
This blog is co-authored with Ehsan Zare Borzeshi and Omri Mendels
Introduction
A Systematic Literature Review (SLR) aims
to collate all the empirical evidence that fits pre-specified eligibility criteria in order to answer a specific research question. It uses explicit, systematic methods that are selected with a view to minimizing bias, thus providing more reliable findings from which conclusions can be drawn and decisions made
SLRs are heavily used when treatments are selected, in creating clinical guidelines, and in drug regulatory and licensing processes. They are the most reliable way of ensuring that treatment decisions are informed by current knowledge. Because treatments are advancing all the time, and tens of thousands of new research studies are published each year, it is important that SLRs are maintained up to date.
However, conducting a SLR requires a significant manual effort. Once completed, maintaining it with the latest relevant content is a necessary but labor-intensive process. Having some level of automation to recommend novel studies that are potentially relevant to researchers – as soon as they are published – would be highly beneficial for the research community.
To do so, the EPPI-Centre in University College London (UCL) developed a software application, called EPPI-Reviewer, which is used by many academic and industry researchers across the globe to manage data for SLRs. EPPI-Reviewer helps users to find studies, assess their reliability, and generate new knowledge. This creates value for researchers, policy makers and practitioners operating across health care, food, pharma, environment, education, chemical and other human safety related industries.
The EPPI-Center partnered with the Commercial Software Engineering (CSE) team in Microsoft to develop a recommender system for suggesting new scientific papers to researchers based on the reviews they already own, which contain the literature items they had previously selected in response to a certain research question.
The project utilised the Microsoft Academic Graph (MAG) dataset, which has recently been released under a Creative Commons license. This dataset of more than 250 million scientific articles is constantly updated as new papers are published. It is a potentially comprehensive, and regularly updated source of research papers and, as such, could be an ideal source of data for keeping reviews up to date.
This blog focuses the journey that UCL and CSE went on to drive Machine Learning models from research to production, covering the problem formulation and several approaches to data preparation using the MAG dataset, modelling, and operationalization.
Problem Formulation
The domain entities are papers and reviews. Specifically, a review comprises a curated collection of papers that are relevant to a certain scientific question. The task is about recommending brand new papers to reviews owners based on their relevance to the scientific questions. More formally, the problem to address is the following:
Given a set of reviews R, a set of papers Pr for each review r∈R and a set of new papers Pnew, the task is about finding a set of pairs (p, r) such that p ∈ Pnew , r ∈ R and p is relevant to r based on Pr.
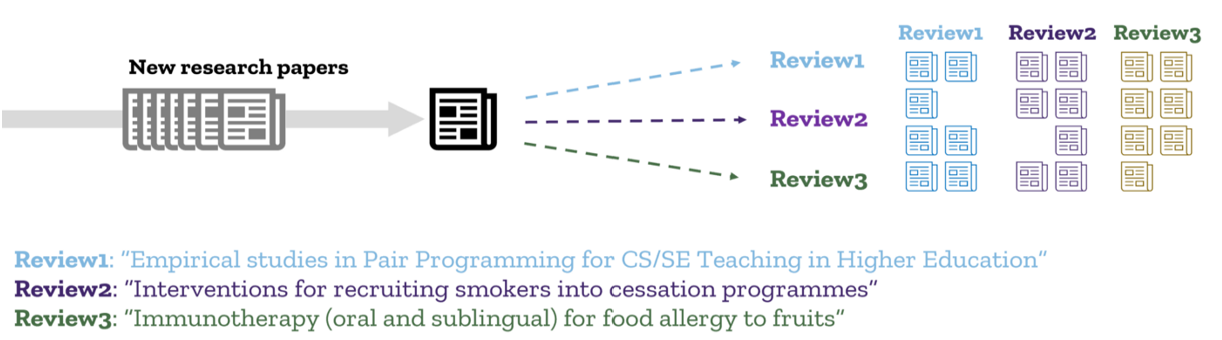
Use case
The following aspects describe the use case for an end-to-end production system:
- Train a model to infer relevance of papers to reviews, based on a supervised dataset.
- Maintain the supervised dataset with new knowledge as soon as it is tracked by reviewers in EPPI-Reviewer and it can be matched to external sources for enrichment (i.e. MAG metadata, the Cochrane’s PICO ontology and potentially others).
- Periodically acquire new papers from MAG and score them with the production model to infer relevant recommendations.
- Provide a new reviews related functionality in EPPI-Reviewer, that suggests lists of new papers ranked by relevance.
Data
~800 reviews have been selected from EPPI-Reviewer on different topics about public health. Each of them has a sufficient relevant papers (at least 40) for training purpose. In addition, MAG provides relational data from about 250 million research papers in many automatically generated “fields of studies” and connected through a citation network. Thus, it supports data enrichment. The PICO classifications provide another source for data enrichment. A data pipeline compiles a supervised dataset of papers, with the following properties:
- Paper’s title
- Paper’s abstract
- Authors
- Field of Studies
- References
- Citations
- Journal
- Conference
- PICO labels
Supervision comprises both positive and negative cases – i.e., pairs (p, r) of a papers p and a review r, being positive (negative) if p is (not) relevant to r. Positive cases have been manually labelled by reviewers, and stored in EPPI-Reviewer. For each positive case, 10 negative cases are automatically constructed as pairs of non-relevant papers and reviews, where:
- A paper is relevant to some different reviews.
- A paper is not relevant to any review – i.e., it has been randomly sampled from the MAG.
Solution Architecture
The recommender system architecture (Fig. 1) comprises data pipelines to process MAG data, train models, and produce recommendations. The architecture consists of a data science experimentation environment and a production environment.
The data science environment enables rapid prototyping of experiments. It consists of Jupyter notebooks examples and templates that support modelling approaches, Azure ML datasets and MLFlow experiment tracking.
The production environment comprises Data pipelines in Azure Data Factory (ADF) that orchestrate data processing operations, including data enrichment, model training and recommendation of new papers. Data enrichment and papers recommendations are performed at scale in Azure DataBricks, while Azure Machine Learning (AML) trains the model.
Both the environments share a Python package (called ContReview), that holds domain functions like logic for accessing datasets, features encoding, models logic, and evaluation.
The diagram below shows the production architecture.
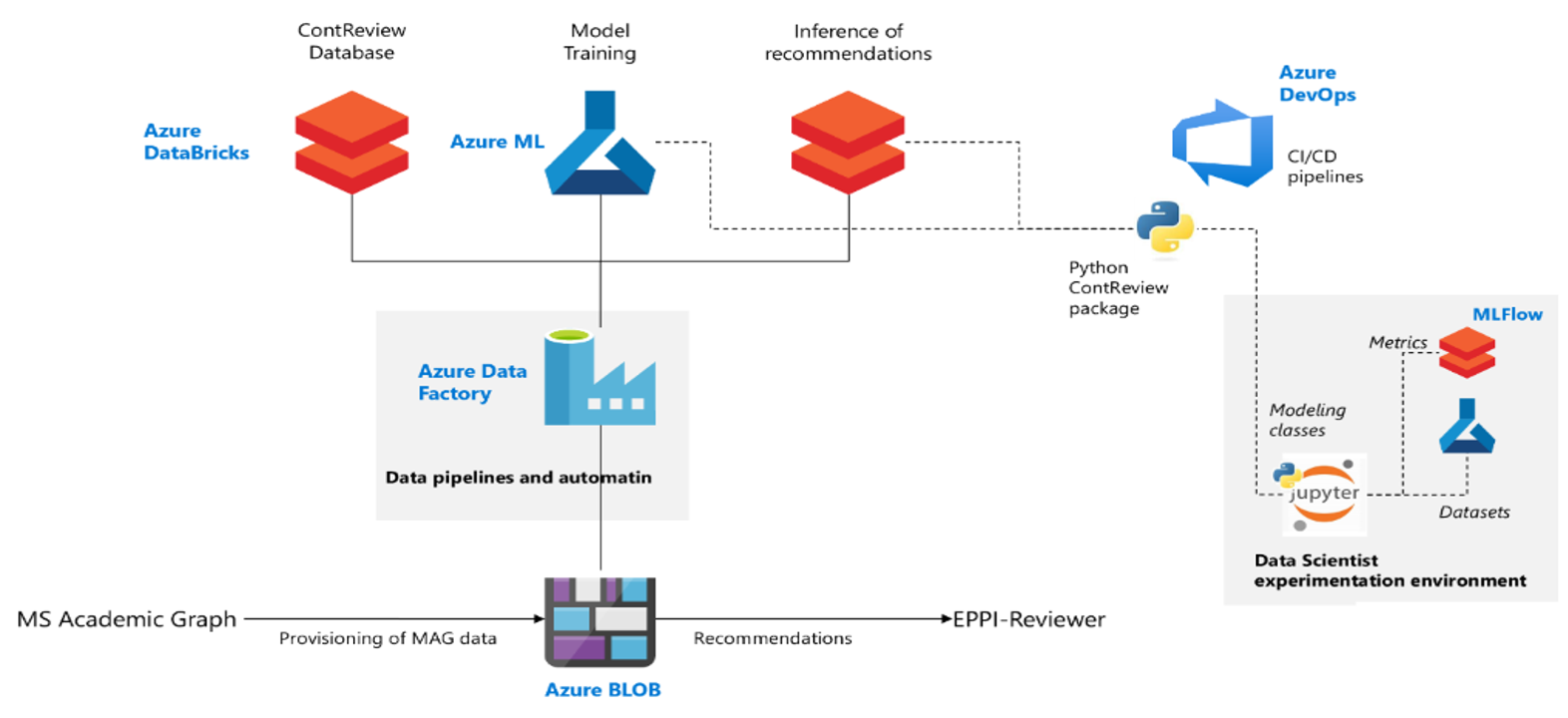
Fig. 1 – System architecture. The left-hand side shows the production pipeline. Azure DevOps stores and triggers CI/CD pipelines. The bottom right-hand side shows the experimentation environment. The Python ContReview package is the linking factor between the experimentation environment and the production environment.
A Storage Account stores MAG updates received periodically (i.e. every 2 weeks). They consist of a set of new scientific papers crawled over the web and organized within the academic knowledge graph. A recommendation pipeline and a training pipeline are available in Azure Data Factory to process the new papers.
The recommendation pipeline uses the model registered to Azure ML within an Azure DataBricks notebook to perform the following:
- Extract the list of new papers from MAG and enrich them with their own features.
- Use the production model within a Pandas User Defined Function (UDF) to calculate the relevance of each paper to each review.
- Use a threshold on relevance scores to filter the most appropriate recommendations for each review.
- Recommend papers to reviews in EPPI-Reviewer, ranked by relevance.
Pandas UDFs score papers directly in a Spark data-frame, instead of delivering a potentially very large data-frame to Azure ML for batch scoring. In addition, Pandas UDF provided considerably better performance over traditional UDFs. In fact, they apply processing logic over batches of rows instead of single rows. Thus, they reduce the overhead due to invoking functions logic and passing parameters. The following code snippet shows the Pandas UDF usage.
# Load the model from AML with a ContReview class
loaded_model = PerReviewTFIDFPerPaperModel.load("{}{}".format(local_path, model_file_name))
# Broadcast the model to all nodes
broadcasted_model = sc.broadcast(loaded_model)
# Declare a Pandas UDF
@pandas_udf(StringType())
def predict(paper_ids, titles, citations, fos, authors, abstracts):
"""
Perform prediction on a subset of papers
:param paper_ids: List of paper_ids for the papers subset
:param titles: List of titles for the papers subset
:param citations: citation values for the papers subset
:param fos: field of study values for the papers subset
:param authors: author values for the papers subset
:param abstracts: abstracts for the papers subset
:return: pd.Series with all predictions, ignoring predictions with score lower than acceptance_threshold
"""
# Load the model from the broadcast variable
model = broadcasted_model.value
# In a Pandas-UDF vectorized function each in/out parameter is a pd.Series type.
papers = [Paper(paper_id=paper_ids[i],
title=titles[i],
citations=citations[i],
fos=fos[i],
authors=authors[i],
abstract=abstracts[i]) for i in range(len(paper_ids))]
# Make the prediction
all_predictions = [model.predict(paper) for paper in papers]
# Filter predictions on a threshold
selected_predictions = [format_prediction(prediction, acceptance_threshold) for prediction in all_predictions]
return pd.Series(selected_predictions)
# Make inference on dataframe df_inference_set
df_inference_set_scored = df_inference_set.withColumn("Inference", predict(
col("PaperId").cast(StringType()),
col("PaperTitle"),
col("Citations"),
col("coFoS"),
col("Authors"),
col("Abstract"))) \
.filter(col("Inference") != '')
Comment to the code: the load method in the PerReviewTFIDFPerPaperModel object (defined in the ContReview package) is used to load the model from AML, so that it can be broadcast to all nodes in the cluster via sc.broadcast. The main Pandas UDF code is in the predict function (note the decorator): as it receives some Pandas Series objects as arguments (one per paper properties), it has to explicitly extract individual papers properties from there (e.g. paper_id=paper_ids[i]) and pass them to a Paper object constructor. The actual code that performs predictions is all_predictions = [model.predict(paper) for paper in papers] where model is the broadcasted model. all_predictions will be a list of recommendations (i.e. a list of pairs of a review and a recommendation score), that will be filtered on a threshold by calling format_prediction (the code is omitted for simplicity).
When new supervised data is available from EPPI-Reviewer, a training pipeline serves to enrich papers in the new supervised dataset and re-trains the model.
The following picture shows the ADF pipeline, that orchestrates Azure DataBricks notebooks and Azure ML pipelines:
- The first task (Azure DataBricks) parses arguments, checks consistency, and selectively runs the forthcoming workflow depending on the user’s intent.
- Prepare Data (Azure DataBricks) constructs a Parquet based subset of MAG for processing datasets. It runs once each time MAG is updated.
- Process Train set (Azure DataBricks) enriches a supervised dataset from EPPI-Reviewer with MAG data, using the Parquet repository.
- Train Python Model (Azure ML) trains a model over a supervised dataset available as a BLOB.
- Process the Inference Set (Azure DataBricks) extracts new papers from MAG, enriches them and produces a dataset for inference.
- Score the Inference Set (Azure DataBricks) applies the trained model to a Spark data-frame by using Pandas UDF. The data-frame is the one processed by the previous task.
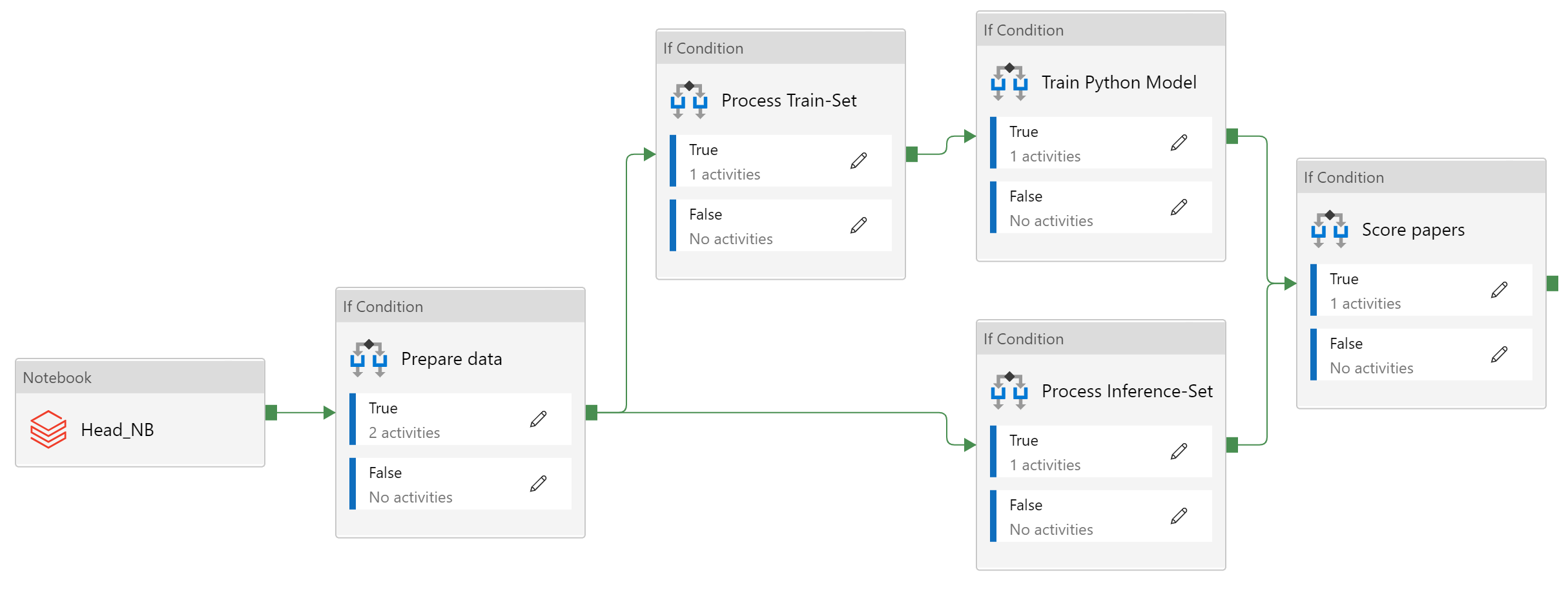
Fig. 2 The Azure DataFactory data-flow implementation, based on Azure ML and Azure DataBricks notebooks tasks. The first task parses arguments and control the condition tasks.
The following use cases drove data pipeline engineering:
- The system will automatically batch run the recommendation pipeline to update EPPI-Reviewer content.
- Since MAG IDs can change between updates, super-users trigger a pipeline that aims to update and automatically re-match records where IDs have changed.
- Super-users can interactively run the system to get their own recommendations.
The ContReview Python package supports all the above activities. To support production data pipelines, the package is stored to an Azure DevOps repository, and automatically delivered via Azure DevOps pipelines. The same package is also used within the experimentation framework, based on Jupyter notebooks.
Inference model
The following sections cover the methods used to prepare raw data, pre-process features, and build models. Performance results are provided and discussed.
Preprocessing
The dataset used for inference comprises both text features and symbolic features. The system pre-process both as explained below. In addition, the training dataset includes a supervised set of relevant reviews for each paper. Training papers and their supervision come from different systems – MAG and EPPI-Reviewer respectively – thus the system integrates them by deduplicating papers identifiers.
Text preprocessing
Different preprocessing steps have been considered for text attributes (i.e., titles and abstracts), by using nltk or spaCy. Specifically, text lemmatization, stop words removal, part-of-speech based filtering have been tested.
The following code snippet demonstrates the different preprocessing options:
def clean_text(self, doc: Doc) -> str: tokens = [] # POS Tags removal if self._pos_to_remove: for token in doc: if token.pos_ not in self._pos_to_remove: tokens.append(token) else: tokens = doc # Remove Numbers if self._remove_numbers: tokens = [ token for token in tokens if not (token.like_num or token.is_currency) ] # Remove Stopwords if self._remove_stopwords: tokens = [token for token in tokens if not token.is_stop] # remove unwanted tokens tokens = [ token for token in tokens if not ( token.is_punct or token.is_space or token.is_quote or token.is_bracket ) ] # Remove empty tokens tokens = [token for token in tokens if token.text.strip() != ""] # Lemmatize if self._lemmatize: text = " ".join([token.lemma_ for token in tokens]) else: text = " ".join([token.text for token in tokens]) if self._remove_special: # Remove non alphabetic characters text = re.sub(r"[^a-zA-Z\']", " ", text) # remove non-Unicode characters text = re.sub(r"[^\x00-\x7F]+", "", text) text = text.lower() return text
For a full example, see this Github Gist.
Feature encoding
In addition to text features, other features are available as MAG relational data (e.g., authors, citations, field of studies). They do not require text preprocessing as they are symbolic – i.e., they correspond to nodes and edges in the knowledge graph.
Several models share a common framework for encoding those features. That is a paper can be represented by a set of vectors, each accounting for a specific feature:
- For textual features (e.g., titles and abstracts), the vector is obtained by Tf-Idf scores.
- For symbolic features (e.g., authors and citations), the vector is obtained by one-hot encoding.
A Scikit-Learn TfIdfVectorizer can conveniently encode both types of features.
Evaluation and results
From a business perspective, the cost associated with false negatives exceeds the one associated with false positives. In fact, a false negative corresponds to a relevant paper lost potentially forever. Instead, a false positive would simply force the user to evaluate a non-relevant paper manually. Thus, the evaluation strategy considers precision with recall as close as possible to 0.95. Recall at 0.95 corresponds to a minimum acceptable level of false negatives.
Models evaluation considers classification performance, interpretability, and scalability. The model based on Tf-Idf over titles and abstracts was selected for the production system. In fact, it is reasonably simple and performed above customer expectations on a production-like test dataset (∼30,000 papers from ∼ 800 reviews). One limitation was that a minimum review size of 40 included papers have been imposed, while some reviews may have fewer papers than this.
Results
Several models have been tested and are briefly covered in this section. Most of the models infer relevance by means of a similarity score between representations of papers. Other approaches have also been tried, such as Machine Learning classifiers trained over textual features and topic models. The following table summarizes the classification performances of the principal of them.
| Model | Precision | Recall |
| Multi-features Probabilistic Model | 0.977 | 0.992 |
| Tf-Idf at the paper level | 0.974 | 0.971 |
| USE (with Deep Average Network) | 0.881 | 0.962 |
| SIF (with gloVe and word2vec trained on PubMed) | 0.843 | 0.951 |
| Sentence-transformers over sciBERT | 0.801 | 0.938 |
| Tf-Idf weighted embeddings | 0.949 | 0.794 |
Table 1 – Different model results on classifying new papers to existing reviews. As precision and recall values depend on a classification threshold, precision for recall at ~95% has been considered.
The multi-features probabilistic model considers the relational nature of data i.e., papers are described by multiple entities (authors, fields of study, words in titles etc.). Membership of papers to reviews is determined statistically, considering the marginal (i.e., per feature and per review) distributions of the similarity scores of papers in the training set.
Specifically, the likelihood for a paper p ∈ P new to be relevant for a review r ∈ R given a set F of features, is calculated in two steps:
- First a local similarity score sf (p, r) is calculated for each feature f in F. That is, sf measures relevance depending only on the feature f. Specifically, local similarity is a function of the cosine distance between p and r, represented by feature f.
- Then, local similarity scores are aggregated to a global similarity score s(p, r), that accounts for global relevance: s(p, r) = aggf∈F sf (p, r), where agg averages the top n (n being a parameter) best performing local similarity scores.
The Tf-Idf model at the paper level infers relevance uniquely on text features. Each paper is represented as a Tf-Idf vector over the concatenation of its title and abstract. Relevance is determined by averaging the pairwise cosine similarities between the representation of a candidate paper and those of the k-neighbor papers in reviews (i.e., the closest k papers by similarity score, where k is a hyperparameter). This model is simple, provides fast training (that must only calculate Tf-Idf values) and achieved competitive performances. It outperformed an alternative method, that compares a paper Tf-Idf representation to a review Tf-Idf representation. Specifically, the latter considers the concatenation of all its papers’ titles and abstracts.
In addition, the following table summarizes classification performance for different text preprocessing techniques, for the Tf-Idf model at the paper level.
| Preprocessing | Precision | Recall |
| Lemmatize, remove numbers and stop-words | 0.974 | 0.971 |
| Remove numbers and stop-words | 0.969 | 0.976 |
| No preprocessing | 0.979 | 0.960 |
| Lemmatize, remove numbers, POS*, stop-words | 0.967 | 0.968 |
| Lemmatize, remove numbers | 0.979 | 0.955 |
| Remove numbers, stop-words, POS* | 0.976 | 0.956 |
Table 2 – Results for different preprocessing techniques for the Tf-Idf model. *POS: Removed certain Part-Of-Speech tags: VERB, ADP, SYM, NUM
Other models have also been evaluated, that either reported non competitive performance or required more effort. These models include topics modeling (based on Latent Dirichlet Allocation), and several multilabel-multiclass classification implementations based on popular models available in Sklearn, fastText, and HuggingFace transformers.
Discussion of results and future work
The greatest contribution to recommendation performance in the initial dataset comes from text features, i.e. titles and abstracts. Moreover, additional features (i.e. authors and fields of study) further improve classification performance. When used to maintain a living map of COVID-19 research however, the citation and fields of study features proved to be more important than abstracts.
Multilabel-Multiclass models, possibly trained over ensembles of features, might be able to learn more complex similarity functions compared to the linear ones used today.
The Tf-Idf model outperformed models using words and sentence embeddings, even with pre-trained transformers. This shouldn’t be a surprise, in fact key phrases are better suited than general semantics to represent domain-specific content. Key phrases are well captured by symbolic representations, like the ones employed by the Tf-Idf model. On the other hand, general semantics are well captured by pre-trained embeddings. That is, discriminating relevance is a matter of capturing the right key phrases rather than a general sense of semantics.
Indeed, re-training the base embedding model over a domain-specific corpus might help to improve the performance of this family of models. However, this has not been tried as yet, mostly because it is computationally expensive and, depending on the size of reviews, a large enough corpus might be unavailable.
In addition, symbolic based approaches generalize better across several different domain areas. However, having to re-train a dedicated embedding model for every domain would probably be a too demanding requirement.
Acknowledgements
This work was a team effort, and I would like to thank the Microsoft (MSFT) and UCL teams for the great collaborative experience. Here are the main contributors for this engagement: Omri Mendels (MSFT), Paolo Tenti (MSFT), Nava Vaisman Levy (MSFT), Katya Mustafina (MSFT), Ehsan Zare Borzeshi (MSFT), James Thomas (UCL), Sergio Graziosi (UCL), Patrick O’Driscoll (UCL), Ian Shemilt (UCL).
.