



As enterprise customers roll out and govern AI agents through Agent 365, they have been asking for pre canned evals they can run out of the box. They want transparent, reproducible evaluations that reflect their own work in realistic environments, including interoperability, how agents connect across stacks and into Microsoft Agent 365 systems and tools. In response, we are investing in a comprehensive evaluation suite across Agent 365 Tools with realistic scenarios, configurable rubrics, and results that stand up to governance and audit as customers deploy agents into production. Introducing Evals for Agent Interop, the way to evaluate those cross-stack connections end to end in realistic scenarios.
Introducing Evals for Agent Interop
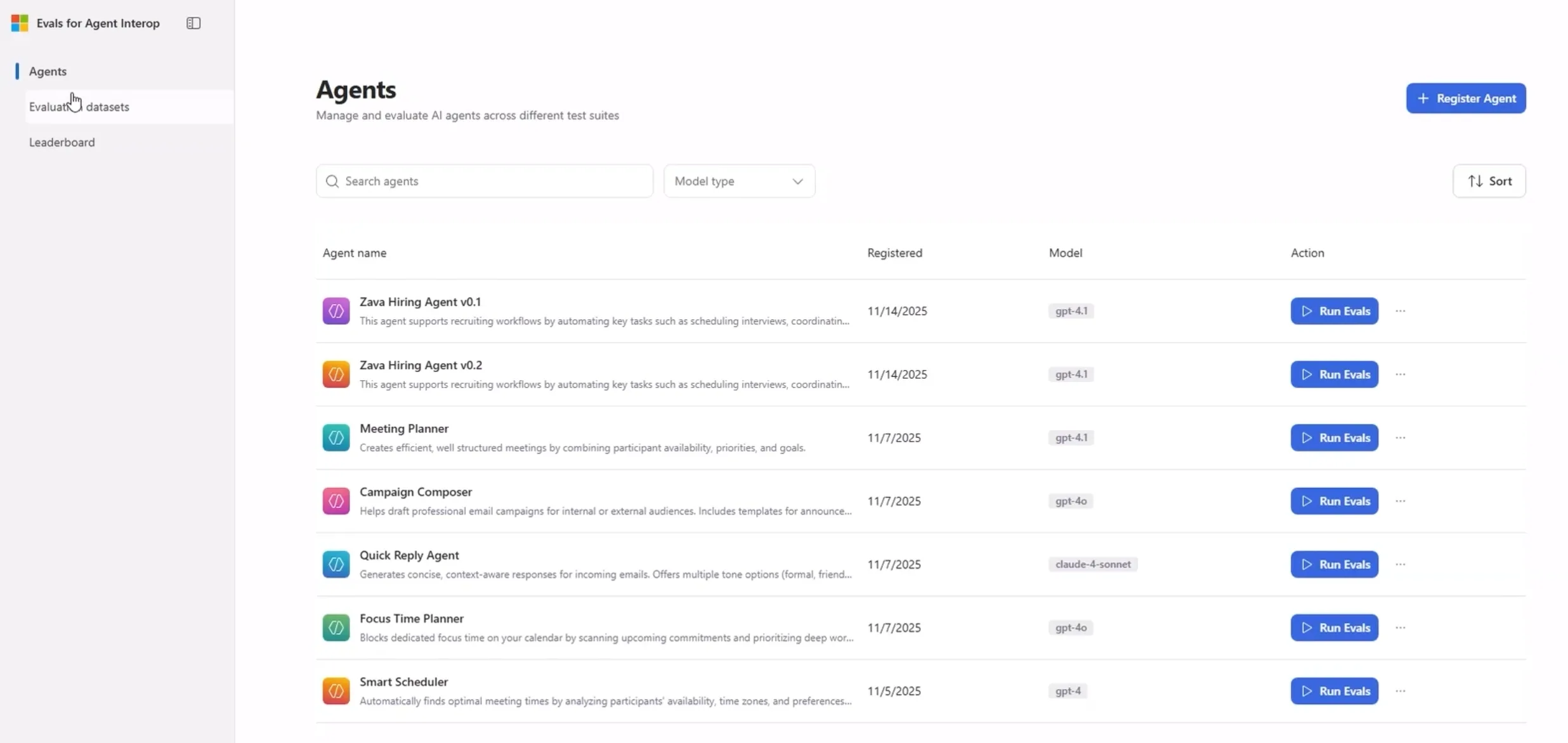
As a first step, we’re launching ‘Evals for Agent Interop’, a starter evaluation kit debuting. ‘Evals for Agent Interop’ provides curated scenarios and representative data that emulate real digital work, along with an evaluation harness that organizations can use to self-run their agents across Microsoft 365 surfaces (Email, Documents, Teams, Calendar, and more). It’s designed to be simple to start, yet capable enough to reveal quality, efficiency, robustness, and user experience tradeoffs between agent implementations, so organizations can make informed choices quickly.
Get started: Download the starter evals and harness from our repo. We currently support Email and Calendar scenarios, and we’re rapidly expanding the kit with new scenarios, richer rubrics, and additional judge options. (https://aka.ms/EvalsForAgentInterop).
Leaderboard: Strawman agents, frameworks, and LLMs
To help organizations benchmark and compare, we’re introducing a leaderboard that reports strawman agents written using different stacks, a combination of agent embodiment frameworks (ex., Semantic Kernel, Lang Graph) and LLMs (ex., GPT 5.2). This gives organizations a clear view of how various approaches perform on the same scenarios and rubrics. The leaderboard will evolve as we add more agent types and frameworks, helping organizations determine the right set of agents for their Agent 365 Tools.
Why it matters
Customers want to more easily optimize their AI agents to their unique business. Enterprise AI is shifting from isolated model metrics to customer-informed evaluation. Businesses want to define rubrics, calibrate AI judges, and correlate offline results with production signals, tightening iteration cycles from months to days to hours. As Microsoft, we realize that customers expect to bring their own grading criteria and scrutinize datasets for domain fit before they trust an agent in their environment. ‘Evals for Agent Interop’ is purpose-built for this new reality, unifying evaluation needs in one path: start with pre-canned evals, then tailor to your context.
How Evals for Agent Interop works
‘Evals for Agent Interop’ ships with templated, realistic and declarative evaluation specs. The harness measures programmatically verifiable signals (schema adherence, tool call correctness, policy checks) alongside calibrated AI judge assessments for qualities like helpfulness, coherence, and tone. This yields consistent, transparent, and reproducible results that teams can track over time, compare across agent variants, and share across organizations.
How it will evolve into a full evaluation suite
We’re building toward a full suite that helps organizations choose the right set of agents to run on their Agent 365 Tools:
Product teams within Microsoft define rubrics, train and calibrate judges, ship scenarios and data, and correlate offline scores with production metrics.
Customers bring their own data and grading logic via a that becomes the single source of truth for both offline grading and online guardrails at runtime. We’ll support custom tenant rubrics, with LLM or human grading for ambiguous cases.
Packaged governance includes audit trails, documented rubrics, and privacy posture aligned to usage. Over time, we intend to co-publish capability manifests, tool schemas, and calibration methods to foster transparency and community validation.
What can organizations do with the Evals for Agent Interop kit?
With ‘Evals for Agent Interop’, organizations can compare multiple agent candidates head-to-head on the same scenarios and rubrics, quantify quality and risk controls, and verify improvements (for example, a fine-tuned model or a different LLM) before broad rollout. As we expand the suite, these offline signals will align with online evaluation, so organizations can move from confidence to controlled deployment. Faster, safer, and clearer accountability.
Where to start (and what’s next)?
Clone the GitHub repo (https://aka.ms/EvalsForAgentInterop) with the starter evals and Harness. Run the included scenarios to baseline your agents and understand gaps.
Tailor rubrics to your domain, then re-run to see how agent behavior shifts under your constraints.
We’ll expand ‘Evals for Agent Interop’ with new scenario families (document collaboration, communications, scheduling and tasking), richer scoring, and broader judge options, while integrating more tightly with Agent 365 Tools so evaluations and runtime guardrails share one source of truth.
0 comments