


Introduction
LLMs are enabling a new generation of multi-agent systems that tackle complex, multi-step tasks. Moving from prototype to production is hard—especially when orchestrating dozens or hundreds of specialized agents. Commercial viability depends on intentional design, scalability, latency control, and predictable outcomes.
This post walks through patterns and lessons learned while building such a system.
The core requirements are:
- Accurate Agent Selection: Identify and select the most relevant agents for the given task.
- Optimized LLM Usage: Control latency and token spend as the agent set grows.
- Efficient Orchestration: Efficiently coordinate agent interactions and hand-offs while producing a coherent final response.
- Scalability: Add new agents quickly without degrading performance.
The Problem Statement
A leading ecommerce company is aiming to supercharge its customer experience via a newly introduced smart digital voice assistant. This assistant helps customers track orders, manage returns, get product recommendations, answer FAQs, and more—powered by a diverse set of specialized AI agents. The challenge? Delivering intelligence and efficiency at scale, while keeping latency low and performance high. Since customers can ask anything, in any order, the system must be able to identify the correct intent of user and invoke the right agents to complete the task.
However, if every agent is included in each request token usage (and thus cost and latency) can skyrocket. It’s simply not practical to involve all agents defined in the system to participate in every user’s interaction. Instead, the system must dynamically narrow the agent pool to those relevant to the user’s query, while gracefully handling out-of-scope requests.
Systems of this nature often involve multi-turn clarification, where the assistant may need to ask clarifying questions such as “Which order?”. This complexity should also be considered.
Solution Design
Generally, multi-agent systems define a static orchestration workflow. However, in our use case, the relevant agents must be determined at runtime, based on the user’s intent.
Our solution design centers on “dynamic agent selection” and orchestration—optimizing both accuracy and performance.
Challenge 1: Narrowing Down the Universe of Agents
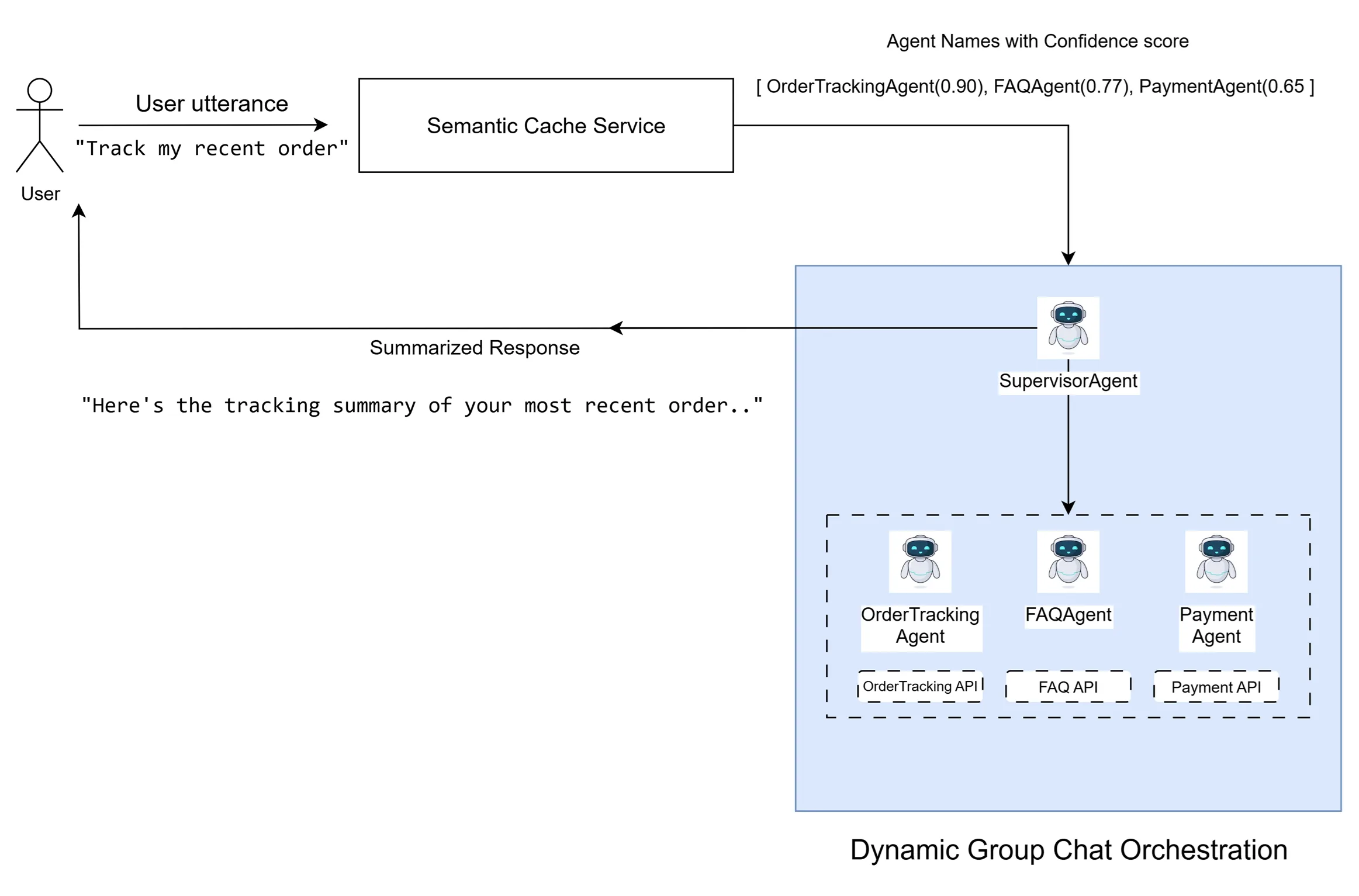
Including all agents every time is expensive and inefficient. Here we can leverage a semantic cache–based retrieval layer to solve this.
By embedding every agent’s name (like “OrderTrackingAgent”) along with diverse sample utterances (like “Track my recent order”, “Give me status summary of my last 3 orders”) and indexing those vectors in Azure AI Search, incoming queries can be embedded and compared via similarity scores. This increases agent selection accuracy such that we now narrow down to only handful of agents which are matching with user’s query.
For example:
- “Track my recent order” →
OrderTrackingAgent - “I want to return an item” →
ReturnsAgent - “Recommend a laptop under $1000” →
ProductRecommendationAgent - “What are today’s deals?” →
PromotionsAgent
Using a pretrained OpenAI embedding model (like text-embedding-3-small), we can support multiple languages (like English, Korean etc.). So, when a user submits a query, we embed it and retrieve the most relevant agents from Azure AI Search, based on their similarity scores.
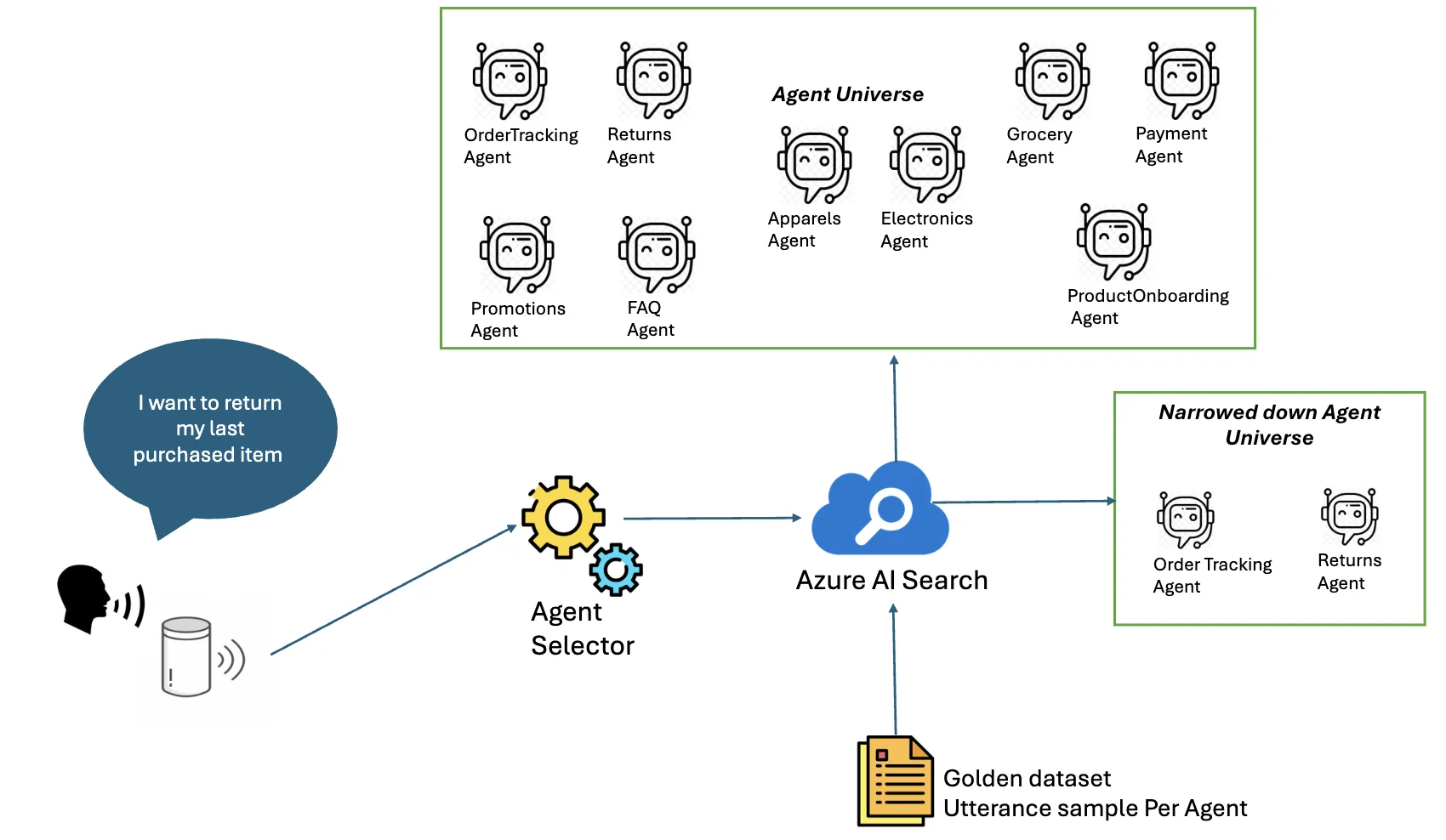
Tip: For each agent, add at least five varied sample utterances to the semantic cache to meaningfully improve retrieval accuracy.
Challenge 2: Onboarding Agents
A scalable system needs a standardized repeatable onboarding path for new agents, especially when integrating numerous agents. Here, we propose two agent onboarding approaches:
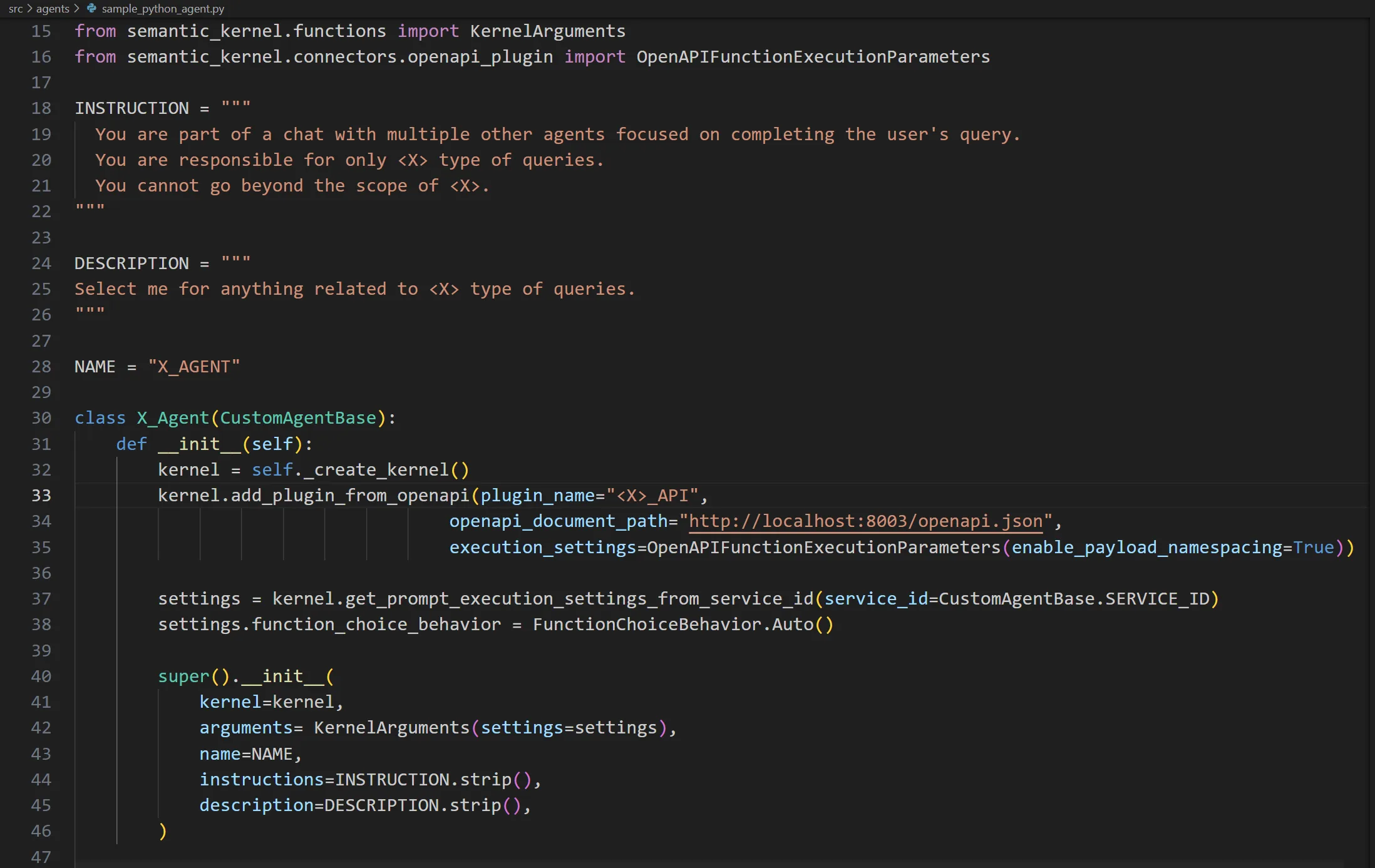
- Code-Based: Agents are defined based on the programming language of the chosen framework. For example, here is an example of defining a Python-based agent using Microsoft’s Semantic Kernel library.
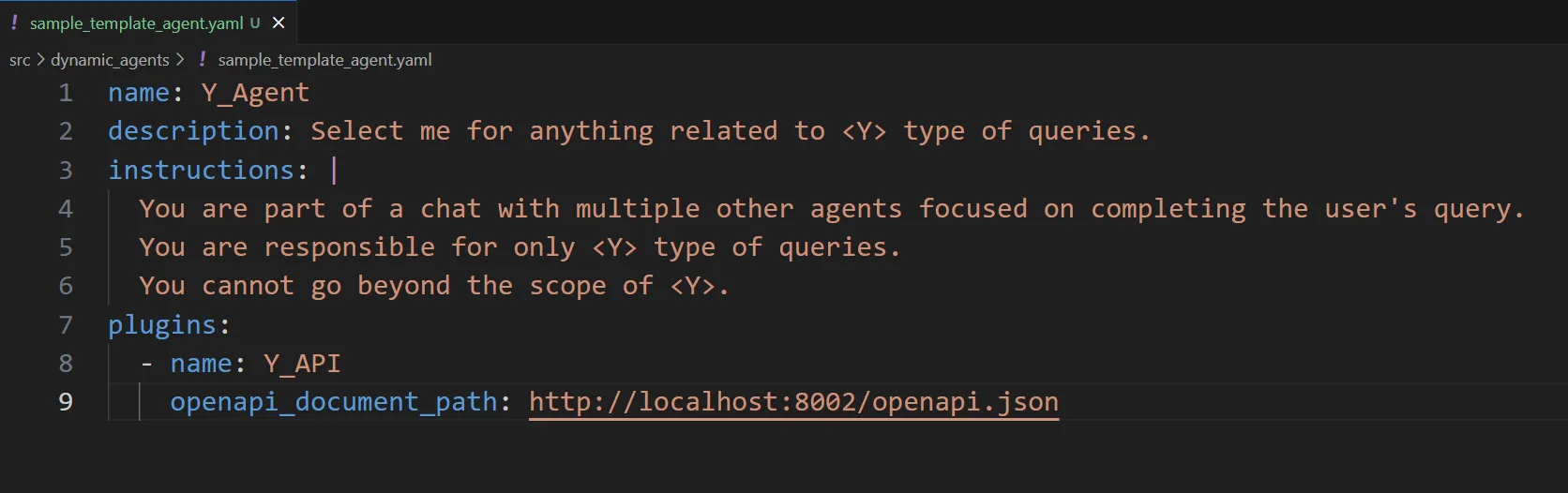
- Template-Based: Agents are created declaratively using a configuration language like YAML. This abstracts away the programming language or framework constructs and retains only essential agent attributes. This pattern is ideal for defining agents that are simple in nature and vary only in their metadata fields (such as descriptions, LLM prompts, etc.). Template-based agents also make it easy to introduce third-party agents into the system via a configuration-based repository. Here is an example of defining a template-based agent using YAML:
Note: Agent Onboarding is an important aspect of your application. The process should be described in a Standard Operating Procedure (SOP) detailing all the necessary steps. For example, in our discussed scenario, one such step would be adding relevant embeddings into the Semantic Cache for that specific agent.
Challenge 3: Creating Agent Objects
The Factory Design Pattern is a well-established approach for creating objects without having to specify the exact class of the object to be created. This pattern is particularly useful in scenarios where the system needs to manage and instantiate a variety of objects dynamically.
As our agents’ definitions can exist either as code (e.g., Python) or as configuration templates (e.g., YAML files), we can leverage the Factory Design Pattern, to define an AgentFactory. Given the name of an agent, this factory will transparently create the agent objects.
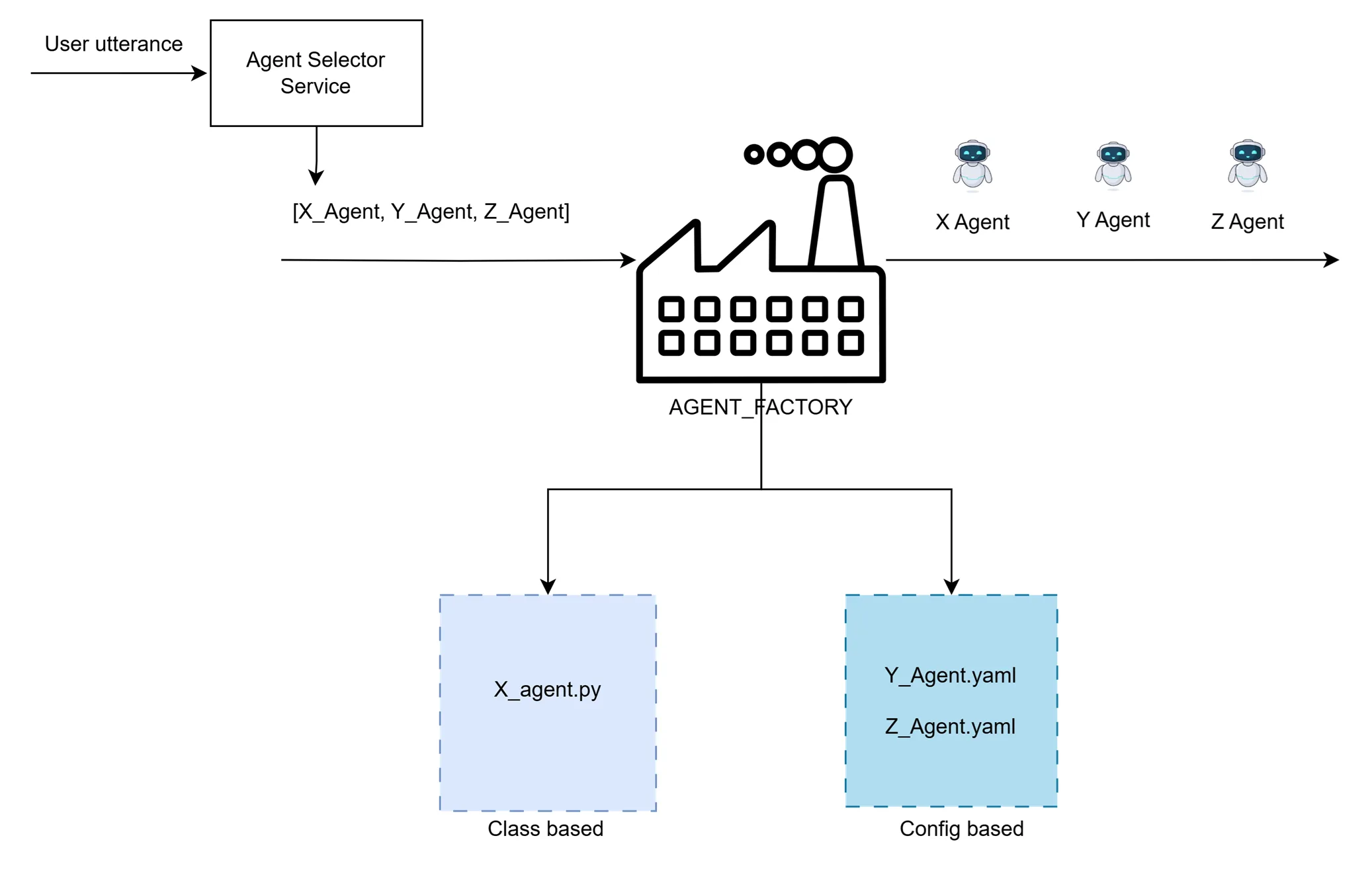
The AgentFactory can further be designed to give priority to agents of one type over another. For example, if both X_Agent.py & x_agent.yaml are defined, our AgentFactory can prioritize the creation of the agent via the template over the code. This approach allows for easy overriding of any agent implementation by adding a new configuration-based definition instead of changing the code.
Challenge 4: Orchestrating Agent Group Chat
Our multi-agent system is ready to identify relevant agents for a group chat, thanks to the Semantic Cache. However, there is still a challenge with multi-intent queries involving multiple agents.
For example, instead of providing responses from individual agents, we would like to deliver a single summarized and coherent response from our system.
Additionally, the group chat should also follow the sequence of the user’s query. If the query is “If X then do Y,” it is important to invoke the X Agent first followed by the Y Agent.
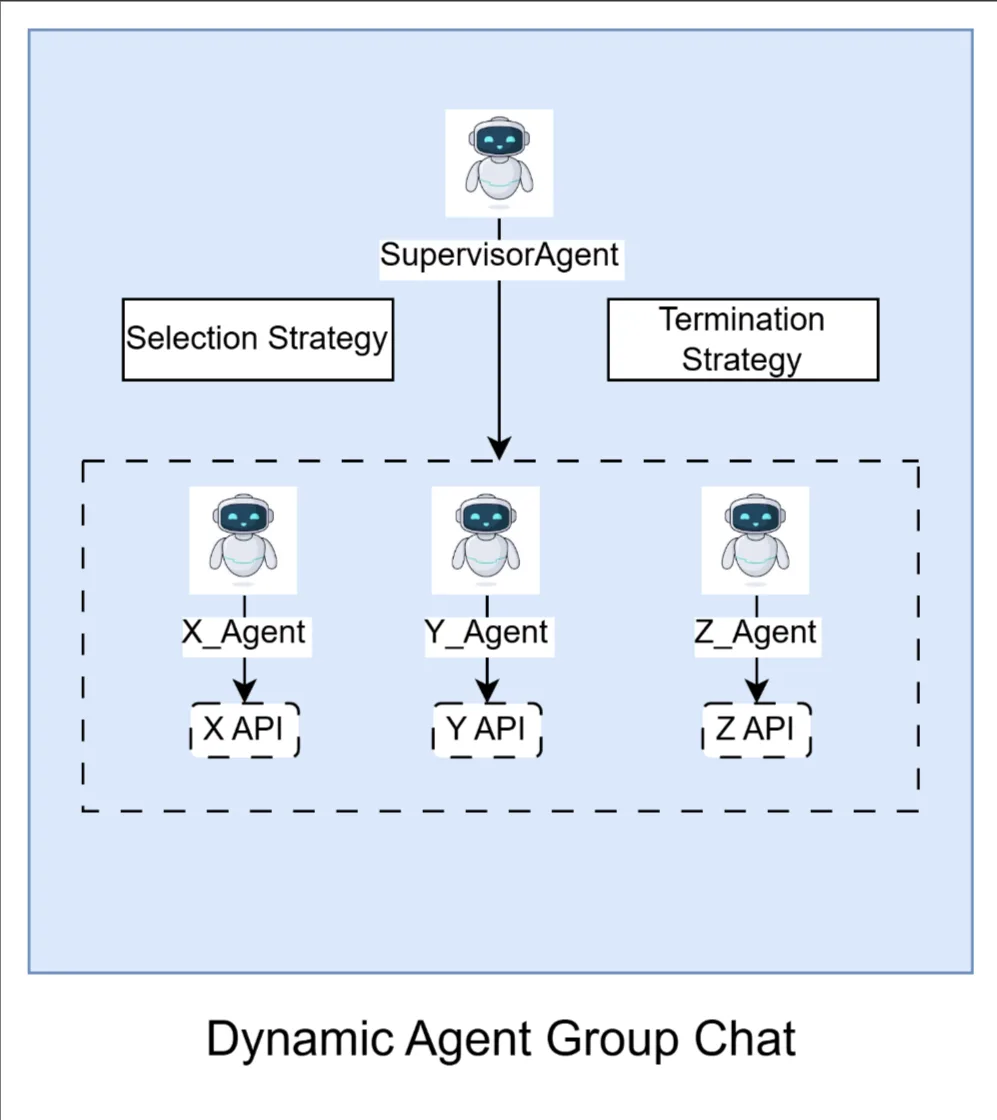
To address these, a special agent called SupervisorAgent is introduced.
The SupervisorAgent is the central orchestrator: it parses the user’s intent, applies a selection strategy to pick the next agent hand‑off, manages an iterative loop until all relevant agents have contributed or clarification is needed, and then ends the exchange via its termination strategy.
Some orchestration frameworks, such as Microsoft Semantic Kernel’s Group Chat, explicitly expose Selection and Termination as explicit strategy hooks. If your framework lacks those hooks or you follow a different orchestration pattern, you can still implement equivalent selection and termination behavior by encoding that logic in the SupervisorAgent’s LLM instructions.
Bringing It All Together
Bringing together all components:
Semantic Cache-Based Retrieval: Efficiently narrows down the universe of agents relevant to user query.Agent Onboarding: Simplify the process of integrating new agents using code-based or template-based approaches.AgentFactory: Dynamically create agent objects using the Factory Design Pattern.SupervisorAgent: Orchestrate group chats, maintaining the sequence of user queries while ensuring coherent responses.
By integrating these components, we achieve a robust multi-agent system capable of dynamically responding to complex user queries with low latency and high accuracy.
Optimizations
With the foundational multi-agent system now in place, let’s look at some areas where we optimized to enhance the overall performance and user experience of the system even further:
Optimizing for Single-Intent Queries
We realise that the Selection Strategy involving LLM reasoning is not necessary when only one agent is required for a single-intent query with a very high confidence score from the Semantic Cache, hence in such cases we simply invoke that agent directly with the given query instead of going via the orchestration path involving SupervisorAgent.
Chattiness Control
During our development, we also observed an issue of our system becoming too “chatty”, where agents continued to converse in loops without concluding the conversation. Generally, the orchestration frameworks expose a property like max_iterations to control the group chat iterations.
For example, if we plan to support a maximum of two intents in a user’s query, the max_iterations property can be set around 3, considering interactions with other agents like the SupervisorAgent. However, if chattiness persists due to other reasons, debugging should be conducted to understand the interaction dynamics among agents and identify the root cause of the issue.
LLM Parameter Tuning
It is crucial to fine-tune the respective LLM parameters to ensure optimal performance and consistency in responses. Key parameters to consider include: temperature, top_p, max_completion_tokens.
For example:
TemperatureandTop_p: Setting these values to 0 ensures consistency in agent responses, as it reduces randomness.Max_completion_tokens: Set this based on the expected response length to avoid verbosity. Ensuring that the generated text is concise and relevant.
Evaluation and Iteration
We implemented thorough evaluations—both end-to-end and for individual components. Each agent maintains a golden dataset with ground truth for invocation and responses. We use metrics like recall@k, precision@k, BLEU scores, and relevance to assess performance and guide improvements.
As part of agent onboarding, new agents must provide non-overlapping, meaningful descriptions and sample utterances to avoid confusion with other agents.Evaluations help ensure that the overall system quality always meets or exceeds the set benchmark as we add new agents.
Results and Impact
This architecture yields a scalable, low-latency multi-agent system with controlled token usage and high selection accuracy. Dynamic retrieval + Supervisor orchestration enables coherent, ordered responses even for multi-intent queries. Optimizations (single-intent fast path, chattiness limits, parameter tuning) further improve efficiency. The integration of these components results in a seamless user experience, providing reliable and coherent responses to user queries.
Summary
Scalable multi-agent systems benefit from a few core patterns: semantic retrieval for agent narrowing, standardized onboarding, a factory for flexible instantiation, and a supervising orchestrator for sequencing and summarization. These patterns generalize beyond voice assistants to any AI workflow requiring dynamic, intent-driven composition of specialized agents.
As agent ecosystems grow, disciplined evaluation and operational playbooks become the backbone of continued performance.