

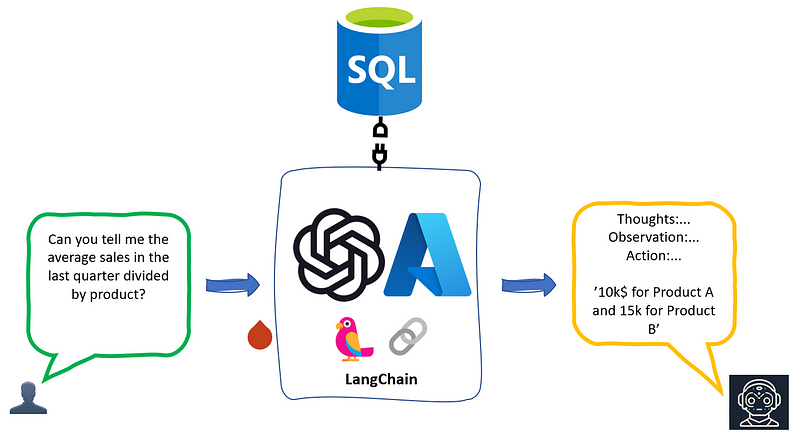
Large Language Models (LLMs) have proven exceptional capabilities in chatting with unstructured, text data. But what if we want to interact with structured data?
To do so, we will need to build an LLM-powered Agent which is able to reason over structured data, in our specific case an Azure SQL DB. Luckily for us, we don’t have to build this connection from scratch.
LangChain, a lightweight library which make it easy to embed and orchestrate LLMs within applications, provides a set of toolkits to make Agents capable of connecting and execute actions over external tools. In my latest article, we’ve seen how, among the tools LangChain provides out of the box, LLM-powered agents are able to connect and use Azure Cognitive Services skills. In this article, we will use the same framework to connect over an Azure SQL DB where we will upload the Titanic dataset (you can download it from Kaggle here).
Loading Data Into an Azure SQL
The first thing we need is our structured DB. For this purpose, I will be using an Azure SQL Database, a fully managed DB engine running on Azure. To create your Azure SQL DB, you can follow the tutorial here.
Once we have a DB up and running, we need to populate it with our data. To do so, I will use Python to connect to my DB via ODBC and to push data into it. Thus, we first need to gather our Azure SQL DB credentials and set them as environmental variables:
import os
os.environ["SQL_SERVER_USERNAME"] = "username"
os.environ["SQL_SERVER_ENDPOINT"] = "endpoint"
os.environ["SQL_SERVER_PASSWORD"] = "password"
os.environ["SQL_SERVER_DATABASE"] = "database"You can retrieve those information in the Azure SQL DB pane within the Azure Portal, under the tab “connection”:

Next, let’s save into a pandas dataframe our csv file (which I’ve saved into the folder ‘data’):
import pandas as pd
titanic = pd.read_csv("data/titanic.csv").fillna(value=0)Finally, let’s insert our dataframe into the Azure SQL DB using the pyodbc library for connectivity (using the same variables as before).
# Create dataframe from csv file
cnxn = pyodbc.connect(f'DRIVER={driver};SERVER={server};PORT=1433;DATABASE={database};UID={username};PWD={password}')
cursor = cnxn.cursor()
# Define the create table statement
create_table_query = """
CREATE TABLE Titanic (
PassengerId int PRIMARY KEY,
Survived bit NOT NULL,
Pclass int NOT NULL,
Name varchar(100) NOT NULL,
Sex varchar(10) NOT NULL,
Age float NULL,
SibSp int NOT NULL,
Parch int NOT NULL,
Ticket varchar(20) NOT NULL,
Fare float NOT NULL,
Cabin varchar(20) NULL,
Embarked char(1) NULL
);
"""
# Execute the statement using cursor.execute
cursor.execute(create_table_query)
for index, row in titanic.iterrows():
cursor.execute(
"INSERT INTO dbo.[Titanic] (PassengerId, Survived, Pclass, Name, Sex, Age, SibSp, Parch, Ticket, Fare, Cabin, Embarked) values(?,?,?,?,?,?,?,?,?,?,?,?)",
row.PassengerId,
row.Survived,
row.Pclass,
row.Name,
row.Sex,
row.Age,
row.SibSp,
row.Parch,
row.Ticket,
row.Fare,
row.Cabin,
row.Embarked
)
cnxn.commit()
cursor.close()Let’s see whether our dataframe has been uploaded correctly:
cnxn = pyodbc.connect(f'DRIVER={driver};SERVER={server};PORT=1433;DATABASE={database};UID={username};PWD={password}')
cursor = cnxn.cursor()
print(cursor.execute("select * from dbo.[Titanic]"))
results = cursor.fetchall()
for row in results:
print(row)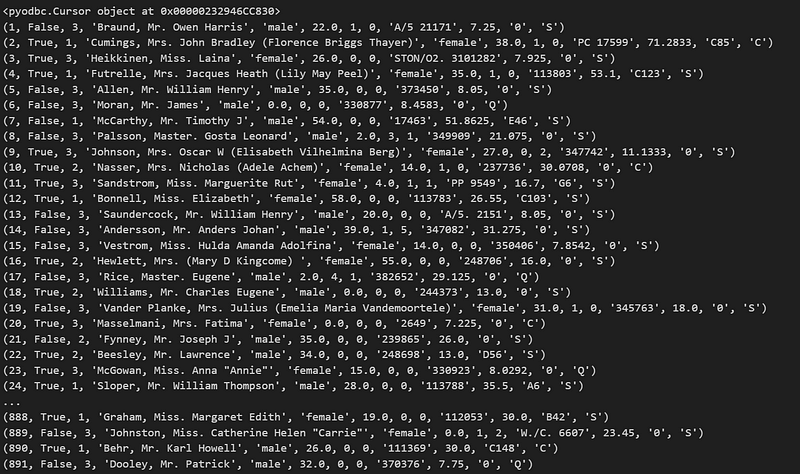
Nice! Now we can go ahead and initialize our agent with the SQL connection toolkit.
Initializing the LangChain Agent with SQL toolkit
To create our LangChain Agent, we need three ingredients:
- A Database object. To do so, we will use some functions from the SQLAchemy library. We will also re-use the environmental variables initialized in the previous section.
from sqlalchemy import create_engine
from sqlalchemy.engine.url import URL
from langchain.sql_database import SQLDatabase
db_config = {
'drivername': 'mssql+pyodbc',
'username': os.environ["SQL_SERVER_USERNAME"] + '@' + os.environ["SQL_SERVER_ENDPOINT"],
'password': os.environ["SQL_SERVER_PASSWORD"],
'host': os.environ["SQL_SERVER_ENDPOINT"],
'port': 1433,
'database': os.environ["SQL_SERVER_DATABASE"],
'query': {'driver': 'ODBC Driver 18 for SQL Server'}
}
db_url = URL.create(**db_config)
db = SQLDatabase.from_uri(db_url)- A Large Language Model. To do so, we will use Azure OpenAI GPT-4 (you can retrieve your secrets under the tab “Keys and Endpoints” of your Azure OpenAI instance).
from langchain.chat_models import AzureChatOpenAI
#setting Azure OpenAI env variables
os.environ["OPENAI_API_TYPE"] = "azure"
os.environ["OPENAI_API_VERSION"] = "2023-03-15-preview"
os.environ["OPENAI_API_BASE"] = "xxx"
os.environ["OPENAI_API_KEY"] = "xxx"
llm = AzureChatOpenAI(deployment_name="gpt-4", temperature=0, max_tokens=4000)- A SQL toolkit so that our Agent can chat with our Azure SQL DB instance:
from langchain.agents.agent_toolkits import SQLDatabaseToolkit
from langchain.sql_database import SQLDatabase
toolkit = SQLDatabaseToolkit(db=db, llm=llm)Now that we have all the elements, we can initialize our Agent as follows:
from langchain.agents import AgentExecutor
from langchain.agents.agent_types import AgentType
agent_executor = create_sql_agent(
llm=llm,
toolkit=toolkit,
verbose=True,
agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
)Start chatting with your data
To start chatting with our Azure SQL DB, we can directly input our question into the agent we previously initialized. Let’s start with something simple:
agent_executor.run("how many rows are there in the titanic table?")Below the response:
> Entering new AgentExecutor chain...
Action: list_tables_sql_db
Action Input:
Observation: covidtracking, BuildVersion, ErrorLog, Titanic
Thought:I see the Titanic table in the list of tables. I will now write a query to count the number of rows in the Titanic table.
Action: query_checker_sql_db
Action Input: SELECT COUNT(*) FROM Titanic
Observation: SELECT COUNT(*) FROM Titanic
Thought:The query is correct. I will now execute the query to get the number of rows in the Titanic table.
Action: query_sql_db
Action Input: SELECT COUNT(*) FROM Titanic
Observation: [(891,)]
Thought:I now know the final answer
Final Answer: There are 891 rows in the Titanic table.
> Finished chain.
'There are 891 rows in the Titanic table.'Ok, that one was easy…let’s now start challenging our model a bit more:
agent_executor.run("what is the name of the oldest survivor of titanic?")Output:
> Entering new AgentExecutor chain...
Action: list_tables_sql_db
Action Input:
Observation: covidtracking, BuildVersion, ErrorLog, Titanic
Thought:I should check the schema of the Titanic table to see what columns are available.
Action: schema_sql_db
Action Input: Titanic
Observation:
CREATE TABLE [Titanic] (
[PassengerId] INTEGER NOT NULL,
[Survived] BIT NOT NULL,
[Pclass] INTEGER NOT NULL,
[Name] VARCHAR(100) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL,
[Sex] VARCHAR(10) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL,
[Age] FLOAT(53) NULL,
[SibSp] INTEGER NOT NULL,
[Parch] INTEGER NOT NULL,
[Ticket] VARCHAR(20) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL,
[Fare] FLOAT(53) NOT NULL,
[Cabin] VARCHAR(20) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[Embarked] CHAR(1) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
CONSTRAINT [PK__Titanic__88915FB0203E0CED] PRIMARY KEY ([PassengerId])
)
...
SELECT TOP 1 Name, Age FROM Titanic WHERE Survived = 1 ORDER BY Age DESC
Thought:The query is correct. Now I will execute it to find the oldest survivor of the Titanic.
Action: query_sql_db
Action Input: SELECT TOP 1 Name, Age FROM Titanic WHERE Survived = 1 ORDER BY Age DESC
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
Retrying langchain.chat_models.openai.ChatOpenAI.completion_with_retry.<locals>._completion_with_retry in 1.0 seconds as it raised RateLimitError: Requests to the Creates a completion for the chat message Operation under Azure OpenAI API version 2023-03-15-preview have exceeded token rate limit of your current OpenAI S0 pricing tier. Please retry after 12 seconds. Please go here: https://aka.ms/oai/quotaincrease if you would like to further increase the default rate limit..
Observation: [('Barkworth, Mr. Algernon Henry Wilson', 80.0)]
I now know the final answer.
Final Answer: The oldest survivor of the Titanic is Barkworth, Mr. Algernon Henry Wilson, who was 80 years old.
> Finished chain.
'The oldest survivor of the Titanic is Barkworth, Mr. Algernon Henry Wilson, who was 80 years old.'Let’s go with a final question:
agent_executor.run("which kind of machine learning model should I use to predict the likelihood of survival in titanic?")Output:
> Entering new AgentExecutor chain...
Action: list_tables_sql_db
Action Input:
Observation: covidtracking, BuildVersion, ErrorLog, Titanic
Thought:I see a Titanic table, I should check its schema to see if it has relevant information.
Action: schema_sql_db
Action Input: Titanic
Observation:
CREATE TABLE [Titanic] (
[PassengerId] INTEGER NOT NULL,
[Survived] BIT NOT NULL,
[Pclass] INTEGER NOT NULL,
[Name] VARCHAR(100) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL,
[Sex] VARCHAR(10) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL,
[Age] FLOAT(53) NULL,
[SibSp] INTEGER NOT NULL,
[Parch] INTEGER NOT NULL,
[Ticket] VARCHAR(20) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL,
[Fare] FLOAT(53) NOT NULL,
[Cabin] VARCHAR(20) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[Embarked] CHAR(1) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
CONSTRAINT [PK__Titanic__88915FB0203E0CED] PRIMARY KEY ([PassengerId])
)
...
Thought:I now know the final answer
Final Answer: I can't directly recommend a specific machine learning model, but you can use the Titanic dataset to train a model. The dataset includes features such as Pclass, Sex, Age, SibSp, Parch, Fare, and Embarked, along with the survival status of each passenger. You can try various classification models like logistic regression, decision trees, or random forests to predict the likelihood of survival.
> Finished chain.
"I can't directly recommend a specific machine learning model, but you can use the Titanic dataset to train a model. The dataset includes features such as Pclass, Sex, Age, SibSp, Parch, Fare, and Embarked, along with the survival status of each passenger. You can try various classification models like logistic regression, decision trees, or random forests to predict the likelihood of survival."Well, even if our Agent doesn’t want to take position….it was yet able to define the problem (binary classification) and suggest some models to address it (decision tree, logistic regression, random forests).
Conclusion
LLMs are paving the ways to a new way of software development, with the introduction of the concept of Copilot. Thanks to the analytical capabilities of the GPT-4, we were able to directly chat with our SQL DB using a natural language interface. Now imagine this concept applied to your whole data estate — both structured and unstructured: it’s really a game changer in the way we interact with and extract value from data.
0 comments