

Guest Post
This post has been written by Master’s students at Cornell University. They completed a semester-long project with mentorship from the Azure SQL database product team at Microsoft, creating a full end-to-end AI application. In this post they share the project and the learnings. Thanks everyone, it was fantastic to see the project created from scratch!Project Mission
The way people work and manage information is changing rapidly in our digital age. More and more people are struggling to keep track of all the online resources they use daily. They need a better way to save, organize, and retrieve important information from websites, articles, and other online sources. This is especially true for knowledge workers, researchers, and students who often need to quickly access and synthesize information from many different places.
Project Goal
The primary goal of our project is to develop My Smart Memory, a full-stack web application that enables users to save URLs in their personal cloud storage and retrieve relevant information quickly through a chatbot powered by Retrieval-Augmented Generation (RAG). The app goes beyond simple bookmarking by allowing users to register, create an account, and save content via URLs, while the built-in chatbot searches through saved website content to answer questions based on stored information. This innovative solution addresses the need for efficient information management, empowering busy professionals to quickly recall specific facts or synthesize information from multiple sources, saving time and effort.
This blog post outlines the technical approach taken in developing the My Smart Memory application. It focuses on the architectural design and implementation strategies employed. While this post provides a comprehensive overview, it is not intended as a step-by-step tutorial for building the application from scratch. For those interested in hands-on experimentation, the complete source code is available in the associated GitHub repository. We encourage you to explore the code, try building the application, and share your experiences and feedback.
Meet the Team
- Ariel Zou: Product Manager, Frontend Developer
- Zaeda Amrin: Backend Developer, AI Specialist
- Menghan Xu: Backend Developer, AI Specialist
- Yijie Geng: Frontend Developer, AI Specialist
- Wanxuan Li: Frontend Developer
- Janice Lee: Database Manager
- Ziyu Guo: Database Manager, AI Specialist
- Davide Mauri: Microsoft Mentor
- Arun Vijayraghavan: Microsoft Mentor
- Muazma Zahid: Microsoft Mentor
In this post, we’ll discuss our process of building a powerful RAG-based application that streamlines saving web content and transforms it into a queryable resource to help users save time and boost productivity.
System Architecture
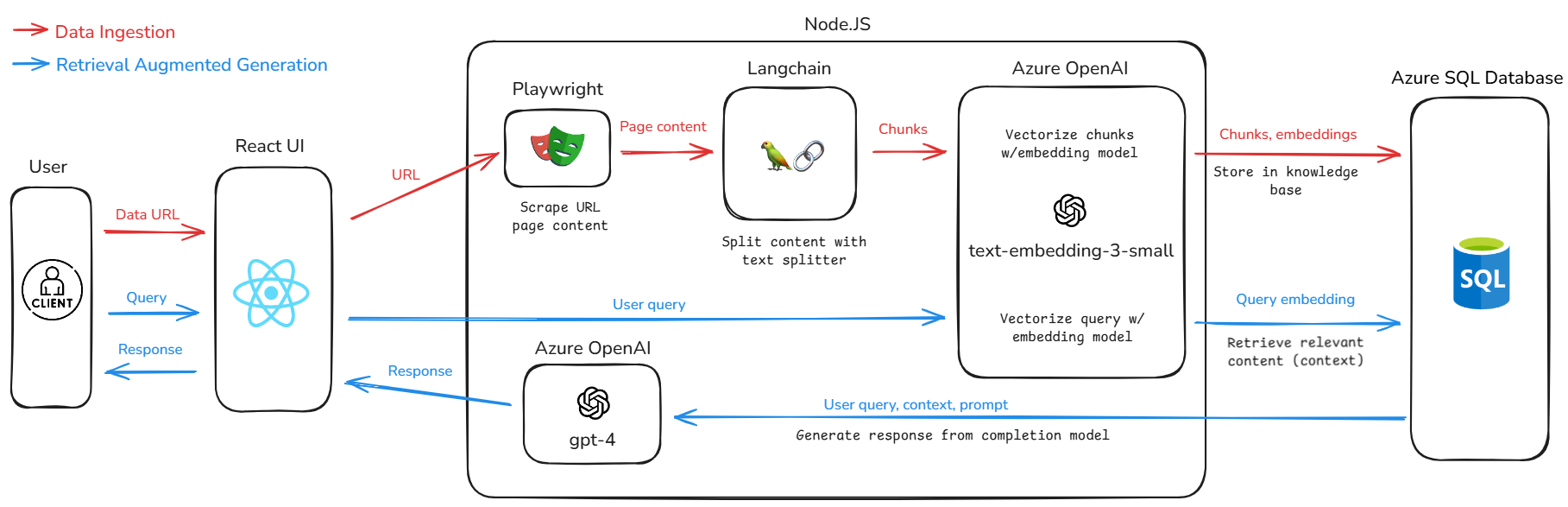
- React.js: used to create the dynamic and interactive frontend of My Smart Memory
- Redux: used to efficiently manage and synchronize the application’s state
- Fetch API: used to fetch data between the frontend and backend
- Azure Data Studio: used for database management and querying
- Node.js: runtime environment that powers the backend services of My Smart Memory
- Express: web framework, supporting routes and controllers on Node.js
- Playwright: used for content scraping
- LangChain: used for text splitting and chunking
- Azure OpenAI API: used for implementing AI-driven features such as response generation
Building My Smart Memory
Prerequisites
Microsoft Azure: Sign up for a free Azure account using Microsoft’s Azure for Students, which provides $100 in free credits for testing cloud resources. Ensure you have access to Azure SQL Database through this subscription for the project.
Node.js and Express: Download and install Node.js to enable JavaScript runtime for server-side development as well as the client-side React.js project. Use npm to install Express, a web application framework for building APIs and web servers.
Database Tools: Install a database client like Azure Data Studio for querying and managing your Azure SQL database.
Frontend Development
For front-end development, we chose React as our development framework due to its component-based architecture, which promotes reusable and maintainable code. React also offers a rich ecosystem of libraries and tools that streamline development, while its flexibility allows seamless integration with other technologies, making it ideal for building dynamic and scalable web applications.
Setup
- Design UI Prototype: Before diving into the development of interfaces, we first created mid-fidelity prototypes of different pages in Figma. The design went through multiple iterations throughout the development process as we incorporated feedback and tested different layouts to improve user experience.
- Initialize a React Project: On a terminal window, we used the following command to create the React project
npx create-react-app my-react-app
Once the setup was complete, we launched the development server at localhost on port 3000 using the command,
npm start
Implementation
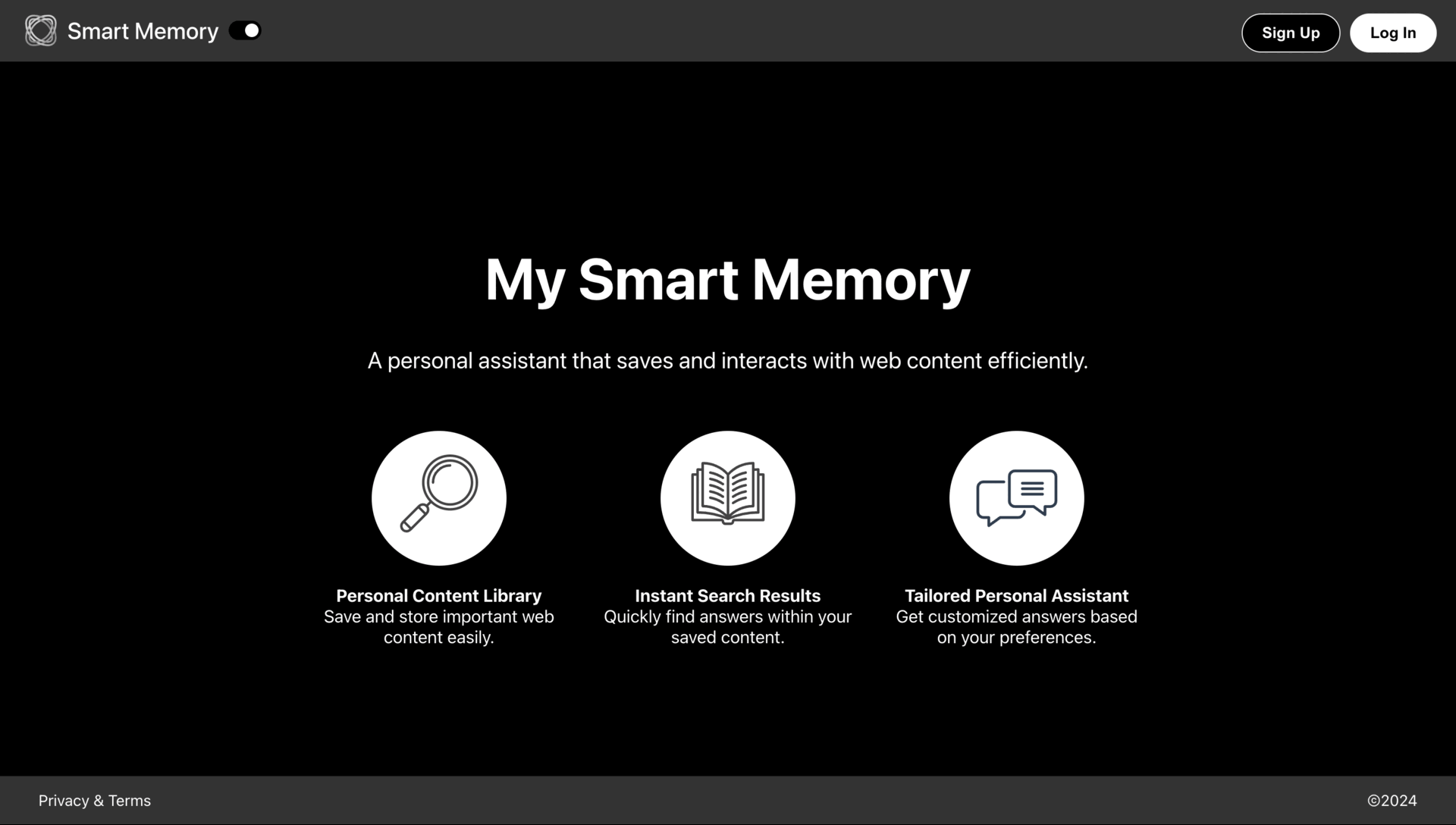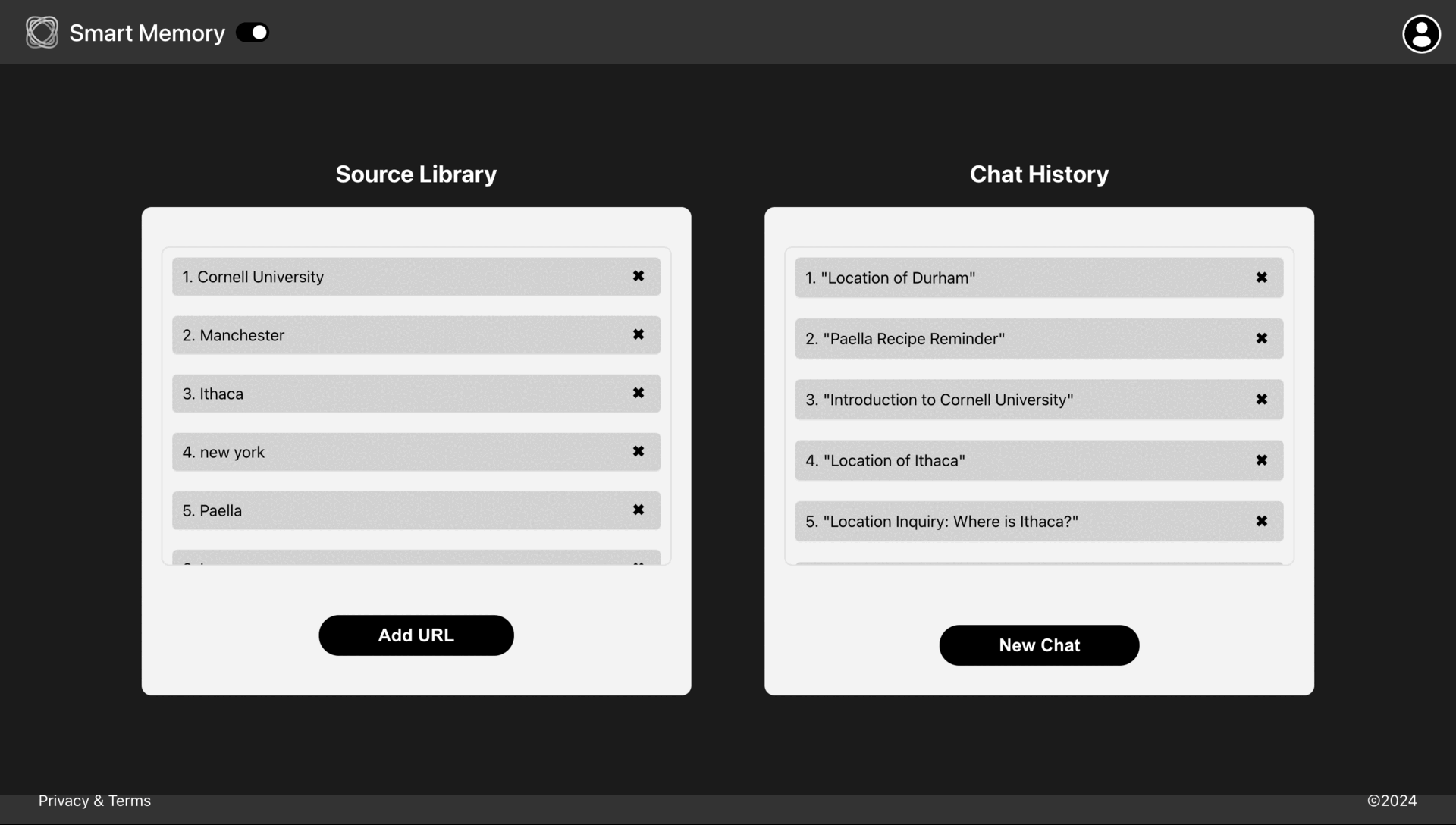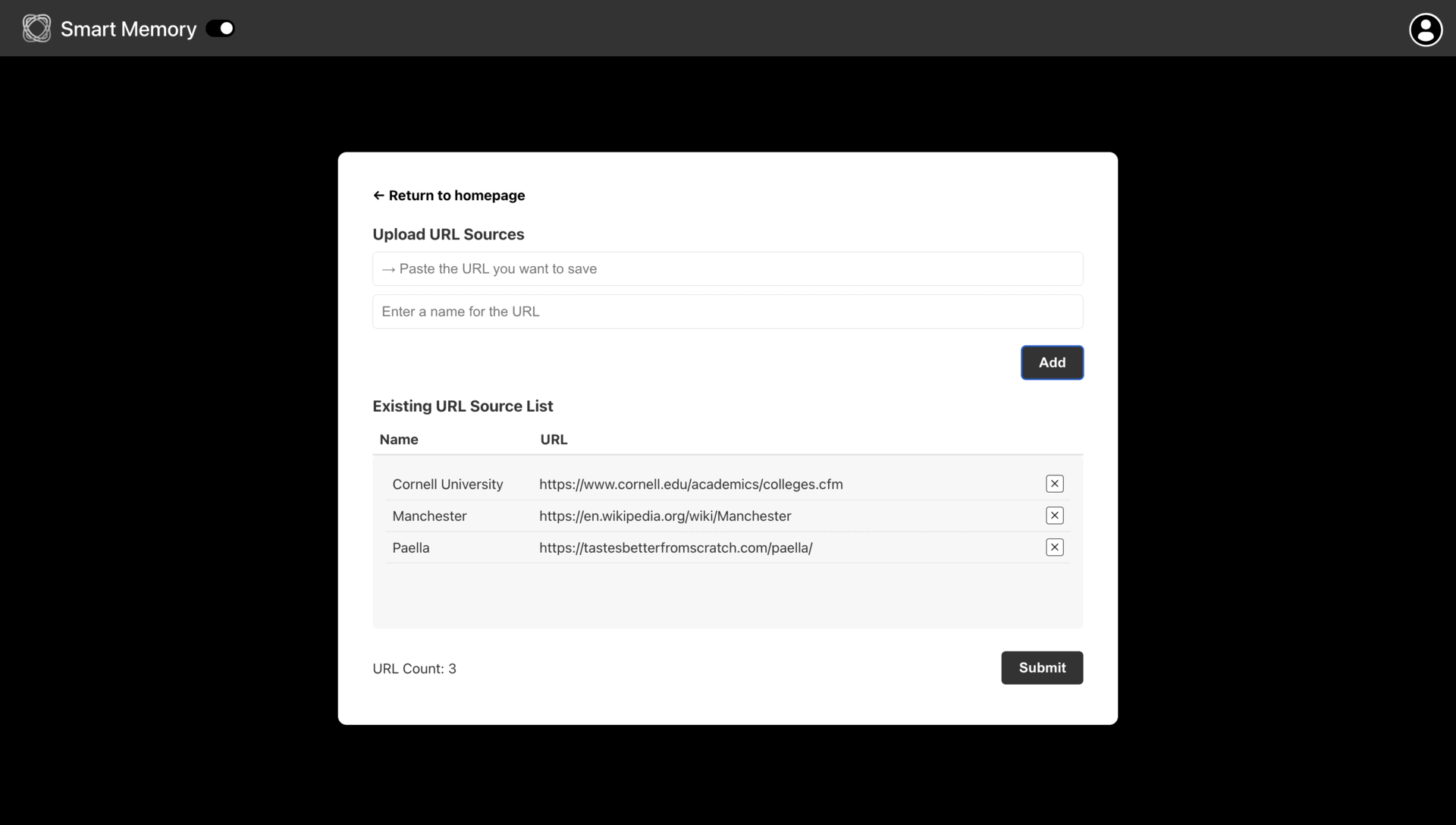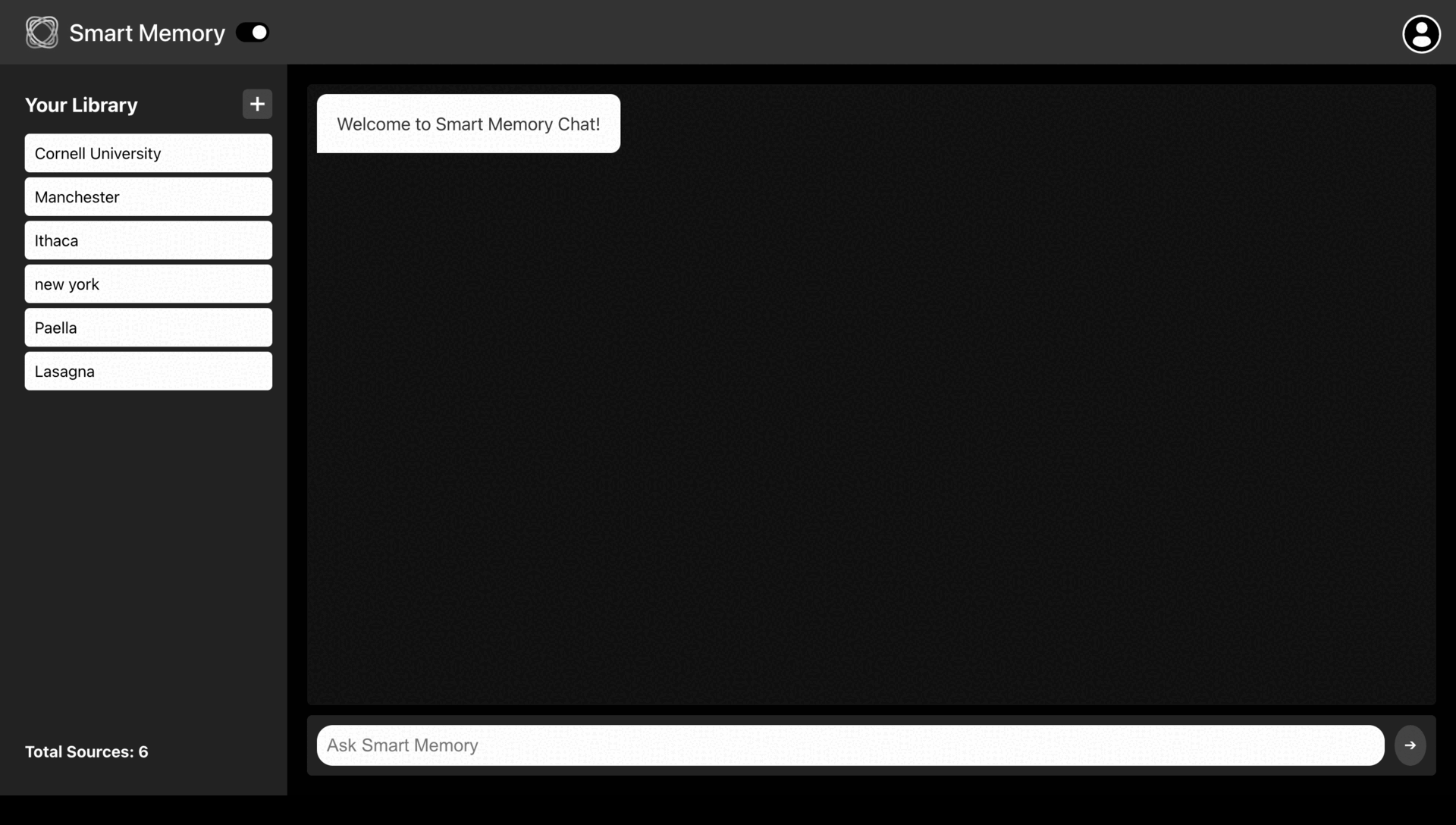
- Components Development: We built reusable React components based on the UI design, including navigation bars, buttons, forms, and content display sections. Once developed, these components were incorporated across different pages using a cohesive design.
- Registration Verification and URL Validation: Based on standard web design practices and project requirements, we implemented a reliable registration verification process that checks whether a user’s email is in a valid format and the password meets security requirements. Additionally, we implemented a URL validation process to ensure pasted URLs are in a proper format, such as starting with “https://”.
- State Management with Redux: We used Redux for global state and theme switching functionality. We implemented a toggleTheme function to handle theme switching, enhancing the user experience and flexibility.
- Markdown Rendering: To improve the content display, we used React Markdown to render both user input and system responses in Markdown format.
- Fetch API: We opted for the Fetch API to handle front-end and back-end communication. The Fetch API supports asynchronous operations and facilitates smooth data synchronization, making it ideal for building responsive and user-friendly web applications.
Database Design and Development
For database development on Mac, we used Azure SQL Database with Azure Data Studio. The tables are quick and easy to set up, and we used Schema Visualization to view the entire schema.
Database Design
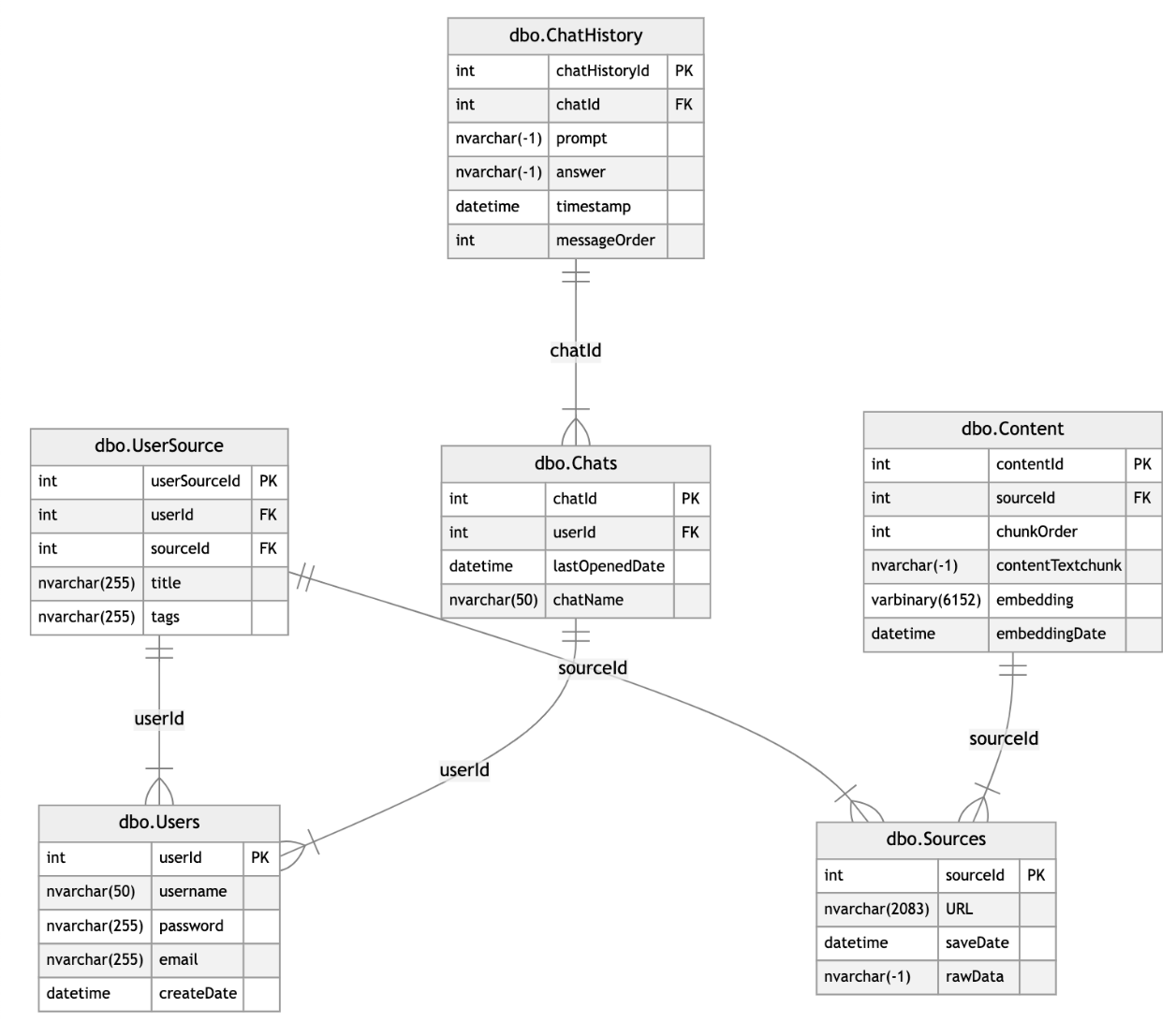
The database schema for My Smart Memory is designed to effectively organize and manage user data, chat history, and content for efficient information retrieval and processing. It includes the following key tables:
-
Users:
Stores user credentials and account details.
-
Chats:
Tracks individual chat sessions and associations with users through userId.
-
ChatHistory:
Records the interaction history within a chat session, including the prompt, answer, timestamp, and messageOrder for maintaining sequential conversations.
-
Sources:
Captures information about the saved URLs, including URL, saveDate, and rawData.
-
Content:
Handles content extracted from sources, storing chunked text and embeddings to facilitate efficient search and retrieval. This serves as the knowledge base of the RAG pipeline for response generation.
-
UserSource:
Links users to their saved sources, enabling personalized management of tagged and titled resources.
Setup and Implementation
-
User Registration and Authentication:
In this initial step, users provide credentials that are securely stored in Users, which contains userId, username, password (hashed), email, and createDate. The backend handles password hashing and uses username or email to verify identities during login.
-
Adding a Source:
When a user adds a source, the backend scrapes and cleans rawData, chunks it into contentTextChunk, and generates embeddings. These processed results are stored in three main tables: Sources (for URL and rawData), UserSource (linking userId and sourceId along with title, tags), and Content (holding each chunk’s text, chunkOrder, embeddingString, and embedding).
-
Engaging in Chats:
For chat sessions, dbo.Chats records chatId, userId, and lastOpenedDate, while dbo.ChatHistory stores each message, timestamp, and message order. When a user sends a prompt, the system inserts it into dbo.ChatHistory. This ensures every conversation is persistent and context-aware.
-
Generating Responses (Similarity and Embeddings):
To respond intelligently, the system generates an embedding for the user’s query and compares it with embeddings in dbo.Content. Embeddings can be handled in the backend (using binary embedding data) or via in-database computations by casting embeddingString to vector formats. Whichever approach is chosen, dbo.Content provides the necessary data for similarity searches, enabling quick retrieval of the most relevant content chunks.
-
Managing Sources:
Users have full control over their content: viewing their sources involves joining dbo.UserSource and dbo.Sources to retrieve title, URL, and tags. When deleting a source, dbo.UserSource breaks the link between user and source; if that source is no longer needed by others, dbo.Sources and dbo.Content entries are removed accordingly.
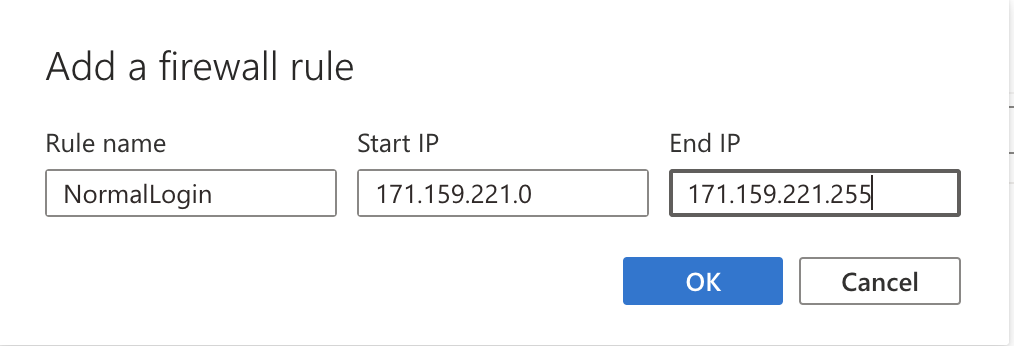
Ensuring controlled access to our SQL Server database was a top priority, and the network firewall was instrumental in achieving this. We viewed the firewall as a key enabler of secure access, not a restriction. We learned how firewalls provide granular control over network traffic, allowing us to define precisely which IP addresses and ports could communicate with the SQL Server instance. By configuring the firewall to permit connections solely from our authorized workstations on the necessary SQL Server port, we established a secure perimeter around the database. This experience underscored the firewall’s role in enforcing security policies and safeguarding sensitive data.
Backend Development
We chose Node.js for the backend, leveraging our existing JavaScript knowledge from the React frontend. Node.js excels at asynchronous operations, ideal for real-time URL uploads and instant answers. Additionally, its flexibility and faster development cycle enabled us to prototype quickly, a crucial factor for our application’s success.
Setup and Implementation
To build the backend for My Smart Memory, we followed a structured process using Node.js to ensure seamless integration with our React frontend. Here’s a high-level overview of the key steps we took:
-
Initialize the Node.js Project:
We started by setting up a Node.js project with an index.js file to serve as the entry point for our application and installed Express to handle routing.
-
Database Connection with mssql:
Using the mssql package, we established a connection to our Azure SQL database to securely store and retrieve user data, such as saved URLs and chat interaction logs.
-
Azure OpenAI Integration:
The @azure/openai package was used to connect to Azure OpenAI, allowing us to leverage its embeddings and GPT-based models for retrieving and generating responses based on user queries.
- Chunks embedding: We used the text-embedding-3-small model provided by Azure OpenAI, which has an MTEB average score of 62.3, for its efficient performance, reliability, and lightweight design.
- Generating answers: GPT-4 was the model we used for generating answers to users’ questions and summarizing chat history content into chat titles.
-
Web Scraping with Playwright:
Playwright was configured to scrape the content of saved URLs. This ensured that the chatbot had access to complete website data for accurate and comprehensive responses.
-
Setting up RESTful APIs:
Controllers were used to handle business logic, routes mapped endpoints to HTTP methods, Swagger was integrated to document the API for clarity and usability, and Postman was used to test and validate the API functionality.
-
Content Chunking and Context Retrieval:
LangChain’s utilities were employed to chunk scraped content into manageable sections efficiently. This approach optimized the chatbot’s ability to process long-form content.
-
Real-Time Query Handling:
Node.js’s asynchronous capabilities allowed us to handle user queries in real time, processing requests and returning responses without delay.
Challenges
- Even with clear instructions in the prompt, the model struggled to identify responses using stored content. To solve this problem, we added a note informing users when no stored chunk was used to generate an answer.
- Database connection setup was initially challenging. Our TA’s help enabled correct configuration, pool initialization, and queries.
- There were also some challenges setting up OpenAI in our Node.js project due to outdated documentation and guides mostly focused on Python. Many still referenced the deprecated AzureKeyCredential, which has since been replaced by the azure-identity package. After investigation and help, we used the latest azure-identity method (Nov 2024 docs). Additionally, we switched from ES modules to CommonJS for package/dependency compatibility.
Input Prompt
The prompt we used to send query to GPT-4 is:
messages: [ { role: 'system', content: 'You are a professional assistant that helps users recall and understand information from online content they have provided. Use the given context to answer their questions accurately and concisely. If the required information is not in the provided content, inform the user and offer general guidance if appropriate. Always ensure your responses are clear, concise, and relevant to the query from the user.' }, { role: 'user', content: `Context: ${context}\n\nQuestion: ${userMessage}` } ]
Database Connection Code
const sql = require('mssql');
const config = {
user: USERNAME,
password: PASSWORD,
server: SERVERNAME,
database: DATABASENAME
encrypt: true/false
trustServerCertificate: true/false
};
const poolPromise = sql.connect(config)
.then(pool => {
return pool;
})
.catch(err => {
console.error('Error connecting to the database:', err);
});
module.exports = { pool: poolPromise };
Azure OpenAI Client Connection Code
const { AzureOpenAI } = require("openai");
require("dotenv/config");
const endpoint = process.env.ENDPOINT;
const apiKey = process.env.API_KEY;
const apiVersion = process.env.COMPLETION_API_VERSION;
const deployment = process.env.COMPLETION_MODEL_NAME;
const client = new AzureOpenAI({ endpoint, apiKey, apiVersion, deployment});
module.exports = { client };Deployment
To deploy the frontend, we used Vercel. After creating an account, we connected our GitHub repository containing the React application using Vercel’s configuration settings. Vercel automatically built and hosted the project, simplifying the deployment process.
For the backend, we used Render with a Dockerized Node.js project to support Playwright’s dependencies. We deployed our Docker project by setting up Docker locally, creating a Render service, and linking our GitHub repo. One challenge with our deployed project was connecting to our Azure server, as Render does not support Entra ID authentication. To resolve this, we added the static outbound IP address of our web service to the Azure server’s firewall rules.
Future Roadmap
Due to time constraints, we focused on core features for a solid user experience. With more time, we would have enhanced functionality, improve security, and personalization.
- Log out feature & JSON Web Tokens (JWT): Improve user session management and strengthen system security.
- Response Quality Control: Design and implement automated tests to validate the accuracy, relevance, and reliability of generated responses.
- Source Citation: Provide citations for all sources used to generate each answer, including URL links, at the end, enabling users to verify information and access further details.
- Source Selection: Allow users to select specific sources they want to base the conversation on.
- Content Summary: Automatically generate summaries of uploaded URLs to help users quickly grasp the key points.
- Platform Integration: Integrate with tools like Microsoft Teams or OneDrive to allow users to seamlessly incorporate Smart Memory into their professional workflows.
- Behavior-based Recommendations: Use machine learning to suggest relevant URLs or queries to users based on their past activity.
Key Takeaways
My Smart Memory gives users quick access to saved web content, saving time. We built it with Microsoft tools like Azure SQL, OpenAI, and Playwright. It uses LangChain for content chunking and OpenAI’s GPT for generating responses. Its design and reliability demonstrate our commitment to productive tools. This sets the stage for future enhancements.
Acknowledgment
We would like to extend our deepest appreciation to Muazma Zahid, Davide Mauri, and Arun Vijayraghavan from Microsoft for their continuous support and guidance throughout the project. Their expert advice helped us overcome technical hurdles, gain a deeper understanding of the project’s requirements, and address edge cases. We are also grateful to our course professor and TA for their valuable feedback and assistance, which significantly contributed to the successful execution of our work.
More Information
Project Repository: https://github.com/zaedaamrin/theta_project
Figma Prototype: https://www.figma.com/design/HDPm0qbbLDD4WsMAqQfvJM/Microsoft-Smart-Memory?node-id=0-1&node-type=canvas&t=uTEcNLolxUsCh6GQ-0
0 comments