azure Cosmos DB for NoSQL as a data source. You have chosen to ingest all data related to a nutrition dataset in an Azure Cosmos DB container.
The following is a sample of the document in the Azure Cosmos DB for NoSQL container.
{
"id": "03226",
"description": "Babyfood, dessert, fruit pudding, orange, strained",
"tags": [
{
"name": "babyfood"
},
{
"name": "dessert"
},
{
"name": "fruit pudding"
},
{
"name": "orange"
},
{
"name": "strained"
}
],
"version": 1,
"foodGroup": "Baby Foods",
"nutrients": [
{
"id": "612",
"description": "14:0",
"nutritionValue": 0.088,
"units": "g"
},
{
"id": "629",
"description": "20:5 n-3 (EPA)",
"nutritionValue": 0,
"units": "g"
}
],
"servings": [
{
"amount": 1,
"description": "oz",
"weightInGrams": 28.35
},
{
"amount": 1,
"description": "jar",
"weightInGrams": 113
}
],
"_rid": "hxoIAP3QYIkDAAAAAAAAAA==",
"_self": "dbs/hxoIAA==/colls/hxoIAP3QYIk=/docs/hxoIAP3QYIkDAAAAAAAAAA==/",
"_etag": "\"04012883-0000-0700-0000-6177d8510000\"",
"_attachments": "attachments/",
"_ts": 1687544113
}
In the JSON above, foodGroup is the partition key for the container. Your primary query pattern is a point-read based on id and partition key for the container. Assuming you have a large number of additional attributes (e.g., minimum 10 tags in 100,000 items, and minimum 4 tags in 100,000 items), which are not being utilized by your top 25 queries, you could proceed to remove the tags from the items. If an in-partition query currently costs 3.22 RUs, you will observe a much smaller item size resulting in 2.8 RUs, in our case. This, iterated over a million documents, results in substantial cost savings and optimized query performance as well.
Strategy #3b: Bucketing attributes into separate list items based on the partition key:
This requires you to understand your key query pattern, and then separate the attributes to distinct items and bucket them based on the partition key. You can store the items in the same container and query them based on need which improves query performance and reduces I/O costs considerably. The following is a sample of an item in an Azure Cosmos DB for NoSQL container.
{ "id": "03226", "description": "Babyfood, dessert, fruit pudding, orange, strained", "tags": [ { "name": "babyfood" }, { "name": "dessert" }, { "name": "fruit pudding" }, { "name": "orange" }, { "name": "strained" } ], "version": 1, "foodGroup": "Baby Foods", "nutrients": [ { "id": "612", "description": "14:0", "nutritionValue": 0.088, "units": "g" }, { "id": "629", "description": "20:5 n-3 (EPA)", "nutritionValue": 0, "units": "g" } ], "servings": [ { "amount": 1, "description": "oz", "weightInGrams": 28.35 }, { "amount": 1, "description": "jar", "weightInGrams": 113 } ], "_rid": "hxoIAP3QYIkDAAAAAAAAAA==", "_self": "dbs/hxoIAA==/colls/hxoIAP3QYIk=/docs/hxoIAP3QYIkDAAAAAAAAAA==/", "_etag": "\"04012883-0000-0700-0000-6177d8510000\"", "_attachments": "attachments/", "_ts": 1635244113 }
foodGroup is the partition key for the container. If for a given use case, your application requires a query per product level tags, you could separate the items and create a read model specifically targeting that query.
SELECT * FROM c WHERE c.foodGroup = “Baby Foods” AND c.tags.name = “babyfood” { "id": "132541", "tags": [ { "name": "babyfood" }, { "name": "dessert" }, { "name": "fruit pudding" }, { "name": "orange" }, { "name": "strained" } ], "foodGroup": "Baby Foods", "_rid": "hxoIAP3QYIkDAAAAAAAAAA==", "_self": "dbs/hxoIAA==/colls/hxoIAP3QYIk=/docs/hxoIAP3QYIkDAAAAAAAAAA==/", "_etag": "\"04012883-0000-0700-0000-6177d8510000\"", "_attachments": "attachments/", "_ts": 1635244113 }
You could take this analysis further by studying the most commonly recurring pattern of search queries for the Baby Foods tag value and group the most commonly used ones together and move the not so commonly used attributes to either a separate item container, or to cold storage (e.g., Azure Blob container).
Pattern #4: Compress large item
If Pattern #2 and #3 are not applicable, another strategy could be using a fast data compression and decompression library, e.g., Snappy. Snappy is a fast data compression and decompression library written in C++ by Google based on ideas from LZ77 and open-sourced in 2011. The pattern here utilizes an underlying CQRS pattern wherein the write function uses a Snappy function to compress the item. The library then stores the item in a distinct write-model in Azure Cosmos DB for NoSQL.
It is recommended that you test out different permutations and combinations for the level of compression which could be performed by a specific library against specific item sizes, and the time it takes for the compression and decompression to happen during reads. This analysis will determine whether this is a feasible pattern for your specific use-case and read/write SLAs. If not, then either Pattern #2 or #3 should be the obvious choice instead of Pattern #4.
There will be a compute overhead for this pattern and it will not be beneficial for high volume, low burst scenarios requiring very low latency processing requirements.
The write function compresses the item and generates a compressed string. The read function uncompresses the item to the original verbose payload. The pattern is as illustrated below:
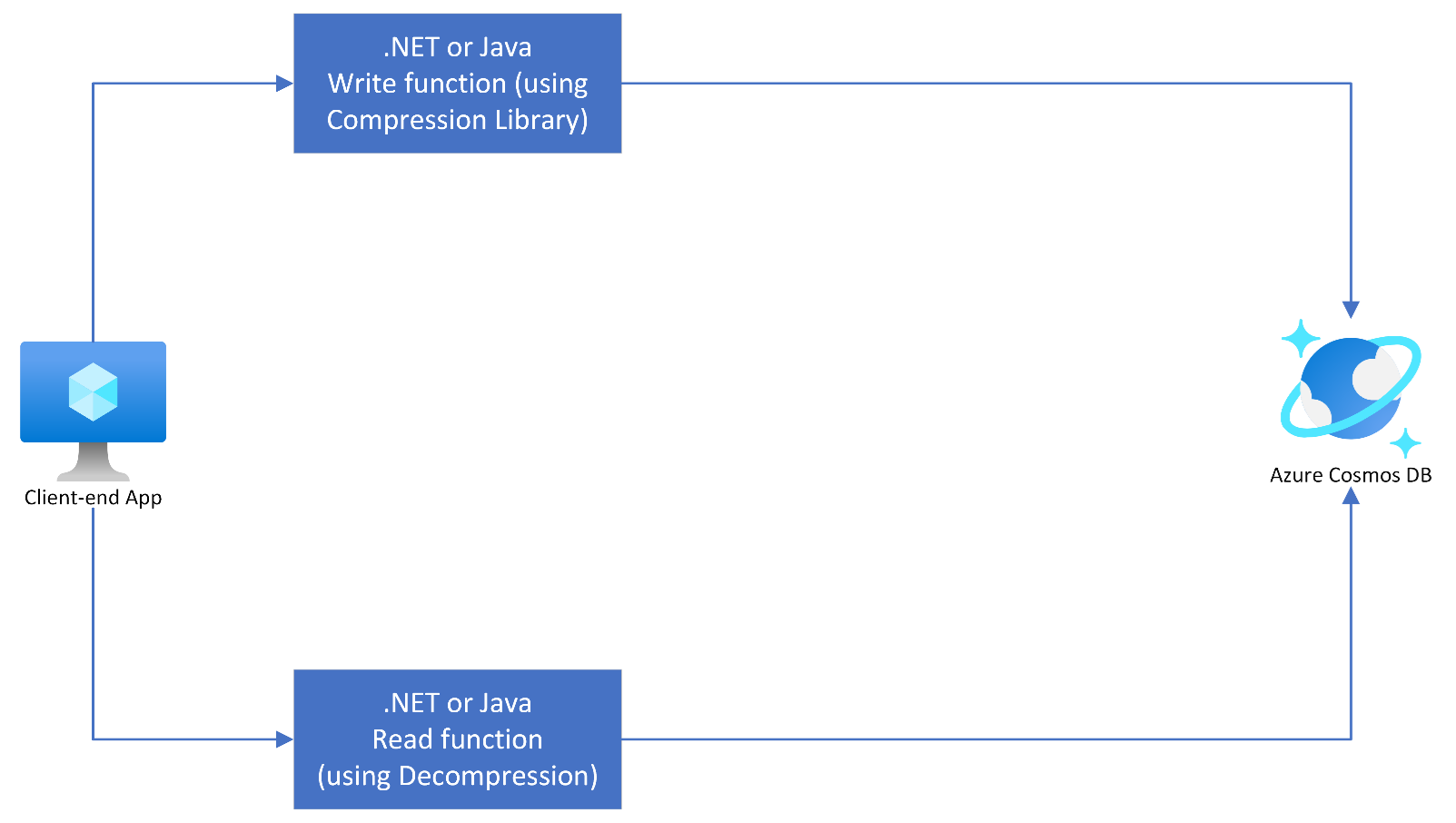
A practical implementation could be a hybrid pattern of #2 and #4, as illustrated below:
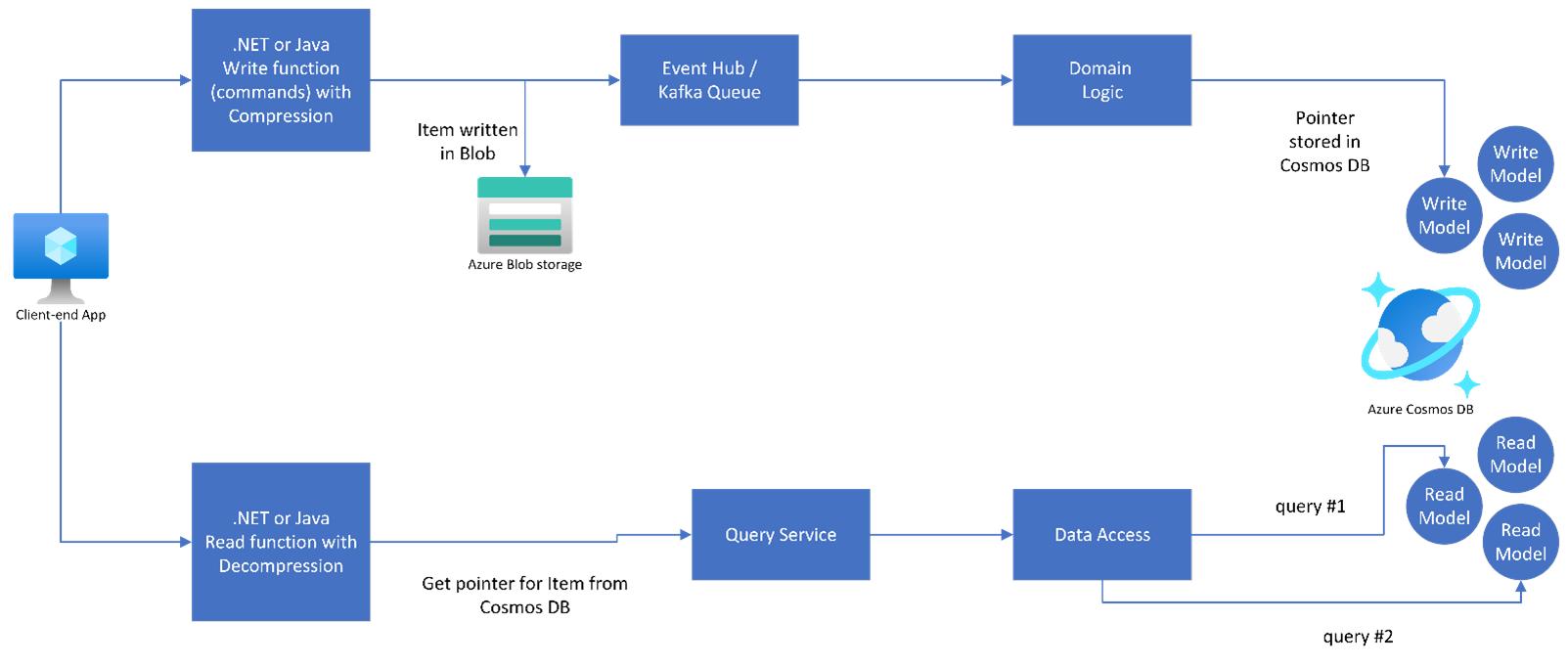
Conclusion
Your specific use case will determine which is the most effective pattern to leverage for handling large item sizes in Azure Cosmos DB for NoSQL. Five key parameters which you should test include: volume of requests, nature of requests (real-time versus batch), Request Unit (RU) costs per operation, latency (low-latency scenarios) and finally, compute and application-end complexities and overhead(s) for a specific operation. It is advisable for you to test out the scenarios in this blog post and adopt the one which provides you with the best price to performance ratio in the long run.
Have you faced any challenges in handling large item sizes in Azure Cosmos DB for NoSQL in any of your own projects? How did you overcome them? Let us know your thoughts in the comments section below.
Where to learn more.
Explore the following links for further information:
- Azure Cosmos DB Data Modeling
- Azure Cosmos DB Model and Partition Data using a real-world example
- Azure Cosmos DB Live TV – YouTube Channel
- Azure Cosmos DB Certification: DP-420 Exam Official Microsoft Learn Collection
- Azure Cosmos DB Blog. Subscribe for latest news, updates & technical insights.
0 comments