

Guest Post
Marco Minerva has been using .NET since its first introduction. Today he works as a freelance consultant and is involved in designing and developing solutions for the Microsoft ecosystem. He is a speaker at technical events, writes books and articles about developing and makes live streaming about coding on Twitch. He is a Microsoft MVP since 2013. Thanks Marco!Vector databases like Qdrant and Milvus are specifically designed to efficiently store, manage, and retrieve embeddings. However, many applications already use relational databases like SQL Server or SQL Azure. In such cases, installing and managing another database can be challenging, especially since these vector databases may not offer all the features of a modern relational database like Azure SQL or SQL Server.
This is where the new vector data type in SQL Azure becomes extremely useful. It allows you to create Retrieval-Augmented Generation (RAG) solutions by storing embeddings in the same place as your other data, eliminating the need for an external vector database.
Database Vector Search Sample App
For a practical example, check out the GitHub repository https://github.com/marcominerva/SqlDatabaseVectorSearch showcases how to use the native vector type in Azure SQL Database to perform embeddings and RAG with Azure OpenAI.

The application enables users to load documents, generate embeddings, and save them into the database as vectors. It also supports performing searches using Vector Search and Retrieval-Augmented Generation (RAG). Currently, the application supports PDF, DOCX, TXT, and MD file formats. Vectors are saved and retrieved using Entity Framework Core with the EFCore.SqlServer.VectorSearch library. Additionally, Embedding and Chat Completion functionalities are integrated with Semantic Kernel.
This repository includes a Blazor Web App and a Minimal API, which allow for programmatic interaction with embeddings and RAG.
Supported features
- Conversation History with Question Reformulation: This feature allows users to view the history of their conversations, including the ability to reformulate questions for better clarity and understanding. This ensures that users can track their interactions and refine their queries as needed.
- Information about Token Usage: Users can access detailed information about token usage, which helps in understanding the consumption of tokens during interactions. This feature provides transparency and helps users manage their token usage effectively.
- Response Streaming: This feature enables real-time streaming of responses, allowing users to receive information as it is being processed. This ensures a seamless and efficient flow of information, enhancing the overall user experience.
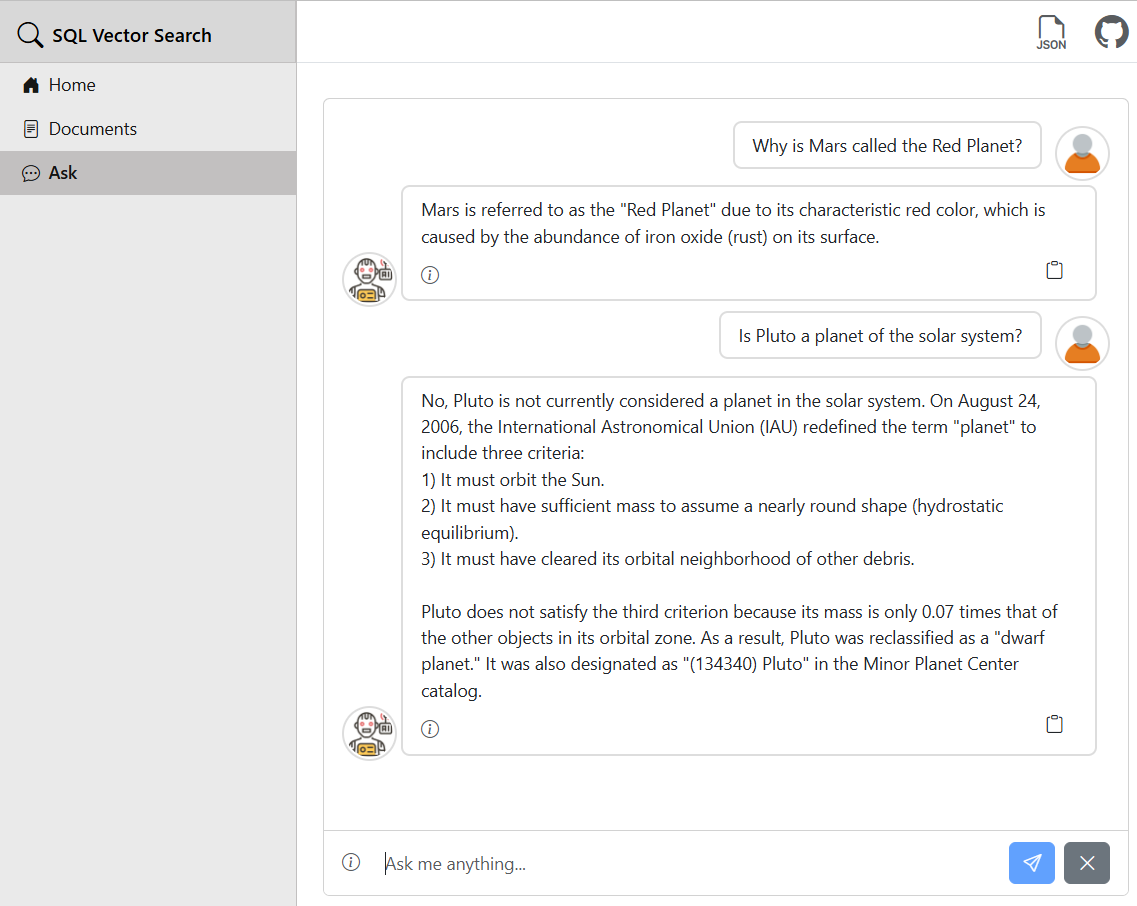
Web App
The Blazor applications provide fully functional chat interface:
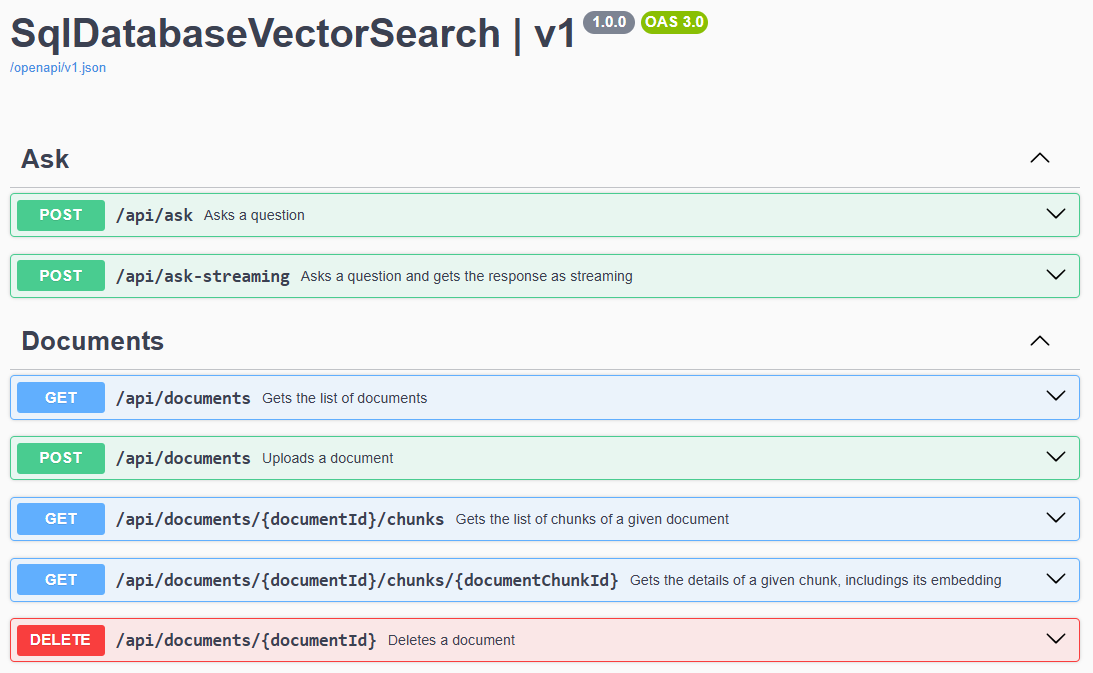
Web API
Aside from the fronted app, all the features are available also via REST API so that you integrate the sample with any fronted you many want to create by yourself:
Getting Started
To run the application in your own environment make sure to follow the following steps:
- Clone the repository
- Create an Azure SQL Database
- Open the appsettings.json file and set the connection string to the database and the other settings required by Azure OpenAI
- If your embedding model supports shortening, like text-embedding-3-small and text-embedding-3-large, and you want to use this feature, you need to set the Dimensions property to the corresponding value. If your model doesn’t provide this feature, or do you want to use the default size, just leave the Dimensions property to NULL. Keep in mind that text-embedding-3-small has a dimension of 1536, while text-embedding-3-large uses vectors with 3072 elements, so with this latter model it is mandatory to specify a value (that, as said, must be less or equal to 1998).
- You may need to update the size of the VECTOR column to match the size of the embedding model. The default value is 1536. Currently, the maximum allowed value is 1998. If you change it, remember to update also the Database Migration.
- Run the application and start importing your documents
- If you want to directly use the APIs:
- import your documents with the /api/documents endpoint.
- Ask questions using /api/ask or /api/ask-streaming endpoints.
And then you’re good to go!
Thanks for the great effort you put into this helpful app demo. A couple of Azure SQL Server side items that I forgot caused the app to not load initially. Here, they are to assist anyone else setting up this app for a run-through. First, don't leave Azure SQL Server open to the Internet, but remember to add your desktop's IP to the whitelist of IPs. Secondly, ensure that your Entra account is set as Admin in SQL Server or set up a Managed Indentify and add the MI as an admin user. Cheers and now I am...