

Data API builder exposes REST endpoints for MySQL, PostgreSQL, Cosmos DB, SQL Server and Azure SQL. REST (Representational State Transfer) endpoints allow developers to easily query a single table, view or stored procedure. However, Data API builder also exposes GraphQL endpoints. Like REST, GraphQL returns data, but unlike REST, GraphQL can return data from multiple related tables in nested results. This includes one-to-many, many-to-many, and many-to-one relationships.
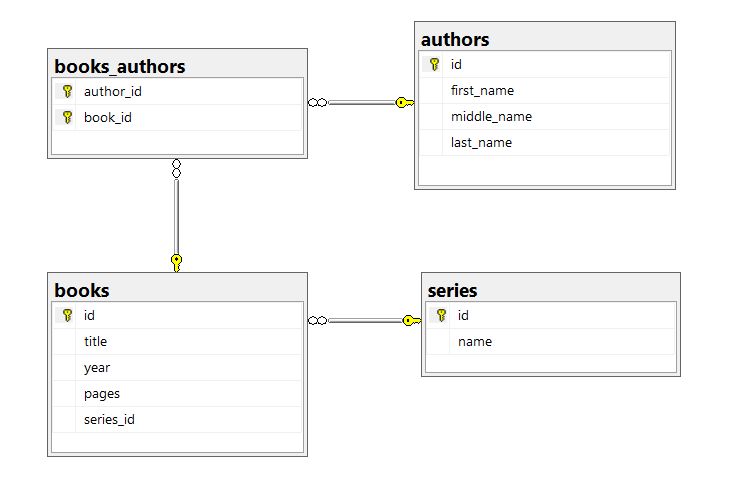
This diagram illustrates a simple database that uses all three relationships. Data API builder supports each, but to do so it is required that the configuration file describe bot the table and the relationship. Developers can edit the JSON fire directly or use the CLI to update the JSON programmatically. Let’s focus on the CLI approach as there’s no question it is the easiest approach. Interacting JSON is simple but very prone to error. With the CLI, you don’t need to know the JSON schema. And with the CLI you don’t need to remember every command and closing brace.
Adding tables
The CLI (dab) has an “add” command we use to add tables, views, or stored procedures to the configuration file. With it, we can configure the entity name, schema, and authentication. As of this article the supported flags and arguments are as follows:
| -s, –source | Required. Name of the source database object. |
| –permissions | Required. Permissions required to access the source table or container. |
| –source.type | Type of the database object. Must be one of: [table, view, stored-procedure] |
| –source.params | Dictionary of parameters and their values for Source object. “param1:val1,param2:value2,..” |
| –source.key-fields | The field(s) to be used as primary keys. |
| –rest | Route for rest API. |
| –rest.methods | HTTP actions to be supported for stored procedure. Specify the actions as a comma separated list. Valid HTTP actions are: [GET, POST, PUT, PATCH, DELETE] |
| –graphql | Type of GraphQL. |
| –graphql.operation | GraphQL operation to be supported for stored procedure. Valid operations are: [Query, Mutation] |
| –fields.include | Fields that are allowed access to permission. |
| –fields.exclude | Fields that are excluded from the action lists. |
| –policy-request | Specify the rule to be checked before sending any request to the database. |
| –policy-database | Specify an OData style filter rule that will be injected in the query sent to the database. |
| -c, –config | Path to config file. Defaults to ‘dab-config.json’ unless ‘dab-config.<DAB_ENVIRONMENT>.json’ exists, where DAB_ENVIRONMENT is an environment variable. |
| –help | Display this help screen. |
| –version | Display version information. |
| Entity (pos. 0) | Name of the entity. |
Minimal syntax
It doesn’t take much to add a table to the Data API builder configuration file. The basics are its name, table schema including keys, and permissions. Here’s how we add the authors table.
dab add "authors" --source "[dbo].[authors]" --source.type "table" --source.key-fields "id" --permissions "anonymous:*"The resulting configuration looks like this:
"entities": {
"authors": {
"source": {
"object": "[dbo].[authors]",
"type": "table",
"key-fields": [ "id" ]
},
"graphql": {
"enabled": true,
"type": {
"singular": "authors",
"plural": "authors"
}
},
"rest": { "enabled": true },
"permissions": [
{
"role": "anonymous",
"actions": [ { "action": "*" } ]
}
]
}
}That’s a lot for a little. And more could be added; but for now, let’s make this simple. It’s worth pointing out that regardless of the backend database, the Data API builder configuration syntax is identical – you don’t need to do anything special to account for your backend data source. So far we’ve added the authors table, now let’s add series, books, and the cross-reference table: books_authors.
dab add "authors" --source "[dbo].[authors]" --source.type "table" --source.key-fields "id" --permissions "anonymous:*"
dab add "series" --source "[dbo].[series]" --source.type "table" --source.key-fields "id" --permissions "anonymous:*"
dab add "books" --source "[dbo].[books]" --source.type "table" --source.key-fields "id" --permissions "anonymous:*"
dab add "books_authors" --source "[dbo].[books_authors]" --source.type "table" --source.key-fields "book_id,author_id" --permissions "anonymous:*" --graphql falseIn the sample above, each table uses the same CLI syntax to get into the configuration file. Run this twice and you will get an error that the entities are already defined. If you want to modify an existing entity, use update instead of add.
Hiding tables
However, if you look closely the last line is different. There is one extra flag --graphql false added to the books_authors table. Why? Setting --graphqlto false tells the Data API builder engine to hide the table from the graph schema. Why? The graph schema tells the consumer what entities it can query – including intellisense in debugging tools – and there is no practical reason to encourage consumers to directly query a cross-reference table. To be clear, this doesn’t mean we can’t use hidden entities in relationship definitions. What it means is that our graph schema is nice and clean.
A note about relationships in Data API builder
A part of you may wonder, why do I need to define my relationships when they are already defined in my database? That’s a fair question. First, let me remind you that a RDMS supports relationships but does not require them. That is to say, relationships in a database like SQL Server help ensure data integrity, but do not actually come into play when you perform JOIN statements in your query. The practical reason for relationship definitions in Data API builder is so you can customize them, naming them how you want them to appear in your queries and limit relationships you don’t want to present.
One-to-many & many-to-one relationships
There is one series with many books in it. For example, Isaac Asimov’s Foundation series has some seven books from Foundation all thew way to Forward the Foundation. This, and its corollary many-to-one are the simplest relationships, showing up in almost every RDBM schema.
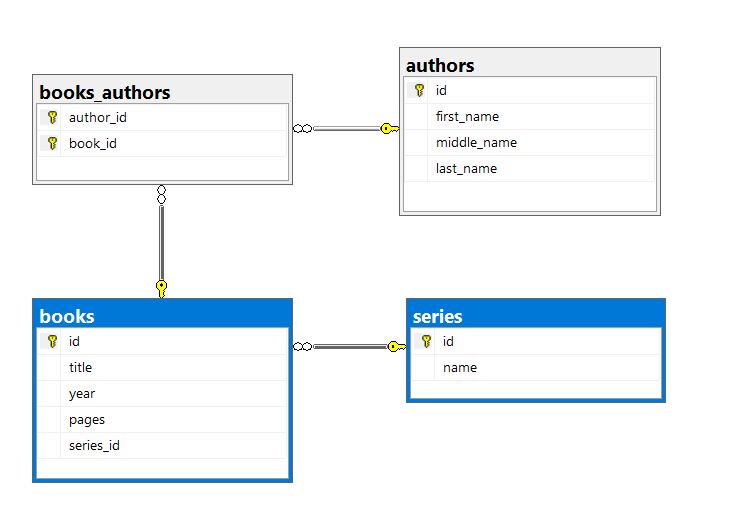
The image above highlights the series to book relationship. This is a one-to-many relationship when we consider series-to-books. It is a many-to-one relationship when we consider books-to-series. Let’s see what is required for us to add this to the Data API builder configuration file using the CLI.
dab update "series" --relationship "books" --target.entity "series" --cardinality many --relationship.fields "id:series_id"dab update "books" --relationship "series" --target.entity "series" --cardinality one --relationship.fields "series_id:id"The first defines series-to-books and the second defines books-to-series. In both cases we identify the primary key and the foreign keys relevant to the relationship. When the result of the relationship (with the target table) is zero or more, we set the cardinality to many. When the result of the relationship (with the target table) is zero or one, we set the cardinality to one. Relationships, don’t forget, are exposed through Data API builder GraphQL endpoints. Relationship definitions do not impact REST endpoints.
"relationships": {
"books": {
"cardinality": "many",
"target.entity": "series",
"source.fields": [ "id" ],
"target.fields": [ "series_id" ]
}
}The relationship section of the entity is added automatically, perfectly formatted and ready for the Data API builder engine to start. If you look at it, it’s pretty simple. That said, notice how compound keys are supported by arrays, this and other features make Data API builder perfect for even the most complicated data schema.
Many-to-many
What makes many-to-many relationships tricky is that it requires a third table, usually referred to as a cross-reference or linking table. They typically have the key(s) for each of the two outside tables, and sometimes columns for data to describe relationship-specific data.
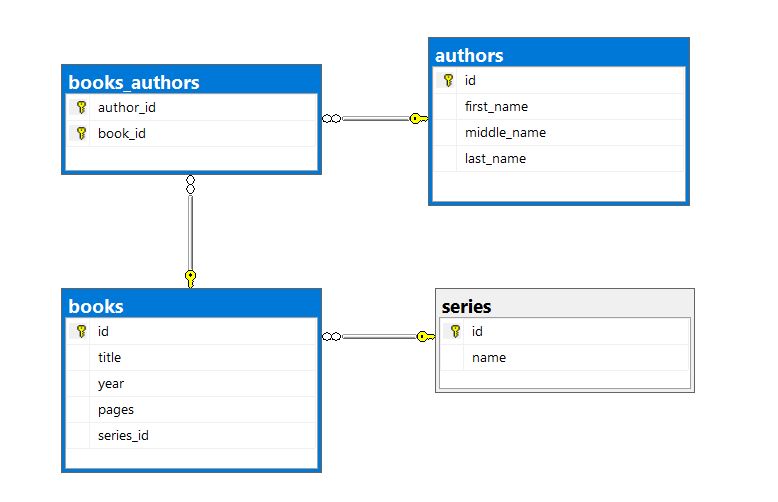
In the case of a relational database, the resulting SQL required to query this relationship would have a minimum of two JOIN statements to connect the tables. Data API builder does this for you. All you need to do is to ensure the linking table is already referenced in the configuration file. However, as we noted above, the linking table entities never need to be exposed directly through the Grap schema.
For our database a book can be written by many authors. At the same time, an author can write several books. That’s the classic scenario for a many-to-many relationship. Here books_authors is the cross-reference table holding the primary key of the author and the primary key of the book. This is our linking table and what we include in our CLI command to build out the configuration.
dab update "books" --relationship "authors" --target.entity "authors" --cardinality many --linking.object "dbo.books_authors" --linking.source.fields "book_id" --linking.target.fields "author_id"
dab update "authors" --relationship "books" --target.entity "books" --cardinality many --linking.object "dbo.books_authors" --linking.source.fields "author_id" --linking.target.fields "book_id"A few things are removed, and a few things are added. Look at the syntax closely and the --relationship:fields we saw in our previous example has been removed. That’s because the Data API builder engine can infer those with other data you have already provided. Also notice that the linking table is listed specifically. This entity must already exist in the configuration file, but, as we mentioned above, it does not have to be exposed explicitly through the GraphQL endpoint.
Intuitive & readable
Without a doubt, this short syntax is simpler than the SQL required to execute it. But let’s take a minute to step through a few important parts. Note the name of the first relationship is “authors” and the second is “books“. These appear in the graph query, so that books { authors } and authors { books } keeps your query both intuitive and readable.
"authors": {
"cardinality": "many",
"target.entity": "authors",
"linking.object": "dbo.books_authors",
"linking.source.fields": [ "book_id" ],
"linking.target.fields": [ "author_id" ]
}The configuration for many-to-many relationships is simple enough, the CLI is your best bet to get it right the first time. Can you add it manually into the JSON? Yes. Can you edit the JSON after running the CLI? Yes. The CLI is a helper, not a constraint. You do you.
GraphQL queries
query {
series {
items {
name
books {
items {
title
}
}
}
}
books {
items {
title
series {
name
}
}
}
}This query exercises both the series one-to-many relationship to books and the books many-to-one relationship to series. Look and how clean the Data API builder’s endpoint implementations are and how simple it can be for developers to access complex data. Now, let’s query the many-to-many relationship between authors and books.
query {
series {
items {
name
books {
items {
title
pages
authors {
items {
first_name
last_name
}
}
}
}
}
}
}Wrapping up
Using the Data Api builder CLI to constructor a configuration file that describes your tables, views, and stored procedures it all you need to get REST and GraphQL endpoints running against your MySQL, Cosmos DB, Progres and Azure SQL databases. But with a little more, you can quite easily define relationships between entities and make your GraphQL queries rich and capable.
0 comments