
Partner Scenario – Guide Dogs
As explained in the previous code story Building an AR navigation system for visually impaired users with Elasticsearch, we have partnered for two years with Guide Dogs in the UK to build Cities Unlocked. Cities Unlocked enables visually impaired users to navigate cities independently with the use of an iOS mobile app, remote control and a custom headset. The app uses spatial audio to provide contextual information about an area and navigation instructions, empowering people to explore the world around them more easily and independently. An important constraint is that the user must be able to interact with the app while the phone is in a pocket or bag. Because users can control the app via their voice or a hardware remote control, their hands are free to hold a cane or guide dog harness.
What to expect from this code story:
- Overview of speech recognition technologies on iOS
- Explanation of the speech recognition architecture used for Cities Unlocked
- Opportunities for reuse of this architecture on any platform or language
- Open-sourced example of our solution on GitHub
- Objective-C integration of Cognitive Services Speech-to-Text
- Objective-C integration of iOS 10 Speech SDK
Problem
Developing a great speech recognition solution for iOS is difficult. Until iOS 10 there was no official API, and you had to rely on third-party solutions that had many limitations. With iOS 10, developers can now access the official Speech SDK, but there are restrictions, and you have no control over the usage limit.
Cities Unlocked required a responsive, audio-driven user interface. The users keep their phones in their pockets, and with the help of a headset, they can issue commands such as “Take me to Starbucks,” “What is around me?” and “Where am I?”. The solution must be able to understand entities like Starbucks and figure out the intent even with different ways of asking the same question.
With so many constraints and requirements, we considered the following factors:
- Quality of recognition
- Speed of recognition
- Intent extraction from complex phrases
- Silence detection
- Offline/Online mode
- Live partial results
- Price of usage
- Usage limits
There are several speech recognition libraries available on the market, but the ones that performed the best were OpenEars, Cognitive Services STT and iOS 10 Speech SDK.
OpenEars + RapidEars (plugin) is great for offline support and you only need to pay a fixed fee to use it. It has built-in silence detection and partial results, but it relies on a pre-defined array of words and phrases. As stated on the OpenEars website, “Because of the optimizations that are needed to do instant recognition on the iPhone, its live recognition does not quite have the accuracy rates of OEPocketsphinxController in the stock version of OpenEars (its final recognition is the same, however) and should be used with smaller vocabularies.” This library is good for a small number of commands, but it does not allow recognition of complex phrases and natural language processing that our solution required.
iOS 10 Speech SDK is a new SDK released by Apple that has partial recognition and very good quality. You need to implement your own silence detection, and you have a limit on how much you can use this service. At the moment there are no exact numbers: “Individual devices may be limited in the number of recognitions that can be performed per day and an individual app may be throttled globally, based on the number of requests it makes per day.” This setup is a big problem if you want to scale the solution globally and for our scenario in particular, where visually impaired users rely completely on the speech commands to orientate themselves and consequently any service failure is unacceptable.
Cognitive Services STT is a client library for iOS that uses the Microsoft Bing Speech API. This library has an excellent quality of recognition, silence detection, partial recognition, and integration with LUIS (interactive machine learning and language understanding from Microsoft Research) that enables complex intent extraction with entities support. The biggest shortcoming is that Cognitive Services STT has no offline support. However, because our app is intended to be used exclusively outdoors (and relies heavily on other services), this was an acceptable limitation.
With the above considerations, the Cognitive Services STT was the best choice for our solution. The quality, control, built-in features, and LUIS integration were crucial to creating Cities Unlocked.
Overview of the solution
Architecture
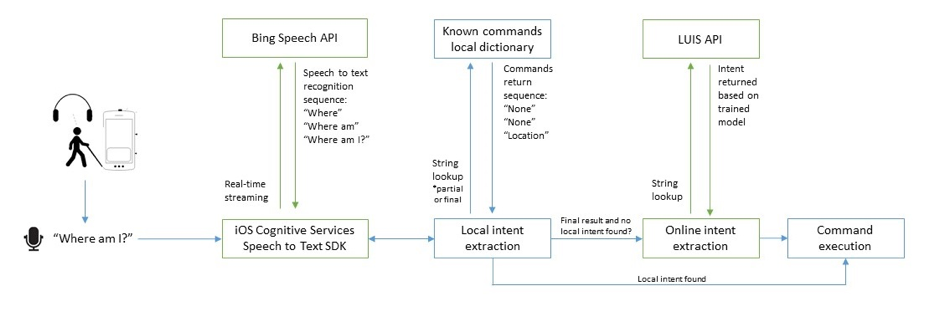
We used the iOS Cognitive Services Speech SDK to establish a real-time stream and return partial and final string results as the user is speaking. We did local intent extraction using a cache system and online intent extraction using LUIS. In the image above, the green color represents the layers handled by the Cognitive Services SDK on iOS.
This solution was specific to iOS, but there is no reason why this can’t be used in any other platform or language. The intent extraction layers are platform-agnostic, and LUIS provides web APIs that can be accessed from anywhere. Cognitive Services is also cross-platform, but that layer can easily be swapped with a platform-specific speech-to-text library if needed. Check the GitHub repo for an example of how to swap this layer with the iOS Speech SDK on iOS 10.
You can also opt out of the online intent extraction layer, but doing so will mean that your app will only be able to recognize simple commands like “play” and “pause”.
For a similar architecture on Android, check out the Smart Conversation Client. In that code story, we show how you can cache the results from the online intent layer so it can be used in offline mode.
Local intent extraction
To take advantage of the partial results and to greatly improve performance, we used a local dictionary that contains frequently used phrases and their intent. For example:
| Phrase | Intent |
|---|---|
| “Where am I?” | Location |
| “What’s in front of me? | Orientate |
| “What are the points of interest in front of me? | Orientate |
This approach allows us to match the intent while a user is speaking and issue the command immediately. If a match is found, there is no need to wait for silence detection, and it makes the user experience seamless.
Online intent extraction
People have different ways of asking for the same thing. We used LUIS to train a model specific to our scenario and to return intents based on a wide range of phrases. Our model also identifies entities in phrases like “Take me to my office.”
The solution gets better and better over time as users issue different commands. LUIS provides a web management portal that allows administrators to analyze intent queries and update the model to improve the results over time.
Implementation
This code story has an example of how to use the Cognitive Services API as well as the new iOS 10 Speech SDK: select the version that fits your requirements best. Cities Unlocked was written in Objective-C to take advantage of other libraries and easy integration to C++. For this reason, both of the examples we wrote are in Objective-C.
Listening to speech with Cognitive Services
To get started with Cognitive Services, go to the GitHub repo and follow the tutorial to set up your keys for Bing Speech API and LUIS. If you want to use iOS 10 Speech SDK for capturing speech instead, skip to the next section of this code story.
Once you have added the framework, you can add the speech recognition protocol to any class. In our example, we used the main page view controller for simplicity:
#import <SpeechSDK/SpeechRecognitionService.h>
@interface MainPageViewController : UIViewController <SpeechRecognitionProtocol>
You now need to add the callbacks in your implementation file:
* Called when the microphone status has changed.
* @param recording The current recording state
-(void)onMicrophoneStatus:(Boolean)recording
* Called when an error is received
* @param errorMessage The error message.
* @param errorCode The error code. Refer to SpeechClientStatus for details.
-(void)onError:(NSString*)errorMessage withErrorCode:(int)errorCode
* Called when a partial response is received
* @param response The partial result.
-(void)onPartialResponseReceived:(NSString*) response
* Called when a final response is received.
* @param response The final result.
-(void)onFinalResponseReceived:(RecognitionResult*)response
* Called when a final response is received and its intent is parsed from LUIS
* @param result The intent result.
-(void)onIntentReceived:(IntentResult*) result
The main speech client is called MicrophoneRecognitionClient* and it is responsible for starting/stopping the microphone and triggering the callbacks above. You can initialize the client to use .wav files or microphone data with/without online intent extraction. For our scenario, we are using the microphone data with LUIS integration. You do not need to worry about reaching the LUIS endpoints because the framework will handle that for you. Nice and easy!
// The microphone client for Cognitive Services.
MicrophoneRecognitionClient* _micClient;
/* The language of the speech being recognized. Change for a different language. The supported languages are:
* en-us American English
* en-gb: British English
* de-de: German
* es-es: Spanish
* fr-fr: French
* it-it: Italian
* zh-cn: Mandarin Chinese */
_cognitiveSpeechServicesLocale = @"en-us";
_micClient = [SpeechRecognitionServiceFactory createMicrophoneClientWithIntent:_cognitiveSpeechServicesLocale
withPrimaryKey:primaryKey
withSecondaryKey:secondarykey
withLUISAppID:luisAppId
withLUISSecret:luisSubscriptionId
withProtocol:(self)];
The last part missing is to trigger the microphone. You could trigger it with a user-invoked command like a button in the UI, or, in our scenario, a remote control with multiple buttons. The user presses the “Start Listening” button and issues a command. This method prevents the app from listening all the time, using resources and triggering unwanted commands.
- (IBAction)StartListeningButtonPressed:(id)sender
{
OSStatus status = [_micClient startMicAndRecognition];
if (status) {
// We could not start the microphone, display the error.
}
}
At this point, the app will listen to user speech and translate it into text which will be returned in real time in the onPartialResponseReceived callback. When the user stops the microphone or silence is detected, the final string will be sent to onFinalResponseReceived. We now need to issue commands based on what the user said.
Listening to speech with iOS 10 Speech SDK
If you wish to use the iOS 10 Speech SDK, you can find an Objective-C integration of this SDK in the GitHub repo. It follows the same architecture but does not rely on the Bing Speech API to return string results. Please note that it does not have silence detection so the user must press the stop listening button when the phrase is complete.
For more information on this SDK, please see the official video from Apple.
Local intent extraction
When a partial recognition is returned, we need to check if the text matches an intent. We developed a simple but efficient solution that uses a dictionary to hold the key as the phrase and the intent as the value. This method allows very fast lookup, O(1), for any phrase and only returns exact matches.
// Info.plist
<key>RapidCommandsDictionary</key>
<dict>
<key>where am i</key>
<string>Location</string>
<key>what's around me</key>
<string>Orientate</string>
</dict>
// MainPageViewController.m
@property (nonatomic, nullable) NSDictionary * rapidCommandsDictionary;
_rapidCommandsDictionary = [mainBundle objectForInfoDictionaryKey:@"RapidCommandsDictionary"];
In this example, we used the Info.plist to populate the commands dictionary. This setup is great for prototyping and simple commands, but we recommend using telemetry to keep track of the frequently used phrases and populate the local list when the app has a good internet connection. This tracking can be done using popular frameworks like Application Insights and Google Analytics.
We check each result and look for a match in the dictionary:
-(void)onPartialResponseReceived:(NSString*) response
{
[self updateText:response forUIElement:PartialResultTextView];
if([self tryAndRecognisePhrase:response])
{
// Issue the command and update your state machine.
[self updateText:[NSString stringWithFormat:@"Action succesfully issued: %@, using local dictionary matching.", (NSString*)[_rapidCommandsDictionary objectForKey:[response lowercaseString]]] forUIElement:ActionIssuedTextView];
// We issued a command. End the mic recognition.
[_micClient endMicAndRecognition];
}
}
- (Boolean)tryAndRecognisePhrase:(NSString *)phrase
{
if([_rapidCommandsDictionary objectForKey:[phrase lowercaseString]])
{
_commandExecuted = YES;
}
return _commandExecuted;
}
Here _commandExecuted is used to keep track of whether we executed the command in partial recognition. When you stop the microphone, onFinalResponseReceived is triggered automatically and we need to prevent firing the same action twice.
-(void)onFinalResponseReceived:(RecognitionResult*)response
{
// Check if the partial recognition issued a command.
if(!_commandExecuted)
{
[self updateText:@"Command was not found in local dictionary." forUIElement:ActionIssuedTextView];
}
}
Online intent extraction
When a phrase is not recognized locally, we take advantage of LUIS to extract the intent further. The model must be trained for your individual project, and there is a great video on how to do it available.
Cognitive Services comes with LUIS integration, and you only need a valid API key when you initialize the microphone client. After each final result, the framework will send the string to LUIS to extract the intent which is returned in the onIntentReceived() callback in JSON format.
-(void)onIntentReceived:(IntentResult*) result
{
// We already executed a command, LUIS is not needed.
if(_commandExecuted)
{
return;
}
NSString *finalIntentName = @"NONE";
NSError *e = nil;
NSDictionary *jsonDict = [NSJSONSerialization JSONObjectWithData:[[result Body] dataUsingEncoding:NSUTF8StringEncoding] options:NSJSONReadingMutableContainers error:&e];
NSArray *intentsArray=[jsonDict objectForKey:@"intents"];
for (NSDictionary * intent in intentsArray)
{
NSString * scoreString = (NSString*)[intent objectForKey:@"score"];
NSString * intentName =(NSString*)[intent objectForKey:@"intent"];
double score = [scoreString doubleValue];
if([intentName length] > 0)
{
finalIntentName = [intentName lowercaseString];
[self updateText:[NSString stringWithFormat:@"Intent received: %@ nConfidence level: %f", finalIntentName, score] forUIElement:LuisResultTextView];
break;
}
}
if(finalIntentName && [self tryAndRecognisePhrase:finalIntentName])
{
[self updateText:[NSString stringWithFormat:@"Action succesfully issued: %@, using LUIS intent extraction.", [_rapidCommandsDictionary objectForKey:[finalIntentName lowercaseString]]] forUIElement:ActionIssuedTextView];
}
else
{
[self updateText:@"The intent returned from LUIS was not found in the local dictionary. If appropiate, include this intent in the RapidCommandsDictionary, or train the model." forUIElement:ActionIssuedTextView];
}
}
We deserialize each result into an intent name and intent score. The score tells you how confident the API is of this intent and you can filter out results based on this score (for example, only use intents that are 90+% sure).
The intent name is the string that we defined in the LUIS model, and we check if it matches our commands dictionary. You need to make sure the two are in sync. For example, if you add a new intent in LUIS, you must update your commands dictionary to understand it.
Conclusion
Using the Cognitive Services Speech API combined with a local cache and LUIS has proven to be a very robust and reliable solution for voice commands on iOS. In trials, blind users tested out this solution and the feedback was fantastic. It gives full control over the usage, as well as how much you are spending. With the help of LUIS and telemetry, developers can improve the language understanding model as more users try the app.
Opportunities for Reuse
This solution is reusable on any platform or in any language. You can use the web APIs for LUIS and swap the SpeechToText layer with any platform specific library.
The code example for our iOS solution is open source and available on GitHub. It also contains an integration of the iOS 10 Speech SDK in Objective-C.