
One of the startups in the MSVentures Redmond Accelerator (Lionheart) is interested in supplementing prescription data from other sources by pulling in structured data from pictures of existing prescriptions. For instance, a caregiver taking on a new patient could take a picture of an existing pill bottle and the Lionheart software would be updated with medication, dosage and refill information.
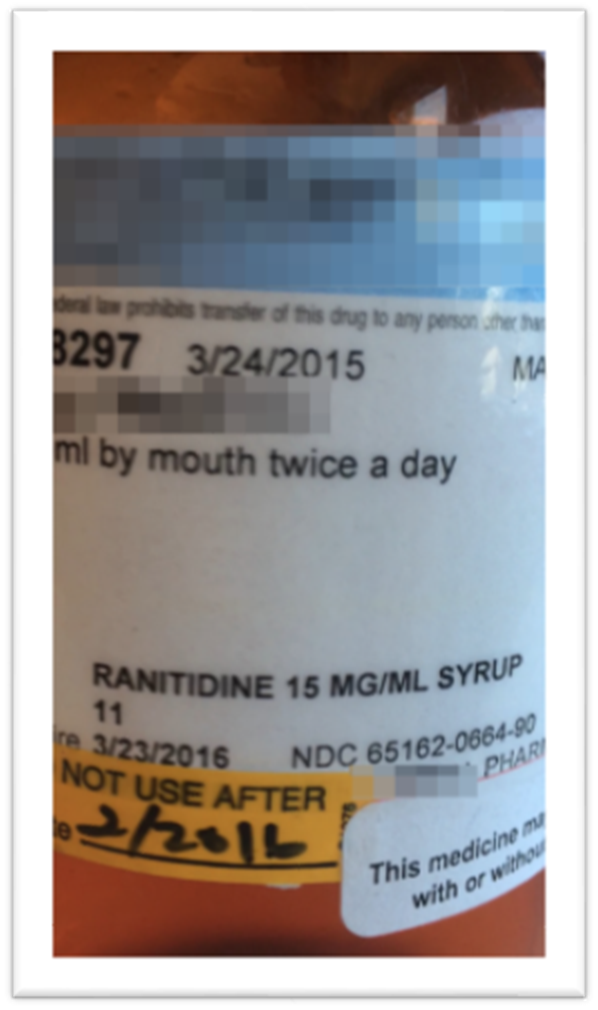
Ideally, we would be extracting information from a clean image, but in reality we would more often be confronted by warped partial images (below) or multiple images attempting to encompass an entire curved surface.
There are three major areas that need to be addressed in order to successfully tackle this problem:
- Successfully derive an “OCR-able” image from a non-standard surface like a small pill bottle
- Develop an OCR solution
- Write an entity extractor and train it on prescription data
Project Oxford provides solutions for steps #2 and #3 through the Vision API and Language Understanding Intelligent Service (LUIS), and this case study will show how to wire those components together to provide a solution, as well as outline some options for tackling problem #1 and similar problems.
Overview of the Solution
To develop the initial solution, we started with the clean image above as a “best case scenario” to determine how well Project Oxford’s Vision API and LUIS would work. The Vision OCR API provides a simple RESTful endpoint for submitting images either via URIs or octet-streams in a variety of formats. Submitting an image results in a payload containing regions identified as containing text, with lines and words within – all with appropriate bounding box information. For instance, with the example image we see:

We extract lines of text from this payload and use them to train a model in LUIS, with intents mapping different components of the prescription, and entities within pulling details out. LUIS is trained by adding “utterances” and labeling them with a given intent, then tagging parts of them as different entities. We can look at images like the above after we’ve extracted lines of text and infer examples – such as “TAKE 1 TABLET BY MOUTH” has an “Instruction” intent, with “1 TABLET” being the dosage amount. Such labeled utterances in LUIS look like the following:
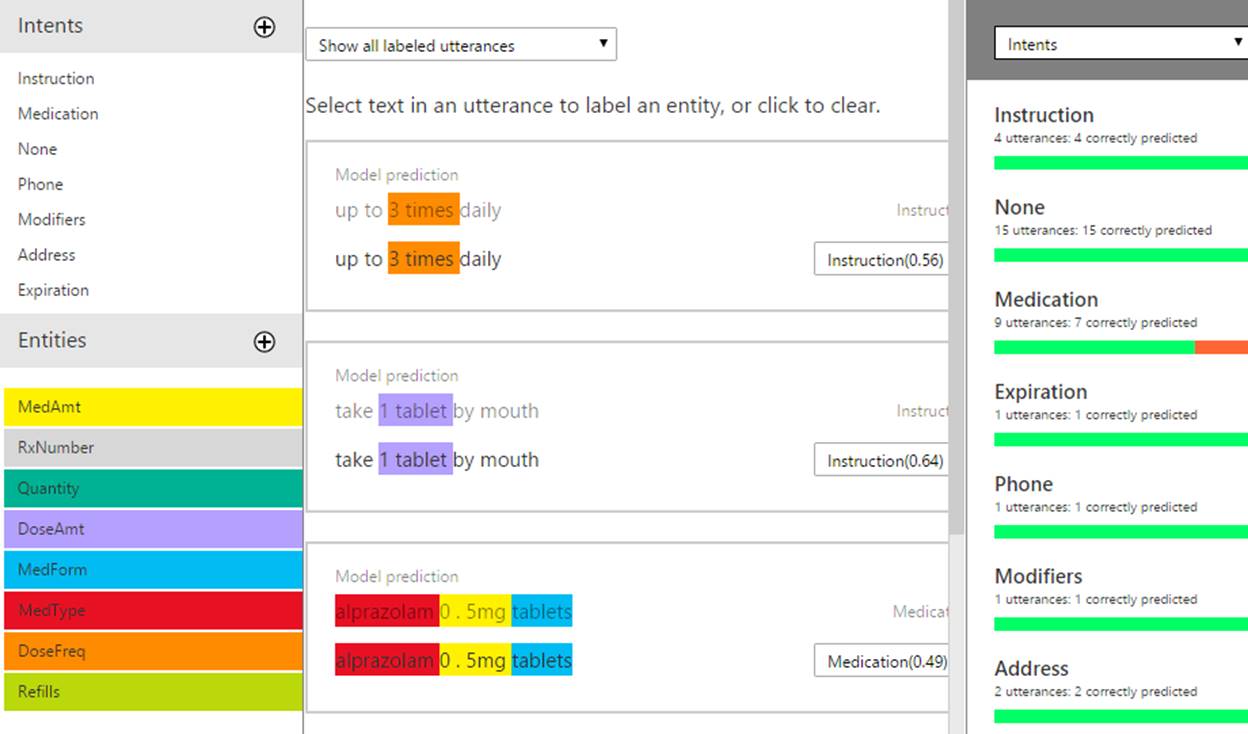
You can see intents and entities clearly labeled, and the latest trained model’s prediction accuracy to the right. Publishing a model allows you to make RESTful calls against it with new utterances and receive back a JSON payload containing any detected entities and predictions with confidence levels of possible intent. We can then use these to build out a Prescription data model with the various medication, dosage, and instruction details we’ve been able to discover.
Once the pipeline from OCR to LUIS is in place, we can attempt to tackle the warped image problem, and here is where we are less successful. One option that has proved promising but is not stable enough to become part of the platform is to take multiple overlapping images of the object to be OCR’d. We then OCR each of the images, pull out the lines from each result, and attempt to map and then merge the resulting lines. This can be done by taking substrings from the end of lines in one result-set and attempting to match them against substrings from the beginning of the subsequent result-set, using different string-distance measures (we’ve tried Levenshtein distance thresholding with some success).
I’ve published a blog post with details of this pipeline as applied to meme images. With memes, a different set of image processing problems occur due to the odd nature of text overlaid on existing images, and I provide some guidance on how to tackle those issues as well via image transformations.
Code Artifacts
Microsoft TED has published all of the code for the general OCR=>LUIS pipeline in GitHub:
https://github.com/noodlefrenzy/image-to-entities
However, some of the code involved in Lionheart’s particular case for image stitching is theirs, and not in that repository.
Opportunities for Reuse
Any situation where a customer is trying to pull structured information from text within images could benefit from this pipeline. For instance, augmenting a Twitter sentiment analysis flow to cope with meme-based images included in tweets. Additionally, you could wire this through to the Oxford Speech API to allow scenarios like helping blind users by pulling text from images and reading it to them.