
Azure Synapse Analytics has a serverless SQL endpoint that enables you to read the files on Azure storage without pre-provisioning resources. You can leverage a serverless Synapse SQL endpoint to implement Polybase-like scenarios in Azure SQL Managed Instance.
The Polybase technology enables SQL Server and SQL DW to directly query a large amount of big data stored on the external storage. You can run standard SQL queries over CSV or Parquet files that are placed in Azure Storage without the need to load the data in SQL database tables. Polybase is currently not available in Azure SQL (database or managed instance). You can vote for this feature request on the Azure feedback site. If you need to load data from the Azure storage you need to use OPENROWSET(BULK) over Azure storage that works only with the Text/CSV format and can read a single file. As an alternative, you can load external data into a table using some external processes such as Azure Data Factory.
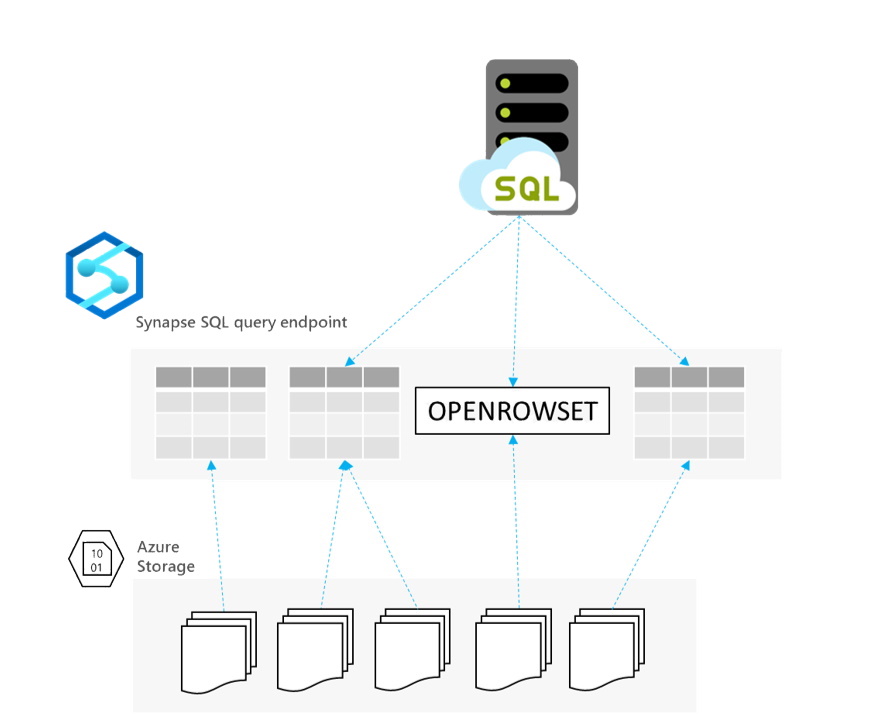
Azure Synapse Analytics is a big data analytics service that enables you to query and analyze data on the Azure Data Lake storage. With Synapse Analytics, you are getting one serverless SQL query endpoint that enables you to analyze your Azure data using T-SQL language. There is no upfront cost for this default serverless SQL endpoint. You are charged per each query depending on the amount of data that the query process (few dollars per TB processed). This looks like a perfect match for the Polybase-like scenarios.
Azure SQL managed instance enables you to run T-SQL queries on serverless Synapse SQL query endpoint using linked servers.
Since the serverless Synapse SQL query endpoint is a T-SQL compliant endpoint, you can create a linked server that references it and run the remote queries. In this article, you will see how to integrate these services.
How to prepare serverless SQL endpoint?
As a first step, you need to provision your Azure Azure Synapse Analytics workspace and set up some tables. If you don’t have Synapse Analytics workspace, you can easily deploy it using the Azure portal or this Deployment template. Synapse workspace automatically deploys one serverless Synapse SQL endpoint that is everything we need for this kind of integration. You don’t need any additional resources on the Synapse side.
You are not reserving resources or paying for the default Synapse Analytics configuration if you are not using it. The serverless Synapse SQL endpoint in the workspace is charged per query. If you are not executing the queries on a serverless SQL endpoint you are not paying anything. There is no additional fixed cost for this service.
With a serverless Synapse SQL endpoint we can query the files on Azure Data Lake storage using the OPENROWSET function:
select * from openrowset(bulk 'https://****.blob.core.windows.net/year=*/*/*.parquet', format='parquet') as cases
The OPENROWSET function very similar to the OPENROWSET function that you use in SQL Server and Azure SQL with some enhancements:
- The OPENROWSET function can read both CSV and Parquet files
- You can reference a set of files using wildcards (for example, *.parquet or /year=*/month=*/*.parquet)
- It can automatically infer the schema from the underlying CSV or Parquet files without a need to specify a format file
In addition to the OPENROWSET function, you can create an external table on a set of files and query them using a standard table interface. The following script creates one external table on a set of CSV files placed on the paths that match the pattern csv/population/year=*/month=* :
CREATE EXTERNAL TABLE csv.population ( country_code VARCHAR (5), country_name VARCHAR (100), year smallint, population bigint ) WITH ( LOCATION = 'csv/population/year=*/month=*/*.csv', DATA_SOURCE = AzureDataSource, FILE_FORMAT = QuotedCsvWithHeader );
The DATA_SOURCE contains a root URI of Azure Data Lake storage and authentication information.
External tables in Synapse SQL are very similar to the Polybase external tables that can be used in SQL Server. In the following sections, we will see how to leverage these external tables in Azure SQL Managed Instance.
How to use linked servers?
Linked servers in Managed Instance enable you to link remote SQL Server or Azure SQL endpoint and send remote queries or join remote tables with the local ones. Since the serverless SQL query endpoint in Azure Synapse Analytics is a T-SQL compatible query engine, you can reference it using a linked server:
EXEC master.dbo.sp_addlinkedserver
@server = N'SynapseSQL',@srvproduct=N'', @provider=N'SQLNCLI11',
@datasrc=N'mysynapseworkspace-ondemand.sql.azuresynapse.net',
@catalog=N'master';
EXEC master.dbo.sp_addlinkedsrvlogin @rmtsrvname=N'SynapseSQL', @useself=N'False',
@locallogin=NULL,
@rmtuser=N'<your user name here>',@rmtpassword='<your password>'
GO
EXEC master.dbo.sp_serveroption @server=N'SynapseSQL',
@optname=N'remote proc transaction promotion', @optvalue=N'false'
GO
EXEC master.dbo.sp_serveroption @server=N'SynapseSQL',
@optname=N'rpc', @optvalue=N'true'
GO
EXEC master.dbo.sp_serveroption @server=N'SynapseSQL',
@optname=N'rpc out', @optvalue=N'true'
GO
You can also use UI in SSMS to create this linked server and just these parameters. Once you setup your linked server to Synapse SQL default query endpoint, you can start reading external data on Azure Data Lake storage.
Querying Azure Data Lake
Managed Instance has the EXEC function that enables you to execute a T-SQL query on a remote linked server. We can use this function to send a query that will be executed on the serverless Synapse SQL endpoint and return the results. The following example returns the results of the remote query that is reading the file content from Azure Data Lake storage:
SET QUOTED_IDENTIFIER OFF
EXEC("
select *
from openrowset(bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.parquet',
format='parquet') as cases
") AT SynapseSQL
NOTE: Make sure that you have configured RPC options in the Linked server configuration using the `sp_serveroption` procedure in the setup script above. Otherwise, you will get the message like: Server ‘SynapseSQL’ is not configured for RPC. You need to set ‘rpc’ and ‘rpc out’ options to value true.
You can create complex reports and fetch the data using the linked server that references the SynapseSQL endpoint:
SET QUOTED_IDENTIFIER OFF
EXEC("
use SampleDB;
SELECT
nyc.filename() AS [filename],COUNT_BIG(*) AS [rows]
FROM
OPENROWSET(
BULK 'parquet/taxi/year=2017/month=9/*.parquet',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT='PARQUET'
) nyc
GROUP BY nyc.filename();
") AT SynapseSQL;
This query will read a set of parquet files and return the results to the client. Computation will be done on a remote SynapseSQL endpoint without affecting the workload on your Managed Instance.
NOTE: If you want to run this query, make sure that you have created a database named SampleDB on your serverless Synapse SQL endpoint and that you have created a data source ‘SqlOnDemandDemo’ using this setup script.
Querying remote external tables
If you have created an external table in a serverless Synapse SQL endpoint that references the files on Azure storage, you can use the 4-part name references in Managed Instance to read these files.
The following query uses a 4-part name reference to read data from an external table placed in SampleDb database on the linked server called SynapseSQL:
select * from SynapseSQL.SampleDB.csv.population
You can join this remote external table with the local database tables. The following example shows how to join Application.Countries database table that contains the latest recorded population per countries with an external table containing yearly population data to find the countries in Asia that has the highest population increase since 2014:
select TOP 5 FormalName,
Population2020 = LatestRecordedPopulation,
Population2014 = p.population,
[change %] = 1 - 1.0 * p.population/LatestRecordedPopulation
from Application.Countries c
join SynapseSQL.SampleDB.csv.population p
on c.CountryName = p.country_name
where p.year = 2015
and continent = 'Asia'
order by 1 - 1.0 * p.population/LatestRecordedPopulation desc
Managed Instance will join the rows from the database table Application.Countries with the content of CSV files referenced via Synapse SQL external table csv.population. You can also use 4-part name syntax to ingest external data into some local table.
In the following example I’m loading external data into a temp table:
select * into #t1 from SynapseSQL.SampleDB.csv.population; select * from #t1
4-part name references to the serverless Synapse SQL tables enable you to fully virtualize your remote tables, query external data, join them with the local database tables, or load external data into the local tables.
Cleanup
You can remove the linked server that references a serverless Synapse SQL endpoint using the following script:
EXEC sp_dropserver @server = N'SynapseSQL', @droplogins = 'droplogins'
Conclusion
A serverless SQL endpoint in Azure Synapse Analytics might be a nice workaround if you need to implement a Polybase-like scenario in Azure SQL managed instance. This endpoint enables you to query and analyze a large amount of externally stored data. Synapse SQL endpoint is not a replacement for Polybase and does not have the same features. However, it can help you to implement the queries that need to access external data.
0 comments