


UPDATE: This Sample has been deprecated. See the Chat Copilot example app on how to use embeddings and memories.
Have you ever wanted to Ask questions to a GitHub repo? How many files are there, what languages are used, who contributed to it, what topics are covered, and so on? If you are a developer, researcher, or curious learner, you probably have. And you probably know that finding these answers can be tedious and time-consuming. You must clone the repo, browse through the folders and files, open and read the code or documentation, run some commands or scripts, and hope that everything works as expected.
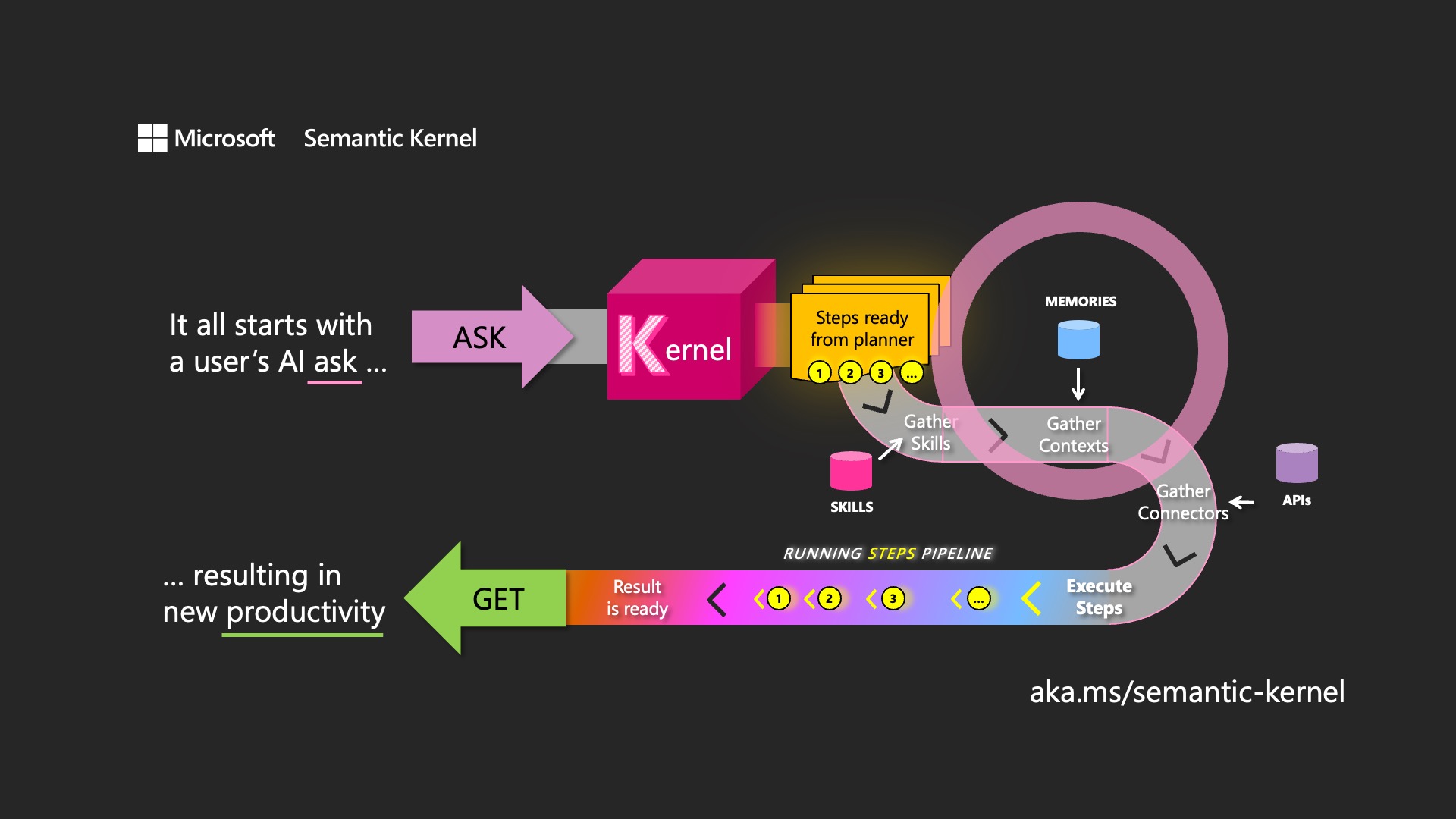
But what if there was a better way? A way that lets you explore any GitHub repo with just a few natural language questions? A way that uses the power of embeddings and memories to create a rich representation of the repo’s content and structure.
That’s exactly what we have created with our new sample app: Repo Example. This sample shows how you can use a SK function to download any GitHub repo, store it in memories (collections of embeddings), and query it with a chat UI. You don’t need to clone the repo or install any dependencies. You just need to provide the URL of the repo and let the sample app do the rest.
Use this sample as a guide for storing and querying items like:
- Large internal procedure manuals
- Educational materials for students
- Corporate contracts
- Product documentation
Next steps:
Explore the sample in GitHub: https://aka.ms/sk/repo/samples/github-repo-qa-bot
Read the documentation about the sample: https://aka.ms/sk/github-bot
Join the community and let us know what you think: https://aka.ms/sk/discord

Could we use a data dictionary/data catalog/schema to create queries based on that data using this approach?
You control what goes into the memories (see SaveInformationAsync in https://github.com/microsoft/semantic-kernel/blob/main/samples/dotnet/github-skills/GitHubSkill.cs) so you could create a data dictionary based on what you store and query it.