

Guest Post
Dr. Damir Dobric is the CEO and Lead Architect of DAENET GmbH, a Microsoft Partner Advanced Specialized Partner specializing in cloud computing, IoT, and AI. He is a Microsoft Most Valuable Professional (MVP), a Regional Director, and a professor at the Frankfurt University of Applied Sciences. With a PhD in Computational Intelligence, he is an internationally recognized technology leader and influencer with a focus on emerging technologies and innovation. You can find more about him on LinkedIn: https://www.linkedin.com/in/damirdobric/. Thanks Damir!It seems that the majority of developers naturally believe this field of software development belongs to mathematics and Python developers, who originally started building the first solutions. However, .NET and C# provide a great foundation for building almost any kind of application on any platform in a highly professional way.
In this post, we will show, step by step, how to build GenAI solutions in C#/.NET that leverage SQL Server’s native vector search capabilities.
Introduction
In the space of Generative AI, large language models offer different types of functionalities, often categorized as Completion Models, Chat Completion Models, and Embedding Models.
Completion Models are widely known for generating text in response to a given prompt. They are designed to continue or complete a passage based on the initial input, making them suitable for various text-generation tasks.
Chat Completion Models are tailored for interactive conversations. These models excel in understanding and responding within the context of a dialogue, making them useful for chatbot applications, customer service, and virtual assistants.
Embedding Models, on the other hand, are not typically used for conversation or text generation. Instead, they generate high-dimensional vectors, known as embeddings, for any given chunk of text (such as a token, word, sentence, or paragraph). These embeddings, which capture the semantic meaning of text, are useful for tasks like similarity matching, clustering, and retrieval. In the space of large language models, an embedding vector generally spans 1536 dimensions, with each element representing a scalar value in the range of -1.0 to 1.0, for example:
[0.91, -0.73, 0.98, ..., -0.1]Each of these 1536 values encodes part of the semantic information for the text, making embedding models essential for various applications like search, recommendation systems, classification, clustering and many more.
To illustrate how this works, imagine you have an invoice document. After extracting the text from it, it might look like this:
Invoice Number: INV-0008
Date: 2024-11-02
Customer: Olivia King
Address: Ankara
Item Description Quantity Unit Price Total
------------------------------------------------------------
Keyboard 1 $180,02 $180,02
------------------------------------------------------------
Grand Total: $180,02On the other hand, you can have another type of document in some other language. For example, a delivery notes document in German might look like:
Lieferschein Number: DEL-0007
Date: 2024-11-02
Customer: Lily Brown
Delivery Address: Izmir
Delivery Item Quantity
----------------------------
Keyboard 1Moreover, you might have the same documents in various languages. The power of embeddings lies in their semantic representation as vectors. For example, you could extract shipment addresses from documents and use an embedding model to find all invoices from Germany.
Sure, you could traverse the documents, extract cities using RegEx, and then map them to their respective countries using a predefined list. But what if the city names are misspelled, or written in different languages? You’ll agree that this problem can be solved, but it would require using multiple techniques.
Embedding vectors, however, offer a much more straightforward solution. To demonstrate how semantics work, embeddings for cities like Paris, Lyon, Frankfurt, and Hamburg can be created and analyzed.
How to create the Embedding Vector?
To generate the embedding vector in C# you can, for example, use the OpenAI library and the following code snippet:
EmbeddingClient client = new(“The name of the model”, “The OpenAI Key”);
var res = await client.GenerateEmbeddingsAsync(new List<string>() { “Frankfurt” });
ReadOnlyMemory<float> embeddingVector = res.Value.First().ToFloats();Next, you calculate the cosine distance between each of these city embeddings and the embedding vector for countries like France and Germany (and other relevant countries).
Once calculated, you’ll get a result showing that Hamburg and Frankfurt have a higher semantic similarity (lower distance) with Germany, while Paris and Lyon show a higher similarity with France.
- Paris and Germany: Approximately 0.324
- Lyon and Germany: Approximately 0.249
- Hamburg and Germany: Approximately 0.536
- Frankfurt and Germany: Approximately 0.545
This approach remains effective even if the city names are slightly misspelt or variably formatted, thanks to the robustness of embeddings.
Imagine now that there are many entities for which such relationships need to be calculated. In such cases, it is clear that some kind of vector database could be used. Otherwise, it would be necessary to repeatedly calculate embeddings and similarity for a large number of documents, which is a very slow operation and could become quite costly. Keep in mind, that models are charged based on the number of tokens processed.
To demonstrate how to use SQL Server’s Native Vector Search, let’s imagine we have a large number of invoices and shipment documents (see examples above) in various languages. The goal is to classify all documents into two groups: Invoices and Shipments.
Let’s explore how to accomplish this using embeddings and SQL Server’s Native Vector Search. The idea of this example is to demonstrate how to use the new SQL Server vector type.
To accomplish this, all required native vector search T-SQL operations will be used. Follow next steps will be described:
- Create and insert vectors in the SQL table.
- Create and insert embeddings
- Read rows with vector column
- Looking for topmost similar vectors
- Classify documents
Create and insert vectors in the SQL table
This example demonstrates how to create vectors and insert them into the table. Note: Before running this example, make sure to create a table named Vectors under the schema test.
The table will be used in all other examples described in this post. The column VectorShort is used to store 3-dimensional demo vectors, while the column Vector is used to store real embedding vectors in 1536 dimensions.
CREATE TABLE test.Vectors
(
[Id] INT IDENTITY(1,1) NOT NULL,
[Text] NVARCHAR(MAX) NULL,
[VectorShort] VECTOR(3) NULL,
[Vector] VECTOR(1536) NULL
);The following method demonstrates how to insert a 3-dimensional vector into the table. The Vector type is a new T-SQL type introduced with the native vector search feature. It is internally stored in a binary format, which is undocumented. The new SQL vector type SqlVector can be created from the array of floats if using a Microsoft.Data.SqlClient Version >= 6.1.0:
sqlCmd.Parameters.AddWithValue("@Vector", new SqlVector<float>(new float[] { 7.01f, 7.02f, -7.03f }));
A JSON-formatted string of array of floats is supported for compatibility with the old driver Microsoft.Data.SqlClient: Version < 6.1.0. For example, the same cast in C# can be enforced implicitly using JsonSerializer:
sqlCmd.Parameters.AddWithValue("@Vector", JsonSerializer.Serialize(new float[] { 1.12f, 2.22f, 3.33f }));A similar, but not recommended way to set the value of SQL type Vector is to provide the vector as a JSON string directly:
sqlCmd.Parameters.AddWithValue("@Vector", ‘[1.12, 2.22, 3.33]’);A JSON array as a vector (for example, [1, 2, 3]) can also be casted to the Vector type using the following T-SQL statement:
CAST("[1, 2, 3]" AS Vector(3))The following code shows the full example that demonstrates how to insert vectors.
public static async Task CreateAndInsertVectorsAsync()
{
using (SqlConnection connection = new SqlConnection(_cConnStr))
{
// Vector is inserted in the column '[VectorShort] VECTOR(3) NULL'
string sql = $"INSERT INTO [test].[{_cTableName}] ([VectorShort]) VALUES (@Vector)";
SqlCommand command = new SqlCommand(sql, connection);
// Demonstrates how to use the new SqlVector<T> type to insert the vector.
command.Parameters.AddWithValue("@Vector", new SqlVector<float>(new float[] { 7.01f, 7.02f, -7.03f }));
// Alternative way how to add the vector parameter.
//var prm = command.Parameters.Add("@Vector", SqlDbTypeExtensions.Vector);
//prm.Value= new SqlVector<float>( new float[] { 7.01f, 7.02f, -7.03f });
// OBSOLETE:
// Supported for compatibility with the old driver Microsoft.Data.SqlClient: Version < 6.1.0.
// Insert vector as string. Note JSON array.
// command.Parameters.AddWithValue("@Vector", "[7.12, -2.22, 3.33]");
// Insert vector as JSON string serialized from the float array.
// command.Parameters.AddWithValue("@Vector", JsonSerializer.Serialize(new float[] { 4.12f, 22.22f, -3.33f }));
connection.Open();
var result = await command.ExecuteNonQueryAsync();
connection.Close();
}
}Create and insert embeddings
In real-life GenAI applications, vectors will most likely not be calculated directly within your code, as shown in previous example. Instead, embedding vectors will typically be generated by embedding models.
The following example illustrates a realistic scenario where a piece of text (in this case, “Welcome to Native Vector Search for SQL Server”) is used to create an embedding. The embedding is generated by invoking the GenerateEmbeddingsAsync method of the EmbeddingClient API.
The return value is an array of embeddings for the given array of input strings. With this method it is possible to create embeddings for multiple text blocks with the single REST call. Remember, the method GenerateEmbeddingsAsync invokes a corresponding REST service operation.
The desired array of floats for the first embedding can be obtained as:
res.Value.First().ToFloats().ToArray();Finally, the embedding can be inserted in the SQL table by using the following code snippet:
SqlCommand command = new SqlCommand($"INSERT INTO [test].[{Vectors}] ([Vector], [Text]) VALUES (@Vector, @Text)", connection);
command.Parameters.AddWithValue("@Vector", new SqlVector<float>(embeddingVector.ToArray()));
command.Parameters.AddWithValue("@Text", text);
The following method provides a complete code example for creating and inserting an embedding:
public static async Task CreateAndInsertEmbeddingAsync()
{
EmbeddingClient client = CreateEmbeddingClient();
// The text to be converted to a vector.
string text = "Native Vector Search for SQL Server";
// Generate the embedding vector by using OpenAI SDK
var res = await client.GenerateEmbeddingsAsync(new List<string>() { text });
OpenAIEmbedding embedding = res.Value.First();
ReadOnlyMemory<float> embeddingVector = embedding.ToFloats();
//
// Following code demonstrates how to insert the vector into the column Vector:
// [Vector] VECTOR(1536) NULL
using (SqlConnection connection = new SqlConnection(_cConnStr))
{
var id = Guid.NewGuid().ToString();
// Embedding is inserted in the column '[Vector] VECTOR(1536) NULL'
SqlCommand command = new SqlCommand($"INSERT INTO [test].[{_cTableName}] ([Vector], [Text]) VALUES (@Vector, @Text)", connection);
// Demonstrates how to use the new SqlVector<T> type to insert the vector.
command.Parameters.AddWithValue("@Vector", new SqlVector<float>(embeddingVector.ToArray()));
//
// OBSOLETE: Supported for compatibility with the old driver Microsoft.Data.SqlClient: Version < 6.1.0.
//command.Parameters.AddWithValue("@Vector", JsonSerializer.Serialize(embeddingVector.ToArray()));
command.Parameters.AddWithValue("@Text", text);
connection.Open();
var result = await command.ExecuteNonQueryAsync();
connection.Close();
}
}Reading vectors
Till now, we have seen how to create vectors and embeddings and how to store them in the table. To read the vector from the table, the following T-SQL command can be used:
Select TOP(100) VectorShort, Vector FROM [test].[Vectors]The vector column is read by using GetSqlVector:
var vectorEmbedding = reader.IsDBNull(reader.GetOrdinal("Vector")) ? SqlVector<float>.CreateNull(1536) :
reader.GetSqlVector<float>(reader.GetOrdinal("Vector"));The following method illustrates how to do this in C# by using a DataReader:
public static async Task ReadVectorsAsync()
{
List<(long Id, string VectorShort, string Vector, string Text)> rows = new();
using (SqlConnection connection = new SqlConnection(_cConnStr))
{
var id = Guid.NewGuid().ToString();
SqlCommand command = new SqlCommand($"Select TOP(100) * FROM [test].[{_cTableName}]", connection);
connection.Open();
using (SqlDataReader reader = await command.ExecuteReaderAsync())
{
while (await reader.ReadAsync())
{
//
// Demonstrates how to read the vector as a native type.
var vectorShort = reader.IsDBNull(reader.GetOrdinal("VectorShort")) ?
SqlVector<float>.CreateNull(3) :
reader.GetSqlVector<float>(reader.GetOrdinal("VectorShort"));
var vectorEmbedding = reader.IsDBNull(reader.GetOrdinal("Vector")) ?
SqlVector<float>.CreateNull(1536) :
reader.GetSqlVector<float>(reader.GetOrdinal("Vector"));
//
// Demonstrates ow to get a float array from the vector type.
float[] arrShort = vectorShort.Memory.ToArray();
float[] arrEmbedding = vectorEmbedding.Memory.ToArray();
(long Id, string VectorShort, string Vector, string Text) row = new(
reader.GetInt32(reader.GetOrdinal("Id")),
string.Join(", ", arrShort),
string.Join(", ", arrEmbedding).Substring(0, Math.Min(75, arrEmbedding.Length)) + " ... ",
// OBSOLETE: Supported for compatibility with the old driver Microsoft.Data.SqlClient: Version < 6.1.0.
//reader.IsDBNull(reader.GetOrdinal("VectorShort")) ? "-" : reader.GetString(reader.GetOrdinal("VectorShort")),
//reader.IsDBNull(reader.GetOrdinal("Vector")) ? "-" : reader.GetString(reader.GetOrdinal("Vector")).Substring(0, 20) + "...",
reader.IsDBNull(reader.GetOrdinal("Text")) ? "-" : reader.GetString(reader.GetOrdinal("Text"))
);
rows.Add(row);
}
}
connection.Close();
}
foreach (var row in rows)
{
Console.WriteLine($"{row.Id}, {row.VectorShort}, {row.Vector}, {row.Text}");
}
}Looking for topmost Similar vectors
In real-life applications, reading and analyzing vector data is not as often required as searching for similar vectors. For example, if it is required to find a similar text T’ of a text T, then the real power of Native Vector Search can be unleashed.
The T-SQL function used for this purpose is VECTOR_DISTANCE function.
VECTOR_DISTANCE('cosine', Vector1, Vector2)Currently, cosine, euclidean, and dot distances are supported. In GenAI, cosine distance is widely used. This function accepts two arguments of type Vector. If one of the arguments is a JSON string array, the cast must be performed on that argument.
VECTOR_DISTANCE('cosine', Vector1, Vector2)
The following T-SQL command demonstrates how to get the top 10 best matches for the vector @Embedding:
Select TOP(100) Id, Text, VECTOR_DISTANCE('cosine', @Embedding, VectorShort) AS Distance
FROM [test].[Vectors]"
Following method below shows the C# example, that illustrate how to implement the search for nearest embeddings (best matches). private static async Task<List<(long Id, double Distance, string Text)>> GetMatching(int howMany, string text)
{
List<(long Id, double Distance, string Text)> matchingRows = new();
EmbeddingClient client = CreateEmbeddingClient();
var res = await client.GenerateEmbeddingsAsync(new List<string>() { text });
ReadOnlyMemory<float> embeddingVector = res.Value.First().ToFloats();
using (SqlConnection connection = new SqlConnection(_cConnStr))
{
var id = Guid.NewGuid().ToString();
SqlCommand command = new SqlCommand($"Select TOP({howMany}) Id, Text, VECTOR_DISTANCE('cosine', @Embedding, Vector) AS Distance FROM [test].[{_cTableName}] ORDER BY DISTANCE", connection);
command.Parameters.AddWithValue("@Embedding", new SqlVector<float>(embeddingVector.ToArray()));
connection.Open();
using (SqlDataReader reader = await command.ExecuteReaderAsync())
{
while (await reader.ReadAsync())
{
(long Id, double distance, string Text) row = new(
reader.GetInt32(reader.GetOrdinal("Id")),
reader.IsDBNull(reader.GetOrdinal("Distance")) ? -999 : reader.GetDouble(reader.GetOrdinal("Distance")),
reader.IsDBNull(reader.GetOrdinal("Text")) ? "-" : reader.GetString(reader.GetOrdinal("Text"))
);
matchingRows.Add(row);
}
}
connection.Close();
}
return matchingRows;
}
The argument howMany specifies how many of the best matches (nearest vectors) should be returned. The second argument, text, is the text block used in the search. The method’s task is to find the text within the table Vectors that is semantically most similar to the given text.
Calculating the distance between multidimensional vectors is a computationally complex operation that incurs costs. Comparing a large number of multidimensional vectors is not an easy task for SQL server and the number of vectors in the table directly influences the application’s performance. The following diagram shows the execution time for returning the top 10 nearest vectors (most similar) of the given embedding vector.
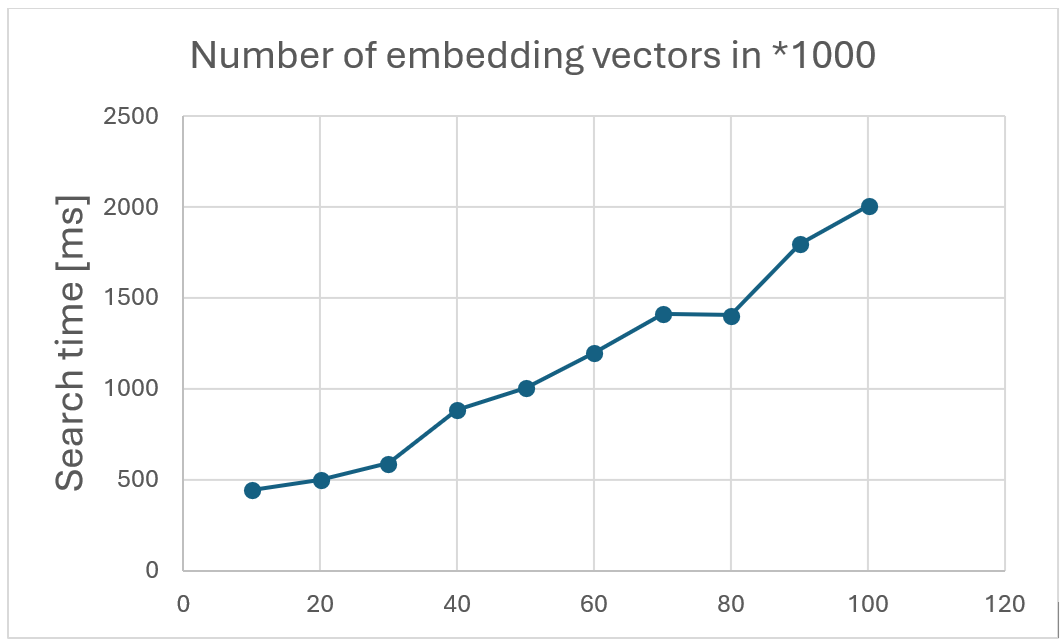
The T-SQL command used in this experiment, executed within C#, returns the Id and the distance. The experiment is executed on the more or less commodity SKU Azure SQL Server S1 20 DTU.
elect TOP({10}) Id, Text, VECTOR_DISTANCE('cosine', @Embedding, Vector) AS Distance
FROM [test].[{Vectors}] ORDER BY DISTANCE" Classify documents
To demonstrate the power of semantic matching, we will classify documents such as invoices and delivery documents, as previously described. Assuming all known documents of both types are already indexed (stored in the table along with their related embeddings), we will implement a semantic search to compare similarities.
For example, to classify invoices, we need to prepare a representative text block like “invoice total item” that best matches the semantics of the invoice document corpus stored in the SQL server. Alternatively, any other text that aligns with the semantic context of the stored invoice documents can be used. This text can also be in any other language.
Next, the method GetMatching should be invoked:
var invoicesEng = await GetMatching(20, "invoice total item")As a result, you will get a list of distance scores, which you should compare to all document types. If you compare the distance result of a given text (“invoice total item”), you will find out that all invoices have a distance score of approximately less than 0.5. All other document types will have a distance greater than 0.5. Please note, that this threshold does not have to exactly match your use case, but it should give you an idea of how the classification works.
The full example can be found in the sample repo: azure-sql-db-vector-search/DotNet/SqlClient/ReadMe.md at main · Azure-Samples/azure-sql-db-vector-search
All .NET samples related to SQL Server Native Vector Search: azure-sql-db-vector-search/DotNet at main · Azure-Samples/azure-sql-db-vector-search
0 comments