
Introduction
Storing and retrieving data from JSON fragments is a common need in many application scenarios, like IoT solutions or microservice-based architectures. You can persist these fragments can be in a variety of data stores, from blob or file shares, to relational and non-relational databases, and there’s a long standing debate in the industry on what’s the database technology that fits “better” for this task.
Azure SQL Database offers several options for parsing, transforming and querying JSON data, and this article doesn’t pretend to provide a definitive answer to that debate, but rather to explore these options for common scenarios like data loading and retrieving, and benchmarking results to provide a clear indication of how Azure SQL Database will perform manipulating JSON data.
Our test bench
To reproduce a realistic scenario, we started from a JSON fragment representing a real telemetry message from a machine in a factory floor containing ~60 attributes, for an average 1.6KB size:

We then identified two options for table structures where persist these JSON messages and execute various tests against.
First one is storing plain JSON fragments in a nvarchar(max) column, which is an approach that some customers that don’t want to deal with a relational model tend to adopt:

The second approach we wanted to test is instead “shredding” all attributes of the JSON document into specific columns in a relational table:

Loading data
First scenario we want to test is how efficiently we can load one or many documents generated by an application into these two table structures. In our tests, in order to eliminate all variability related to application implementation and potential latency in database interactions, we dynamically generate various row batches to insert (1, 1000, 10000, 100000, 3M rows) on the server-side, with some random attribute values generated while inserting into our target table through an INSERT…SELECT statement like this:
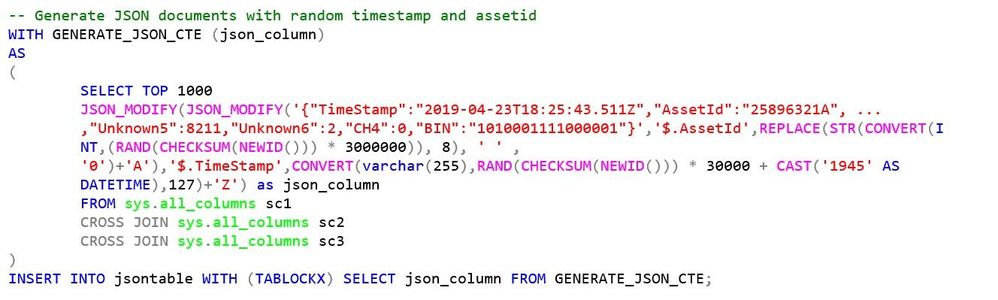
For the schematized table we’re taking a similar approach to generate our synthetic rowset, but we’re using the OPENJSON function instead to automatically shred all JSON attributes into table columns while again inserting all rows with an INSERT…SELECT statement:

For each table, we then measure loading these row batches with different indexing strategies:
- Heap (no clustered index)
- Clustered index
- Clustered Columnstore (trickle, or individual inserts we wrapped in a BEGIN/COMMIT )
- Clustered Columnstore (bulk inserts)
For #3, it’s important to mention the importance of batching multiple individual insert operations and wrap them into an explicit transaction to mitigate both latency between application and database layer, and latency introduced by individual transaction log writes typical of explicit transactions.
This topic has been extensively covered in another article comparing and contrasting all batching options. Having multiple writers can potentially create some concurrency issues that varies depending on the combination of indexing and rows already present in the table: this article is describing in details impact on concurrency and performance for various options.
For Columnstore indexes, for example, each thread loads data exclusively into each rowset by taking a X lock on the rowset, allowing parallel data load with concurrent data load sessions. It’s important to mention though, that in typical IoT scenarios like the one we mentioned, events and messages are typically sent to an event store like Azure IoT Hub or Kafka, and then processed by a relatively small number of event processors that will execute data loading, so concurrency can be less of an issue.
We then repeated our data loading tests with different Azure SQL Database instance sizes, namely Business Critical 2 vCores, 16 vCores or 40 vCores, to verify if increasing “Max log rate” limit for the instance is impacting data loading performance.
Loading times for all options are represented in the following matrix:

Cells with green background represents best loading times for different batch sizes in each scale tier. As we can see, bulk loading plain JSON into a Clustered Columnstore index is around 3x faster than the schematized approach we tested, across pretty much all batch sizes.
Comparing various indexing strategies on the two data models instead, differences in bulk loading on an heap, clustered index on row store or clustered columnstore is much more limited, in the range of 20-30% difference.
It’s also interesting to see the level of compression that can be achieved for both plain JSON and for the schematized approach by leveraging Clustered Columnstore (from ~5GB down to 204MB and 122MB respectively). In IoT scenarios where you have to store billions of messages per month, this can be a significant cost saving compared to many other database technologies.
Scaling from 2 vCores to 40 vCores is only providing ~20% performance improvement as, for this particular test, we’re executing bulk loading on a single connection and we’re not maxing out resource consumption in any particular area (CPU, IO or memory). If we would execute multiple bulk loading operation in parallel across many connections, we would clearly see a different picture here.
Querying data
The other main scenario that we want to evaluate during this test is, of course, retrieving data from various options of table schema and indexing approaches.
Query patterns that we want to test for all combinations of schemas and indexes are:

First round of tests are executed against the two table structures (plain JSON and schematized) with a Clustered Columnstore index built on both. Results are clearly demonstrating that (not surprisingly), on the query side, schematized table is outperforming the other option by factors that span from 4x to 300x, depending on query patterns:

It’s important to mention that we’re executing this test with a quite limited number of rows for a typical Columnstore scenario and only measuring pure data retrieval times. If we’d need to scale into billions of messages to store, one viable improvement to speed up retrieval can be to introduce table partitioning to support query patterns like time range queries. In addition to intrinsic partitioning provided by rowgroups, table partitioning would help database engine to filter out partitions not containing relevant data.
Other viable options
Depending on your specific workload and priorities, there are other options around these two data models that you may want to consider optimizing performance for your needs.
When storing plain JSON in your table, you can still benefit from Azure SQL Database’s manipulating functions to optimize specific query patterns like key lookups or range queries. You can, for example, create some computed columns starting from JSON attributes that will be used in query predicates or aggregations, like:

Ideally, you would want to build indexes on those computed columns to speed up those query patterns. Unfortunately, as of today, computed columns cannot coexist with Columnstore Indexes so, in order to go down this path, you would have to move back to a more traditional indexing approach based on clustered and non-clustered indexes, like shown here:

A side benefit of such an approach, is that it would significantly simplify your T-SQL syntax and make queries more readable with a structure like this:

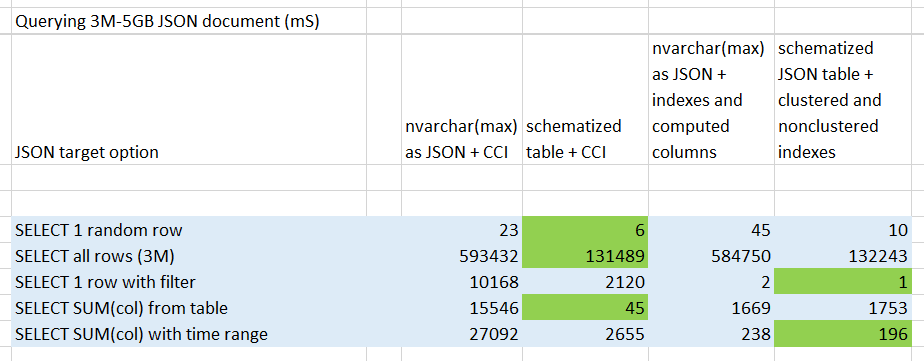
From a pure performance perspective, as expected this indexing strategy is providing best results for key lookup and range queries when compared to previous results, although is trading off benefits of compression in storage space as pointed out previously:
Conclusions
Azure SQL Database provides several options for storing and querying JSON data produced by IoT devices or distributed microservices.
These options are both at schema design and at the indexing strategy level, and provide flexibility covering various usage patterns and requirements, providing developers with techniques to optimize their solutions for write-intensive, read-intensive, or even storage-intensive workloads:

Storing plain JSON in a text column provides best data loading performance and, when combined with a Clustered Columnstore index, very good compression and storage optimization.
Bulk loading JSON data through OPENJSON into a relational schema is slightly less efficient, but it will reduce even further space occupied in conjunction with CCI. It will also give you best performance when querying data in pretty much all query patterns you may want to use.
When point lookup and range queries are predominant in your workload, adopting an indexing strategy based on more conventional clustered and non-clustered indexes can provide very good performance at the cost of more storage space used.
0 comments