
Introduction
Today most workloads run on provisioned servers and the demand for compute is increasing every day. However not all workloads need dedicated compute. The idea behind this blog is to present a typical architecture of a Scalable web application with some long running operations and how we can build this architecture in a more carbon efficient way (adopting principles of https://aka.ms/sse/learn). I will present an architecture using serverless components like Azure functions, Cosmos DB, event grids etc.
Serverless architectures aiding sustainability
Serverless architectures have been gaining quite a bit of traction lately. The concept around serverless is not to provision cloud servers exclusively for a specific workload or customer, but rather to use them when they are needed and then de-allocate them after the completion of workload execution. This also serves the sustainability story very effectively as servers, storage, and network bandwidth are used to their maximum utilization levels.

Azure serverless
Today, in Azure we can build an enterprise application using all serverless components – Azure functions, Logic apps, Event grids, and Cosmos DB (serverless option). In this post, I will take a traditional web application with integration requirements that we typically build out using provisioned servers and will demonstrate building the application using serverless components. In subsequent articles, I will enhance this architecture using other sustainable patterns like Edge computing and Delayed compute, which will shift the processing of workloads to times when renewable power is available.
Why serverless enables the green cloud?
As we know, the main consumers of power on a server will be the CPU, the GPU, and memory (See Sara Bergman’s article Power Consumption of Backend Services). Understanding how much power each of these components consumes will give you an estimate of how much power your server, or your application on a server, consumes. How do you estimate the power calibration for these components then? We do that by calculating the cooling power required for these components and use this co-efficient to correlate with energy. We assume that the energy used by these components is directly proportional to the cooling needed. This calculation and formula is explained in more detail in Power consumed in the cloud.
This will, of course, be an estimate but if your goal is to start tracking energy consumption and make sure you are improving, this will do the job. The less energy consumed by these components, the lower amount of fossil fuels that will be needed to power the data center. Hence, we can theoretically state that one way to reduce the carbon footprint of our applications is to reduce the CPU, GPU, and memory usage of the servers on which our workloads are running. It doesn’t mean that we should underpower our workloads, rather we should help organizations by helping to run servers at a higher utilization rate. Serverless architectures enable this objective.
Case Study –Contoso Claim Processing Application
Contoso is rapidly expanding their car insurance claim processing business to operate on a much larger scale. The company wants to move their current system, which is setup on-premise to the cloud and they want to be known as an insurance provider that cares about their carbon footprint. One of the key aspects in achieving Contoso’s objective, is going serverless.
The current system entails claim processors going to the customer site, taking photos of the vehicle license plate, and uploading it through a mobile device to cloud storage. The current backend system consists of GPU VMs which process these images and extract text information from them. The claim processing backend system takes the vehicle license plate as input, identifies the insured’s information, and validates or rejects claims based on information gathered from other systems.
Architecture of the solution
Below is the high-level architecture of the solution that is based on the eight Sustainable Software Engineering Principles.
- Compute resources are allocated dynamically as needed by the platform. The compute resources scale on demand based on traffic, without the developer needing to do any configuration.
- Use Consumption-based services rather than provisioning a compute server and adding server components.
- Event based processing architecture should be used for integration and events should be published and subscribed to in standard format by these systems.
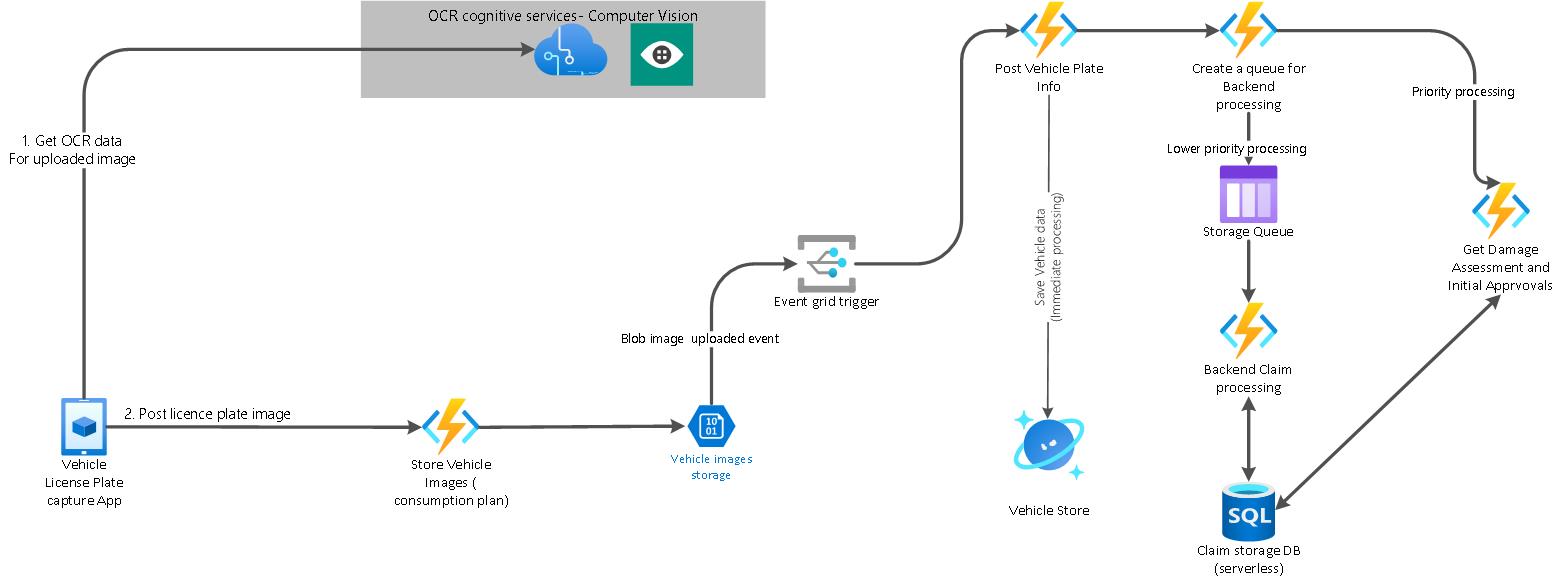
Let us get into details on some of the architectural building blocks of this application.
Claim Processing Front End Components
A user interface needs to be built to help claim processors in the field capture and upload images. In the architecture, we will inject the pipeline image through Azure cognitive services Computer Vision API and extract the text from the image through OCR technology. This adheres to one of the sustainable design patterns – Serverless processing. Microsoft Azure cognitive services are completely serverless. Clients are charged based on the number of times these services are called and there is no pre-provisioned compute anywhere.
In a future article, we will look at ways we can bring the OCR compute down to devices and we can offset some of the processing to the power we have on these devices . We can even host cognitive services as a container at the edge or use advanced apps available in play stores to do text extraction from images.
The extracted license plate info and the image must be stored AS-IS for future state processing. For this we set up Azure functions based on consumption plan, which is entirely serverless.
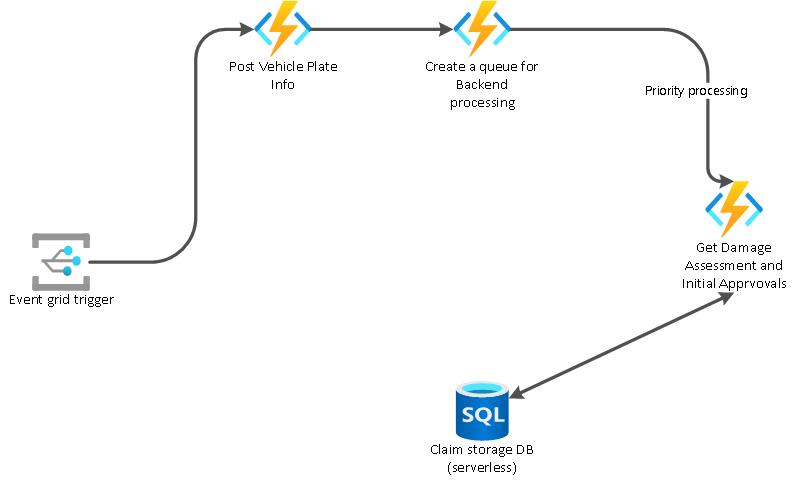
An Event Grid subscription is created against the Blob storage create event. In this design we use a sustainable design pattern of priority processing. Once the image is uploaded, the image meta data and vehicle data must be saved in a NoSQL database that is used by the online claim processing systems. The vehicle information, initial insurance information, and insured information is all mapped inside the NoSQL cosmos DB serverless database.
Claim Processing Back End Components
Beyond the online transactions around image capture and license plate information extraction , claim processing is a time-consuming process. It involves interaction and information gathering from other systems in the enterprise, such as quote information, pricing information and also historical information on claims from previous years. Hence, we need to delineate which of this compute is priority and which can be delayed so that we don’t over provision compute to solve all these problems together. There are 2 types of recommended processing pipelines for the claim.
1) Some claims need to be processed to get a damage and assessment report immediately. Such higher priority processing happens through HTTP pipeline. Hence we have provisioned an Azure function based on HTTP trigger – GetDamageAssessmentAndInitialApprovals to hit the SQL database, which is the Master Database of all claims data and get the required information instantaneously to the claim processor who is at the customer site .
2) Delayed compute design pattern is used for processing lower priority pipelines that happen through queues. We use delayed compute since claim process will need to fetch data from multiple back end systems and external APIs (valuation APIs, credit history of the insurer, etc.), which could take hours or even days. The processing for these operations is not priority and hence is taken through the queue pipeline.
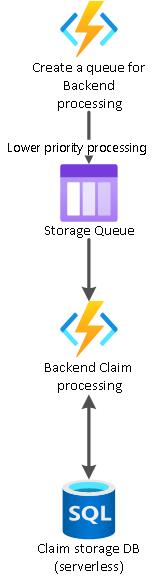
The key piece we need to understand here is that we are delineating between priority processing and delayed processing as an informed sustainable design pattern.
As you have seen we have built and designed a sustainable software architecture for a traditional type of application by adopting green software design principles. We have plans to extract even more from this architecture by moving some components to the edge and also looking at ways to optimize the draining of the queue during the Backend Processing. Feel free to provide your thoughts on these enhancements in the comments below and we will try to incorporate your suggestions as well in the architecture. To learn more about Sustainable Software Engineering, please complete the self-paced Sustainable Software Engineering Learn Module.
0 comments