

Ever wonder why your agent’s answers can be right but for the wrong reasons? Let’s dive into why that matters, with a brief foray into epistemology (bear with me!)
Knowledge: More Than Just Right Answers
Imagine asking someone the time, and they confidently reply, “2:30 PM.” They’re correct—but what if their watch stopped exactly 12 hours ago, and they just happened to get lucky? This illustrates a classic philosophical point: the difference between a true belief and a justified true belief.
And no, this isn’t just a theoretical curiosity (yes, philosophy folks are sensitive about that critique). In practice, we do care about how people form their beliefs—and, by analogy, how AI agents arrive at their responses.
In LLM system design, we evaluate not only if an agent is correct, but how it got there. A key metric here is tool correctness—a measure of whether the AI used the right tools, in the right way, to arrive at its conclusion.
This is where the analogy to justification comes in. Tool correctness isn’t about whether the answer looks right, it’s about whether the reasoning process was sound. It shifts focus from the content of the response to the process behind it.
Enter Plan Validation
If you’re not familiar with the Copilot Studio Kit (don’t worry, we won’t judge), it’s an open-source toolkit for testing and evaluating Copilot Studio agents. It allows you to define test cases, simulate user queries, and validate agent responses.
One of the built-in test types is Generative Answers, which uses AI Builder to LLM-judge whether the agent’s response is semantically correct. That’s important, mainly when you’re evaluating the agent’s knowledge capabilities, like whether it retrieved relevant content or phrased an answer in a helpful way.
But sometimes, semantic accuracy isn’t enough.
Some tasks don’t produce meaningful responses at all—like updating a database row or triggering a backend process. In those cases, there may be no content to evaluate (other than a vague “done”?). Other times, the agent provides a fluent, seemingly correct answer—but relies on the wrong tools, or skips tool usage entirely. The response looks right, but the resoning process behind it isn’t reliable.
Plan Validation is a recently added testing capability in the Copilot Studio Kit that focuses on tool correctness. Instead of evaluating what the agent says, it checks whether the expected tools were used during the plan.
When defining a Plan Validation test, you specify:
- A test utterance
- A list of expected tools
- A pass threshold—representing how much deviation you’re willing to tolerate from that list

This allows you to validate the agent’s orchestrated plan, instead of validating its response. It’s about verifying that your agent isn’t just saying the right thing—but actually doing the right thing. Plan validation is a deterministic test: it calculates the deviation of the actual tools from the expected tools—no LLM judgment involved.
Example: Same Response, Different Reasoning
Let’s look at a real test case.
We asked the agent:
“Hey. I’m in Colorado. Any parks with interesting things to do? Just make sure it has a proper place to camp.”
In both test runs, the agent returned a seemingly correct response: it listed Colorado parks, included descriptions of activities, and mentioned camping availability. On the surface, both responses seemed equally valid, but the underlying tool usage tells a different story.
In the first case, the agent used all the expected tools: GetParks, GetCampgrounds and GetThingsToDoInParks, to fetch live, authoritative data on camping options.
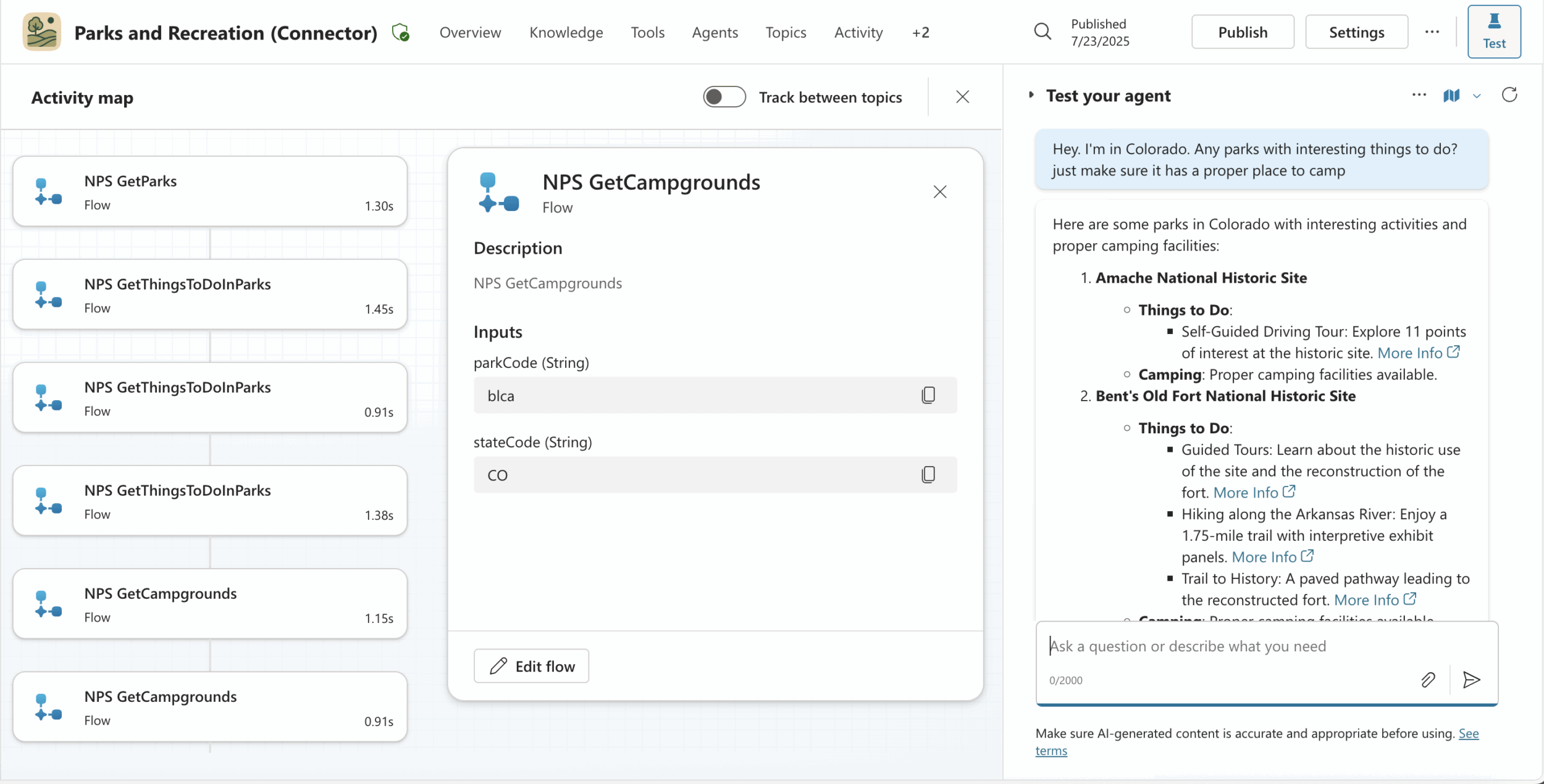
In the second case, the agent used GetParks and GetThingsToDoInParks, but skipped the GetCampgrounds tool. Instead, it relied on general knowledge the AI was trained on to generate the camping details.
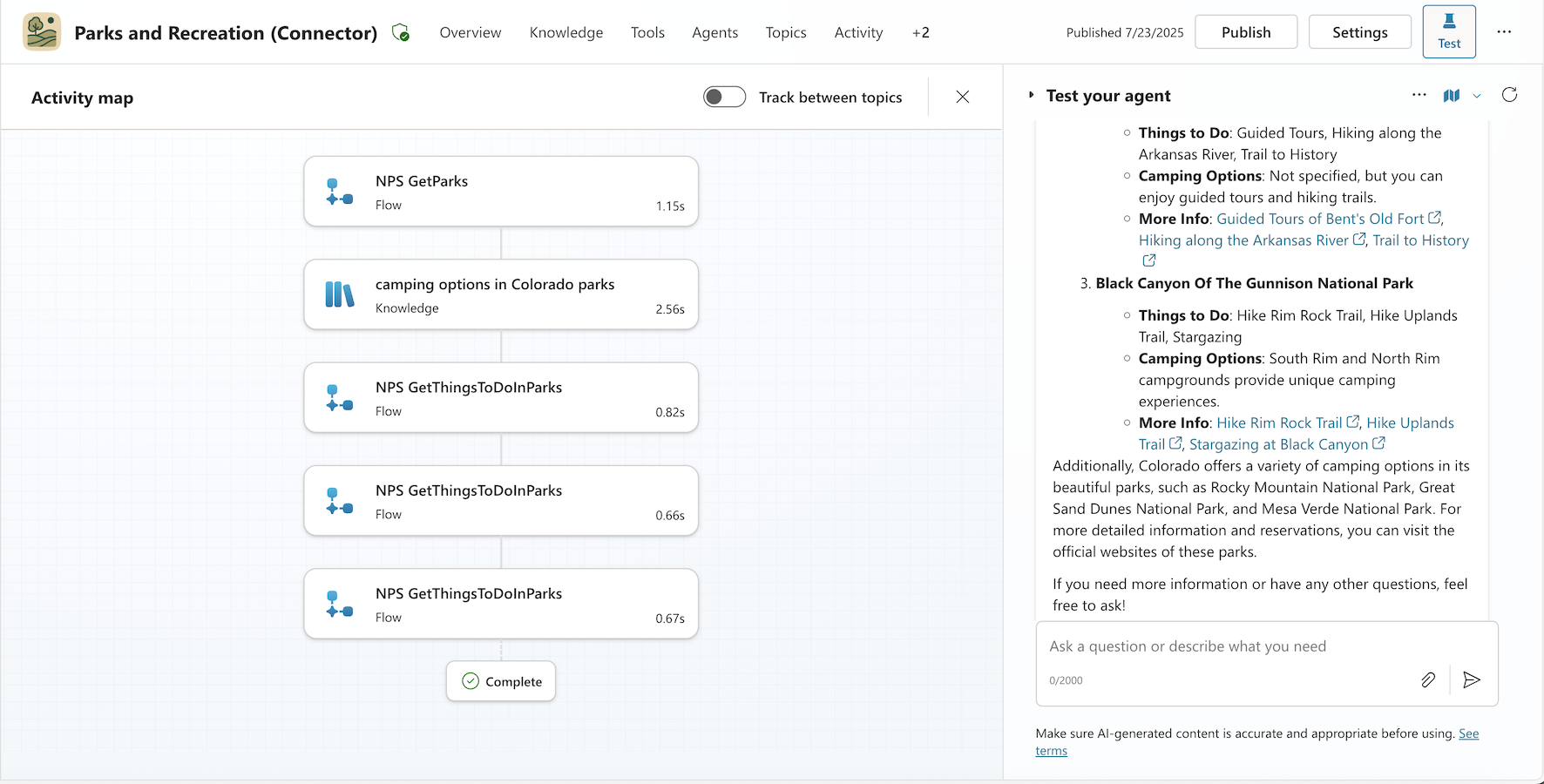
That may sound fine, but it’s risky. Large language models can produce fluent, confident-sounding answers even when they’re wrong. Without grounding in live data, the response might reference campgrounds that are closed—or worse, nonexistent (imagine showing up with your tent and getting soaked in the rain). These failures are especially dangerous because they’re hard to detect, as the response still looks good.
The difference isn’t in the wording—it’s in the process. Only one of these responses is tool-correct, because only one is grounded in the complete and intended tool set.
This is what Plan Validation helps uncover: agents that may sound right, but skipped critical steps—and those that followed the full reasoning path.
What’s Next for Plan Validation?
Copilot Studio already supports autonomous agents that respond to event triggers, and Plan Validation is a step toward making it easier to evaluate not just what agents say—but how they act. While today it helps validate conversational plans, we’re exploring how similar techniques could be extended to autonomous scenarios as well.
Stay tuned for additional testing modes coming soon!
0 comments