
Artificial Intelligence (AI) has the potential to transform how we fight climate change. However, it also increasingly contributes to it: the carbon footprint of AI will grow exponentially over the next decade, and is projected to grow at a CAGR of nearly 44% globally through 2025.
The industry is trending towards bigger models (e.g. GPT-3): these require ever-growing datasets, compute budgets, and incur massive energy bills over the model lifecycle. Computational costs of AI models have been doubling every few months, resulting in an estimated 300,000x increase from 2012-2018. In the past two years, the number of parameters have grown 170X. Currently, training a single 213M parameter NLP deep-learning model through an architecture search can generate the same carbon footprint as the lifetime of five American cars, including gas.
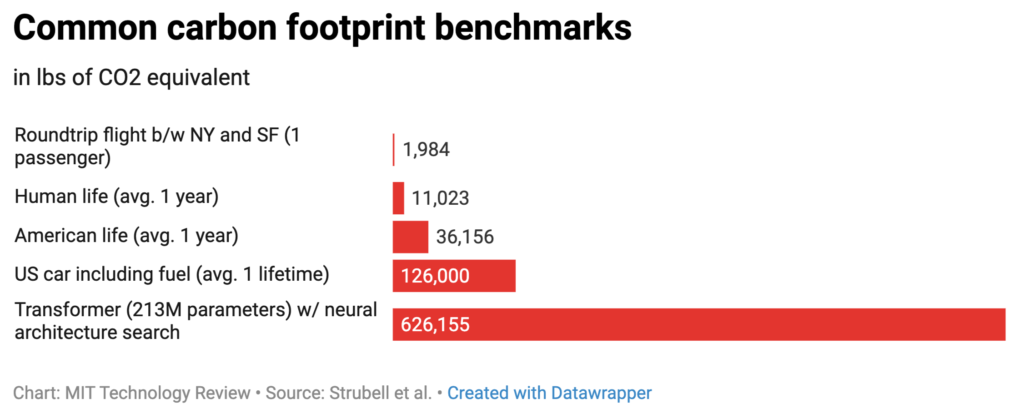
Source: Emma Strubell, Carnegie Mellon University
Environmental sustainability should be considered as one of the principles towards responsible development and application of AI. The benefits of using such technology should outweigh its drawbacks, and it’s time to bring the conversation about the hidden costs of AI to the forefront.
‘Data Is The New Oil’
According to Gerry McGovern’s book ‘World Wide Waste’, 90% of data is not used – merely stored (which is cheap). He argues that because of this, the IT landscape is ~90% waste: 91% of pages analyzed got zero traffic from google, and more people have been to the top of Everest than the 10th page of search results. It’s no surprise that companies are seeking capitalize on this unprecedented amount of data collection. AI provides a way to make sense of massive amounts of data, but the current state-of-the-art requires a massive amount of data for training & validation. The more weights a model has, the more data it needs.
“The AI industry is often compared to the oil industry: once mined & refined, data, like oil, can be a highly lucrative commodity. Now it seems the metaphor may extend even further” – MIT Technology Review
There are promising, but emergent methods such as ‘few-shot learning’ and ‘less than zero-shot learning’ which will allow ML systems to learn & reason from a handful of examples. However, in the interim, the industry is currently trending towards increasingly large datasets, which require massive computational training budgets.
Bigger Is Not Always Better
The human brain is remarkably efficient; it can learn from a single example and apply this knowledge in a wide variety of contexts for the rest of its life. It requires relatively little energetic input: the brain only requires 20W to operate, and the global average of a human life requires around 8,000 lbs Co2/year.
Nature has done a significantly better job of engineering a brain than we have with AI. This represents significant potential for improvement: according to some of the brightest minds in the industry, ‘Artificial Intelligence’ isn’t yet close to being intelligent in any meaningful sense of the word. ML systems learn to perform a specific task by observing lots of examples, and pattern matching data by what can be viewed as a brute-force computational approach.
This requires staggering amounts of energy (data & compute resources) to perform pattern matching & superhuman statistical analysis. As a result, state-of-the-art approaches to AI are engaged in a computational arms race to achieve the next benchmark performance. A 2018 analysis led by Dario Amodei and Danny Hernandez of the California-based OpenAI research lab, an organization that describes its mission as ensuring that artificial general intelligence benefits all of humanity, revealed that the compute used in various large AI training models had been doubling every 3.4 months since 2012 — a wild deviation from Moore’s Law, which puts this at 18 months — accounting for a 300,000× increase.
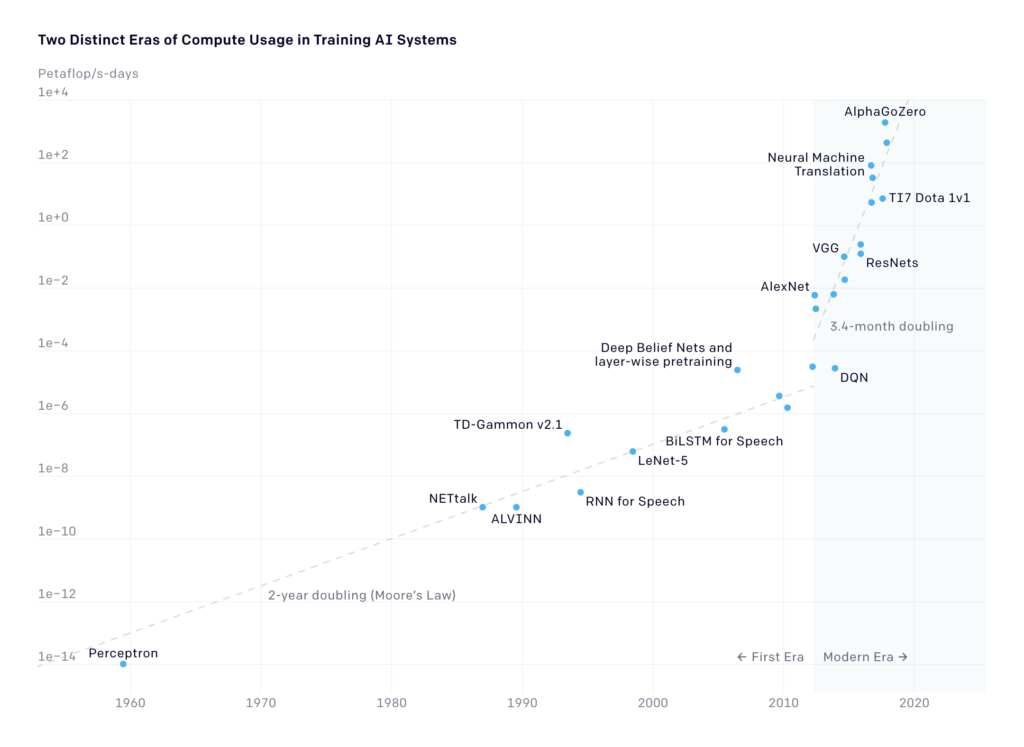
Source: https://openai.com/blog/ai-and-compute/
It is noteworthy that there have been major efficiency gains in recent years: According to OpenAI, compute cost has been halving every 16 months for equivalent model performance. Since 2012, the same model requires 44X less compute. However, we’re rapidly approaching outrageous computational, economic, and environmental costs to gain incrementally smaller improvements in model performance. For the moment, computational cost has a linear relationship with the amount of data, epochs, and hyperparameters involved in training. The state-of-the-art advances are primarily achieved through scale: bigger datasets, larger models, and more compute.
“I think the best analogy is with some oil-rich country being able to build a very tall skyscraper. Sure, a lot of money and engineering effort goes into building these things. And you do get the ‘state of the art’ in building tall buildings. But…there is no scientific advancement per se.” – Guy Van den Broeck, UCLA
The AI industry is currently what researcher Roy Schwartz (Allen Institute For AI & Hebrew University of Jerusalem) has deemed ‘RedAI’: performance & accuracy at the expense of efficiency (speed, energy cost).
A McKinsey report from 2017 indicated that 88% of ML projects never reach production, suggesting that many experimentation paths are dead-ends with a corresponding carbon footprint. Even if a ML project does mature to production/publication, it will have required many different tunings/trials to achieve the max performance, likely exceeding 10-20 training runs to produce a single model with the highest accuracy.
Model training represents only a portion of the total carbon footprint: it is important to holistically analyze the footprint across all phases of an ML project.
Deployment & Lifecycle
While deployed, model inference has an outsized footprint: NVIDIA has estimated that inferencing constitutes 80-90% of total carbon cost of a ML model. This warrants a cross-industry framework for a full Life Cycle Analysis (LCA) to evaluate embodied carbon across the ML lifecycle.
GreenAI
There are ways to make machine learning greener, a movement that has been dubbed ‘GreenAI’, initiated by Natural Language Processing researchers. This community is pushing for efficiency as a core metric. Some conferences (below) now require submissions to fill out forms that include information about the computational budget used to generate the reported results.
GreenAI is in its infancy, and presents both numerous research opportunities and industry partnership potential. By bringing visibility & accountability into our ML efforts, we can begin to prioritize reporting and efficiency measures to incentivize sustainable AI practices. In future posts, I will dive into particularly promising approaches (such as reporting & efficiency methods). In the interim, here are some resources that can get you started in the community:
Get Involved
OSS packages to start tracking the carbon footprint of your experiments:
Conferences:
0 comments