
Guest Post
Saverio Lorenzini is a Senior Cloud Solution Architect with over 25 years of expertise in SQL Server. He specializes in migrations, performance tuning, and optimization. This fantastic work that shows a very practical use of AI to help DBAs and DEVs to create better and smarted SQL code, was presented by the author at the Microsoft TechConnect internal conference in Seattle, February 2025, and Saverio was so kind to also agree to publish his work here. Thanks Saverio!This article presents an AI-powered approach to automating SQL Server code analysis and refactoring. The system intelligently identifies inefficiencies and common T-SQL anti-patterns, applying best practices through a set of formalized coding rules, using prompt-driven instructions. It not only automatically rewrites problematic and inefficient code but also delivers contextual recommendations to improve quality, security, and maintainability.
Designed to address real-world use cases, this methodology enables organizations to modernize and optimize their SQL workloads more efficiently, accelerating migrations and reducing manual effort in scenarios with large SQL codebases.
The article outlines the architecture of the AI-driven SQL refactoring system and the mechanisms through which it provides intelligent code transformation, with demonstrations highlighting the benefits. The explained technique is a tangible advancement in SQL Server application development and maintenance, reducing manual effort and improving code quality and performance. Sample code is available on GitHub. Link at the end of the article.

Improving T-SQL code via AI
The key point of the proposed approach is to identify specific cases of suboptimal SQL code and instruct the AI model on how to refactor them more effectively. The following sections describe key categories of problematic SQL coding patterns that the AI-driven refactoring solution targets.
- T-SQL Anti-Patterns: T-SQL anti-patterns are common coding practices that seem reasonable but lead to performance degradation, poor maintainability, or incorrect results. An example is using SELECT * expressions.
- Non-SARGable Queries: Non-SARGable (Non-Search ARGument ABLE) queries cannot effectively use indexes, leading to slower performance and higher resource consumption. Examples include using functions or operators on indexed columns (e.g., WHERE YEAR(OrderDate) = 2022) which prevent index usage and result in full scans.
- Not Secure Queries: Queries that expose databases to security vulnerabilities, such as SQL injection, typically due to improper input handling or unsafe query construction. Example: Directly embedding user input into queries without proper validation (e.g.: SELECT * FROM Users WHERE Username = ‘” + user_input + “‘).
- Inefficient Queries: Queries that consume excessive CPU, memory, or I/O resources, due to design issues such as unnecessary joins, redundant subqueries, or full table scans. These lead to longer execution times, slowing down database performance.
Some Practical Examples
To illustrate these anti-patterns in practice, the following three examples demonstrate common pitfalls in T-SQL coding and their impact on performance, maintainability, and security.
Automatic rewrite of SELECT * and ORDER BY n (anti-patterns)
In the example below, the original query has been rewritten according to two T-SQL development best practices:
- Avoid using
SELECT *. It retrieves all columns (including potential unnecessary), increasing I/O and memory. Instead, select only the columns needed later in the code. This reduces data load, improves performance, and keeps code cleaner. In the example,*was replaced with only required columns:ProductID,LineTotalandOrderQty. - In ORDER BY, relying on numeric positions can lead to errors if the SELECT clause is later modified, changing the order of selected columns without updating the ORDER BY clause. This sorts the results set by unintended columns, potentially resulting in incorrect results and silent bug. It is recommended to explicitly use column names instead of column position numbers.
|
 |
|
Automatic rewrite of arithmetic conditions (non-sargable)
Simple arithmetic expressions can be written differently to force the execution plan to change from using a table or index Scan to Index Seek. The following example is on AdventurWorks2022. Since the SalesOrderID is multiplied, the condition SalesOrderID * 3 < 1200 may prevent SQL Server from effectively using the existing PK index. That’s because SQL Server evaluates the multiplication result and not the column data, ‘hiding’ the indexed data. It compares each single multiplication result to 1200, leading to a Scan on the column. The model is able to rewrite the WHERE condition by moving the arithmetic operation to the right side of the predicate. This preserves the original semantics while making the indexed column directly searchable, enabling SQL Server to perform an Index Seek instead of a Scan.
|
|

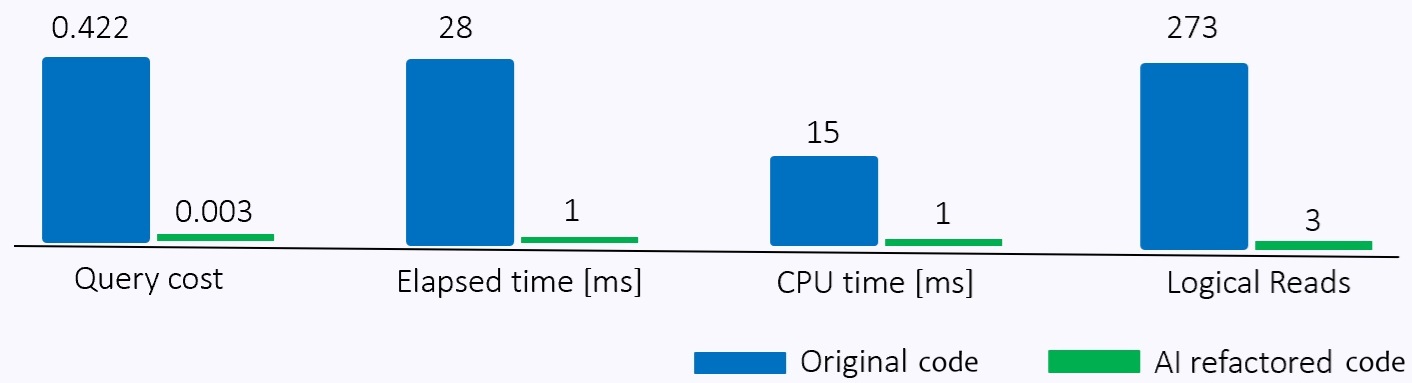
Rewriting arithmetic conditions in order to avoid operators and functions applied to indexed columns provide most performance improvements. The histogram below refers to the above example.
Remove Unused and Irrelevant code (inefficient code)
Removing unused or irrelevant code is essential for improving application clarity, performance, and maintainability.
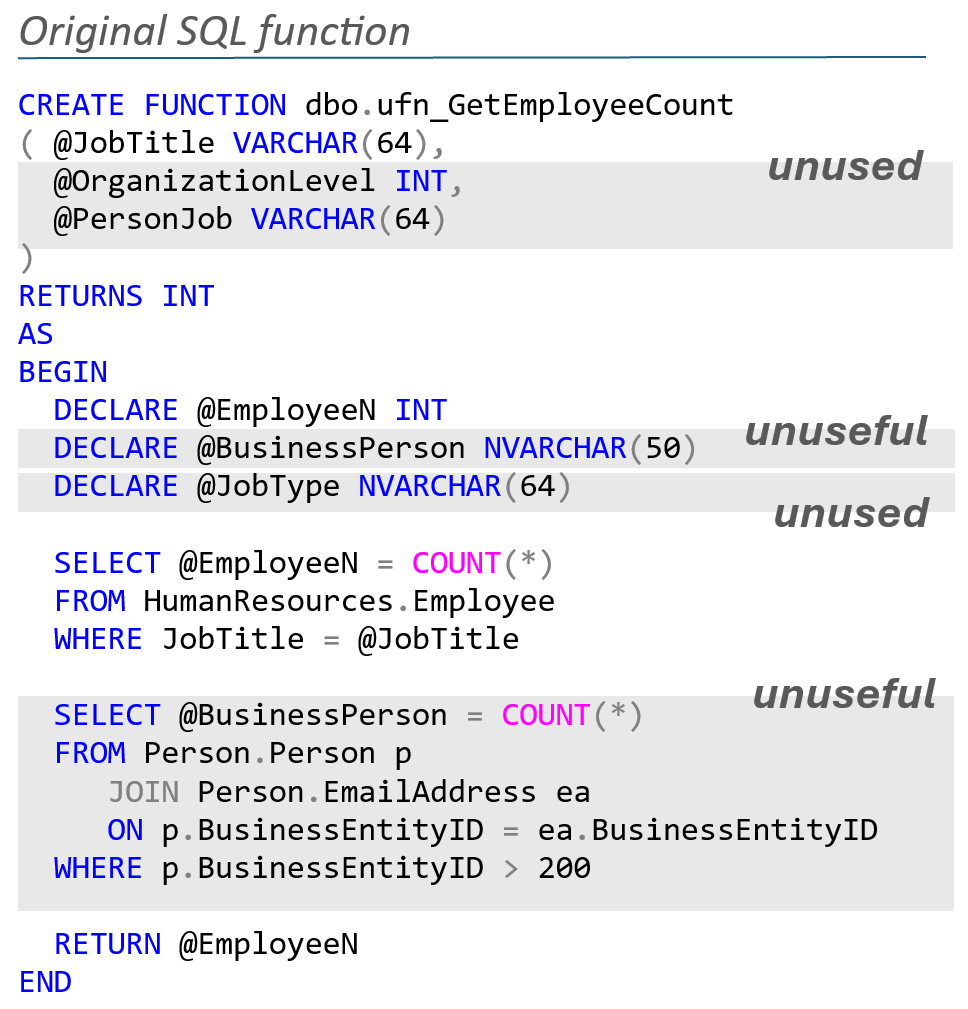
Unused code refers to portions of code that are written but never executed during the lifecycle of an application. This can include declared variables that are never utilized, temporary tables that are created but never populated, or entire logic blocks that remain unreachable.
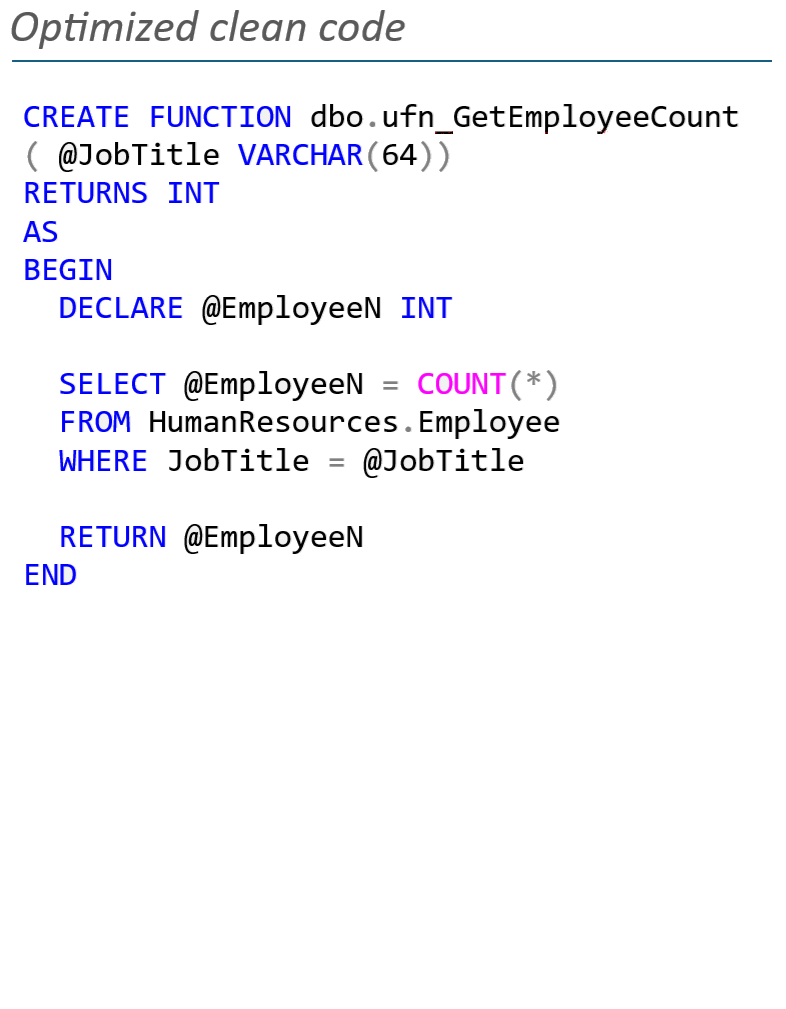
Irrelevant code (unuseful), on the other hand, may be executed but has no impact in the current context. It may have served a purpose in an earlier version of the application or been introduced as a placeholder during development without being finalized or removed. In the example below, the original function contains unused parameters, superfluous local variables, and irrelevant logic. With the right prompts and guidance, an OpenAI model can detect and eliminate these elements, resulting in cleaner, more efficient and maintainable code.
 |
|
 |
Complete use cases list and project details on GitHub
Over 20 real-world use cases have been collected to show how AI models can be guided to rewrite common T-SQL anti-patterns. These cover scenarios such as avoiding non-SARGable queries, preventing implicit conversions, and mitigating SQL injection risks, among others. Each example demonstrates the original code, the refactored version, and the measurable benefits in terms of performance, security, and maintainability.
For those who want to dive deeper, the full source code is available in the GitHub repository SQLAIRefactor. There you’ll find not only all the use cases, but also detailed documentation of the AI solution’s design, the refactoring rules, and practical guidance on how to adapt the approach to your own workloads.
Notes on AI models
Different language models have been employed in this work, each showing slightly different behaviors in handling SQL refactoring tasks. The main models tested include GPT-4o, GPT-4.1 and o3-mini. Although very small, the O3-mini exhibits a limited form of reasoning—sufficient for simple or highly guided tasks. Results in terms of refactoring are very good, with generally no hallucinations and precise coding.
Temperature
In GPT-4o and GPT-4.1 models the temperature parameter controls the randomness or creativity of the generated text. It is a value between 0 and 2.
- Low Temperature (e.g., 0.2): The model produces more deterministic and focused responses, often repeating the most probable output.
- High Temperature (e.g., 1.0 or above): The model generates more diverse and creative outputs, introducing variability and unpredictability.
This parameter directly affects hallucinations—when the model generates false or made-up information. At higher temperatures, hallucinations are more likely because the model takes more risks in word choice. At lower temperatures, responses are more reliable but less diverse. Tests on this solution have proven that value <= 0.4 is a good balance, as hallucinations are not present and there’s good determinism and high-quality responses
Closed-loop feedback
Particularly when using models like GPT-4o and GPT-4.1, in more complex use cases, the initial optimization may not always produce the most efficient outcome, even though the result is correct. While some rules appear to be applied properly, others can be partially implemented, resulting in a partial optimized code where further refinement is still possible. In these cases, the result can be treated as an intermediate output and submitted back to the AI model for a second optimization pass, with the same ruleset. Tests demonstrate that this iterative approach yields significantly better results, effectively capturing optimization opportunities that were not fully addressed in the initial attempt.

Conclusions
You can apply this approach at various stages of the software lifecycle, including development, maintenance, and migration. Solutions based on this methodology can significantly assist developers by automating and enhancing code-related tasks with high efficiency on large codebases.
- Development: During the development phase, this solution can provide real-time support by offering design-time recommendations, identifying and fixing errors within scripts, returning corrected versions. It acts as an intelligent assistant, enhancing code quality as it is written.
- Maintenance: In maintenance scenarios, the approach can automatically assess and refactor large volumes of code very quickly and efficiently. It ensures alignment with best practices by identifying anti-patterns and restructuring queries to comply with T-SQL guidelines and coding standards.
- Migration: When migrating to T-SQL based applications, this solution helps produce compliant code by addressing specific syntax issues, deprecated features or unsupported functionalities in the target platform. This significantly reduces manual effort and the risk of post-migration failures.
A very simple starting example of the solution is available on Github: https://github.com/Savelor/SQLAIRefactor
A neat idea, and with sp_invoke_external_rest_endpoint you can have SQL analyze itself! One catch though, however you do it, is that the schema of many large databases is too big to send to the AI all at once. But you could I suppose send one object's definition to the AI and give it tools/functions/MCP to come back ask you for more object definitions as it tries to understand the code.
But try asking an AI to analyze the ruleset. It'll find some interesting errors. :)
OpenAI's latest models are actually pretty good at finding problems in your SQL without even a ruleset...